
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 브라이틱스
- Brigthics를 이용한 분석
- 삼성SDS
- 혼공학습단
- 영상제작기
- 포스코 아카데미
- 데이터 분석
- 노코드AI
- 혼공머신
- Brightics Studio
- 추천시스템
- 혼공머신러닝딥러닝
- 포스코 청년
- 캐글
- 브라이틱스 서포터즈
- 삼성SDS Brigthics
- 삼성 SDS Brigthics
- 개인 의료비 예측
- Brightics
- 모델링
- Brigthics
- 삼성SDS Brightics
- 데이터분석
- 직원 이직률
- 혼공
- 팀 분석
- Brightics를 이용한 분석
- 직원 이직여부
- Brigthics Studio
- 삼성 SDS
- Today
- Total
데이터사이언스 기록기📚
[혼공 10기/혼공 머신러닝+딥러닝] 1주차_Ch.2 데이터 다루기 본문
📌 Ch2. 데이터 다루기
🖊️ Ch.2-1) 훈련 세트와 테스트 세트
✔️지도학습, 비지도학습
- 지도학습 : 정답이 있는 데이터를 학습시키는 것
- 특징 : 구분하기 위한 정답 도출
- 비지도학습 : 정답이 없는 데이터를 학습시키는 것
- 특징 : 데이터 파악 및 변형
+) 강화학습 : 알고리즘이 행동한 결과로 얻은 보상으로 학습
✔️훈련 세트와 테스트 세트
- 머신러닝 알고리즘 성능 평가
: 훈련 데이터(Train)와 테스트 데이터(Test) 달라야 함 → 이유 : 연습과 실전이 달라야 올바른 능력 평가 가능
① 테스트를 위한 다른 데이터 준비
② 준비된 데이터 중 일부 떼어 내서 활용
- 훈련 세트, 테스트 세트 구분
- 훈련 세트(전체 데이터 70~80%)
- 테스트 세트 (전체 데이터 20~30%)
✔️샘플링 편향
- 샘플링 편향(Sampling bias) : Train set, Test set에 정답이 골고루 섞이지 않은 경우
→ Train set, Test set으로 나눌 때, 편향되지 않도록 샘플을 섞어서 생성해야 함
✔️실습
1) 데이터 샘플 생성

2) train, test 샘플 나누기

3) 모델 생성, 훈련, 평가

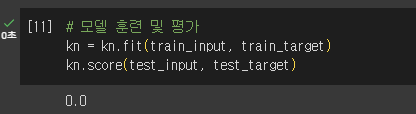
→ train, test가 샘플링 편향으로 올바르게 나누어 지지 않음!
→ 데이터를 무작위로 섞어 샘플링 편향 없애기
4) 데이터 무작위 생성
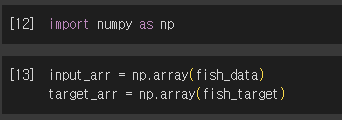




5) 새로운 train, test set으로 분류

🖊️ Ch.2-2) 데이터 전처리
✔️실습
