
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 데이터 분석
- 혼공
- 포스코 아카데미
- 포스코 청년
- 삼성SDS
- 혼공머신
- 브라이틱스 서포터즈
- Brightics를 이용한 분석
- Brigthics
- 노코드AI
- 브라이틱스
- Brigthics를 이용한 분석
- 캐글
- Brigthics Studio
- 모델링
- 삼성SDS Brigthics
- 데이터분석
- 혼공머신러닝딥러닝
- 삼성 SDS
- Brightics Studio
- 영상제작기
- 직원 이직률
- 개인 의료비 예측
- Brightics
- 직원 이직여부
- 삼성 SDS Brigthics
- 삼성SDS Brightics
- 추천시스템
- 팀 분석
- 혼공학습단
- Today
- Total
데이터사이언스 기록기📚
[혼공10기/혼공 머신러닝 + 딥러닝] 5주차_Ch.6 비지도 학습 본문
📌 Ch6. 비지도 학습
🖊️ Ch.6-1) 군집 알고리즘
✔️비지도 학습과 군집
- 비지도학습 : 타깃이 없을 때 사용하는 머신러닝 알고리즘
- 군집 : 비슷한 샘플끼리 그룹으로 모으는 작업
- 클러스터 : 군집 알고리즘에서 만든 그룹
✔️과일분류 실습(비지도 학습)
1) 과일 사진 데이터 준비하기
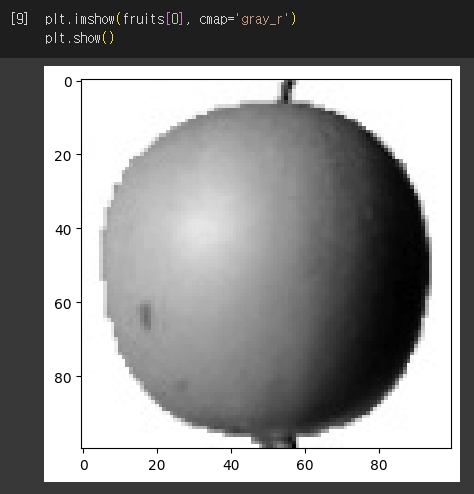
- 흑백 이미지는 바탕 밝음, 물체 어둡지만 반대인 이유
- 사진으로 찍은 이미지 → 넘파이 변환 시, 색 반전
- 컴퓨터가 255에 밝은 바탕에 집중(출력을 위한 곱셈, 덧셈을 위해)할 것이라서 반전시킴

! : 리눅스 셀 명령어
wget : 원격 주소에서 데이터 다운로드하여 저장
-O : 저장할 파일 이름 지정



- subplots(행, 열) : 여러 개의 그래프를 배열처럼 쌓아서 나타내기
- axs : 서브그래프를 담고 있는 배열

2) 픽셀값 분석하기
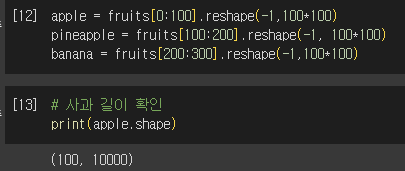
- 사과, 파인애플, 바나나로 각 100개씩 나누기
- 100*100 이미지 펼쳐 10,000인 1차원 배열 만들기 → 이미지 출력 어려움, 배열 계산 시 편리
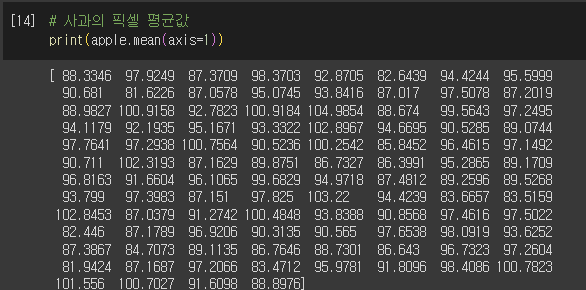
①샘플의 픽셀 평균값
- 바나나 : 40 이하
- 사과, 파인애플 : 90~100
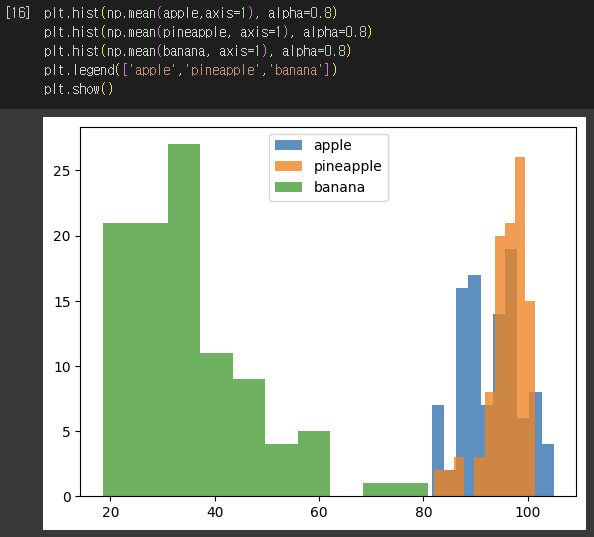
② 픽셀 평균값 비교
- 과일별 행의 픽셀값 성향
- 사과 : 오른쪽으로 갈 수록 증가
- 파인애플 : 고르게 분포
- 바나나 : 중앙값이 높음
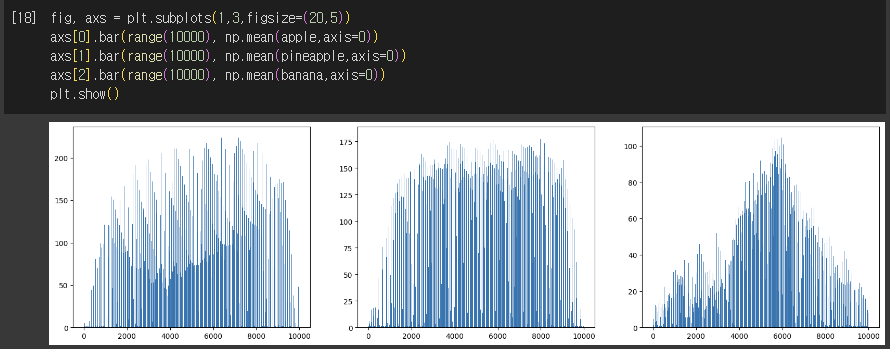
- 평균 과일의 이미지

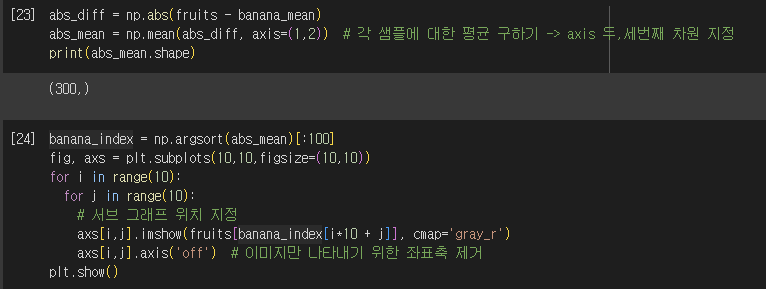
3) 평균값과 가까운 사진 고르기
- np.argsort() : 작은 것에서 큰 순서로 나열한 배열의 인덱스 반환


✔️확인문제 2번
- banana_mean과 비슷한 100장의 사진을 출력할 수 있는지?
-> 출력할 수 없다

🖊️ Ch.6-2) k-평균
✔️k-평균 알고리즘
- k-평균 군집 알고리즘(클러스터 중심, 센트로이드) : k개의 군집이 k개의 평균을 기준으로 나타냄
- 작동방식
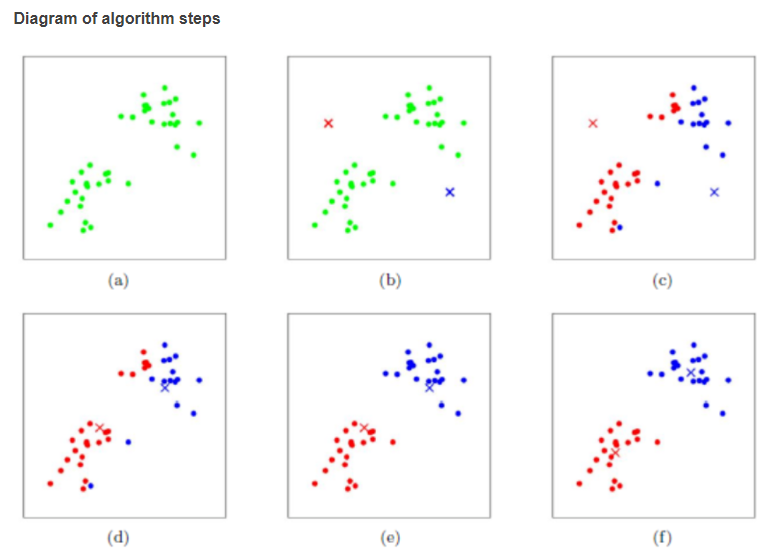
- 랜덤으로 k개의 클러스터 중심을 정함
- 각 샘플 중, 가장 가까운 중심을 찾아 해당 클러스터의 샘플로 들어감
- 클러스터 내 샘플의 평균으로 다시 중심 조정
- 클러스터 중심이 변화 없을 때까지 반복
- 특징
- 클러스터 중심을 이용하여 데이터셋을 저차원으로 이용가능(10000 → 3)
✔️최적의 K 찾기
- 엘보우 방법
- 이너셔의 변화를 관찰하여 최적의 클러스터 개수 찾기
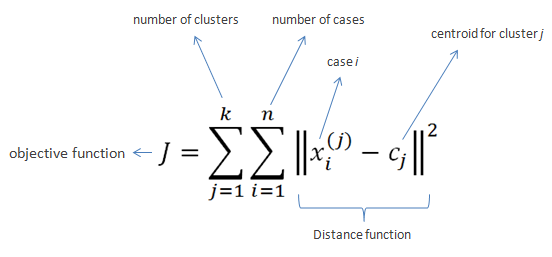
- 이너셔 : 클러스터 전체 합((클러스터 중심 - 클러스터 내 샘플)**2) → 클러스터에 속한 샘플이 얼마나 가깝게 모여있는지 나타내는 값
- 클러스터 개수↑, 클러스터 개개의 크기↓, 이너셔↓
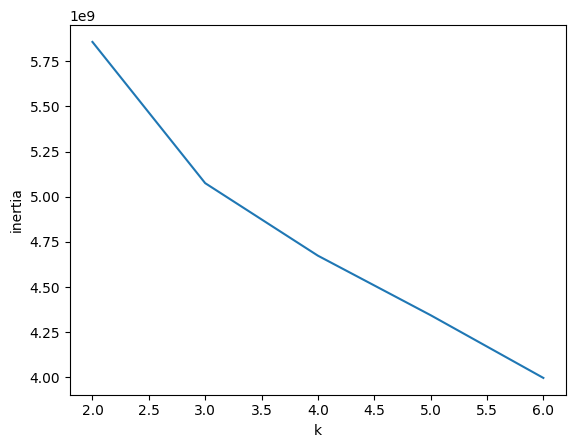
- 이너셔가 꺾이는 지점 : 클러스터 개수를 늘려도 클러스터에 밀집된 정도가 크게 개선되지 않음
- 실습
- inertia_ : 자동으로 이너셔를 계산해주는 속성

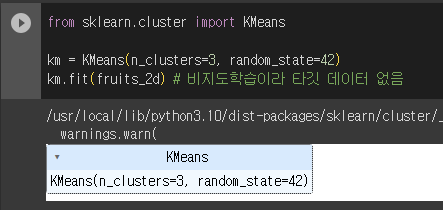
✔️k-means(k-평균 알고리즘) 실습
1) 데이터 불러오기

2) k-means 알고리즘 사용
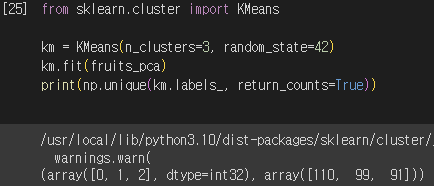
- n_cluster : 클러스터 개수 지정
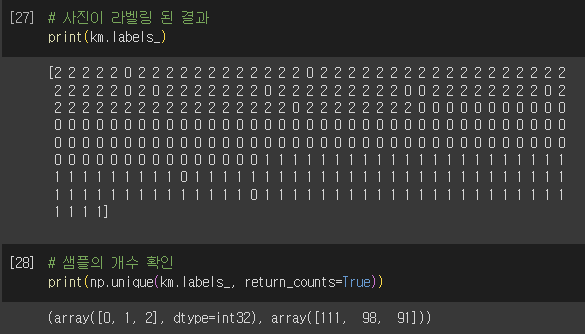
3) 결과
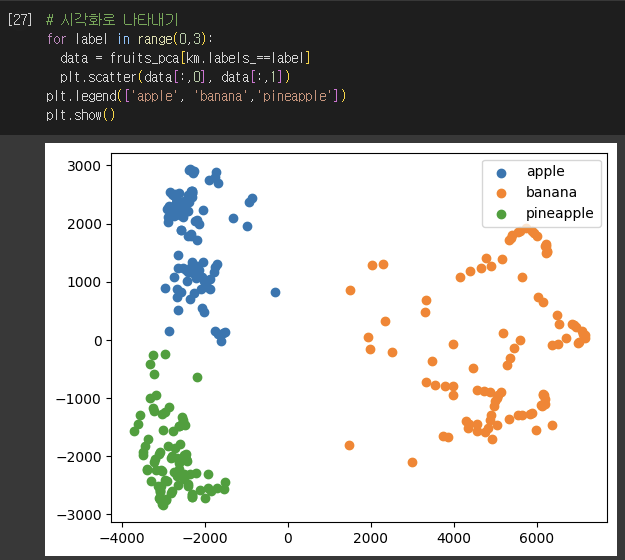
- labels == 0에 3개의 과일이 섞여있어 완벽하게 구분하진 못함







- K-means가 찾은 클러스터 중심의 과일 모양
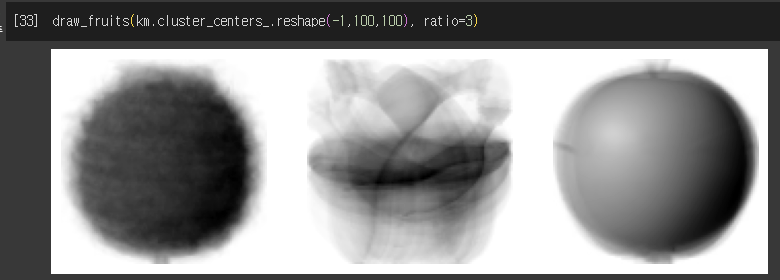
- 클러스터까지의 거리 및 클러스터 예측
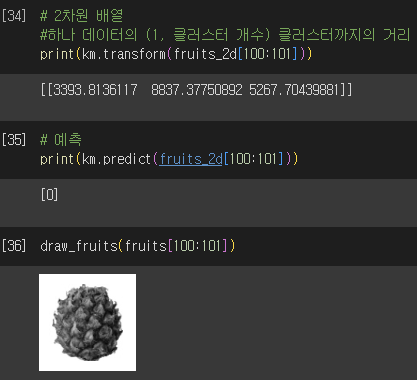
🖊️ Ch.6-3) 주성분 분석
✔️차원과 차원축소
- 차원 : 데이터가 가진 속성
- 예시) 하나의 과일 사진에 있는 10,000개의 픽셀이 차원에 해당
- 차원축소 : 데이터를 가장 잘 나타내는 일부 특성 선택
- 특징
- 데이터 크기 줄임
- 지도 학습 모델 성능 향상
- 줄어든 차원 → 원본차원으로 손실을 최대한 줄이며 복원할 수 있음
- 대표적인 알고리즘 : 주성분 분석(PCA)
✔️주성분 분석이란?
- 주성분 분석(PCA) : 데이터에 있는 분산이 큰 방향(데이터를 표현하는 벡터)을 찾는 것
- 하단의 데이터 특성 : x1, x2
- 분산의 방향(주성분 벡터) : 오른쪽 위 대각선
사이킷런의 PCA 모델 특징
- 자동으로 특성마다 평균값을 빼서 원점에 맞춤
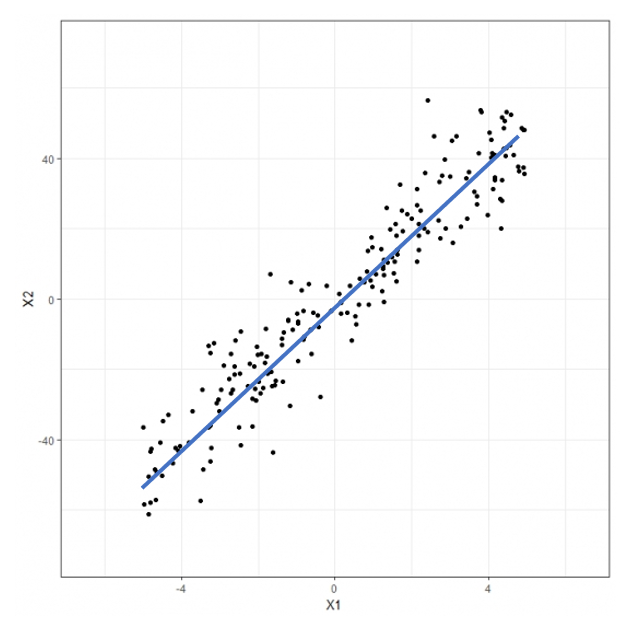
- 주성분 벡터 : 원본 데이터에 있는 큰 방향으로, 분산이 큰 방향을 찾는 것
- 특징
- 주성분 벡터 원소 개수 : 원본 데이터셋에 있는 특성 개수
- 원본 데이터 → 주성분을 사용하여 차원을 줄일 수 있음(Ex. 원본 (4,2) → 주성분 투영(4,5))
- 주성분 = 원본 차원
- 주성분으로 바꾼 데이터는 차원이 줄어든다
- 원본 데이터 → 주성분 투영하면 원본이 가지고 있는 특징을 잘 나타낼 수 있음
- 주성분은 원본 특성의 개수 만큼 찾을 수 있음
✔️PCA 실습
1) 데이터 로드
2) PCA 학습
- n_components : 주성분의 개수 지정
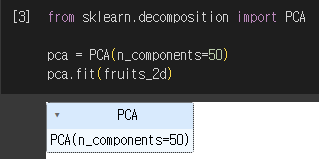
3) PCA 결과
- components_ : PCA가 찾은 주성분 (주성분 개수, 원본 데이터 특성 개수)
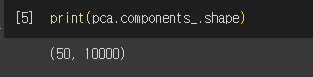
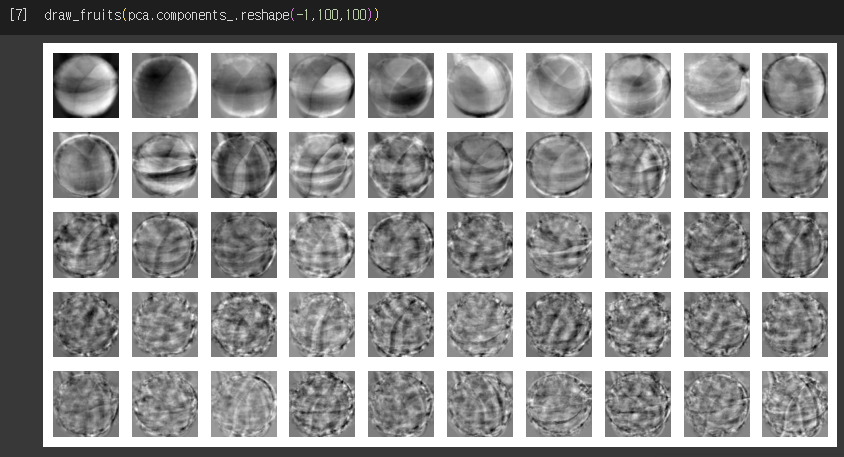
- 원본 데이터에서 가장 분산이 큰 방향을 순서대로 나타냄
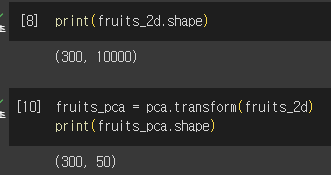
- 원본데이터를 주성분에 투영(transform 이용)
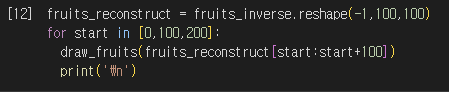
4) 원본 데이터 재구성
- inverse_transform 사용




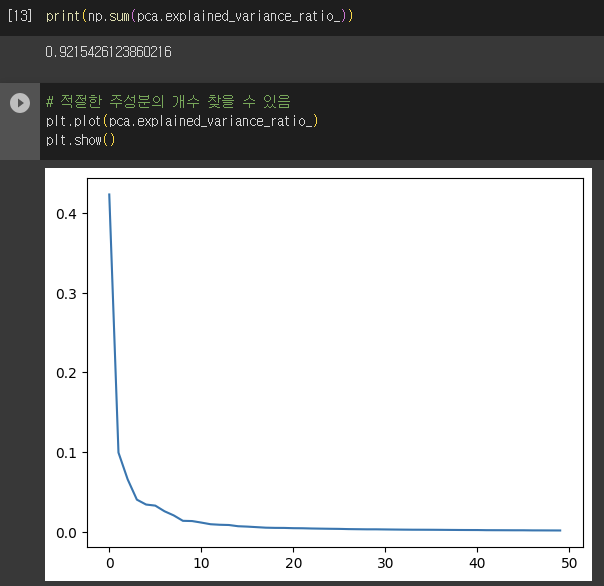
- 설명된 분산(주성분이 원본 데이터를 얼마나 잘 나타내는지 기록한 값)
- explained_variance_ratio : 각 주성분의 설명된 분산 비율 (분산비율을 모두 더하면 50개 주성분 총 분산 비율 얻을 수 있음)
✔️PCA로 차원 축소 후, 학습 모델 실습(3개의 과일 사진 분류)
1) 로지스틱 회귀로 훈련
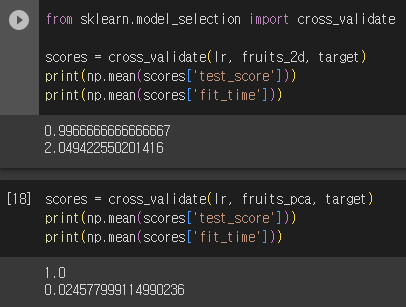
- 원본 데이터와 pca 데이터 비교
- PCA 차원 축소 시, 저장공간↓, 훈련속도↓
- pca 설명된 분산의 비율 모델로 주성분 개수 찾기

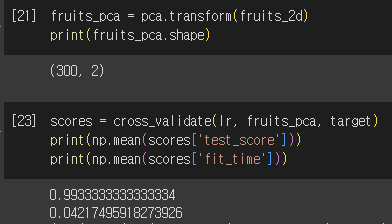
2) K-means 로 훈련

'대외활동 > 혼공10기 - 머신러닝, 딥러닝' 카테고리의 다른 글
| [혼공10기/혼공 머신러닝 + 딥러닝] 6주차_Ch.7 딥러닝을 시작합니다! (0) | 2023.08.20 |
|---|---|
| [혼공 10기/혼공 머신러닝+딥러닝] 4주차_Ch.5 트리 알고리즘 (0) | 2023.08.01 |
| [혼공 10기/혼공 머신러닝+딥러닝] 3주차_Ch.4 다양한 분류 알고리즘 (0) | 2023.07.23 |
| [혼공 10기/혼공 머신러닝+딥러닝] 2주차_Ch.3 회귀 알고리즘과 모델 규제 (0) | 2023.07.16 |
| [혼공 10기/혼공 머신러닝+딥러닝] 1주차_Ch.2 데이터 다루기 (0) | 2023.07.07 |



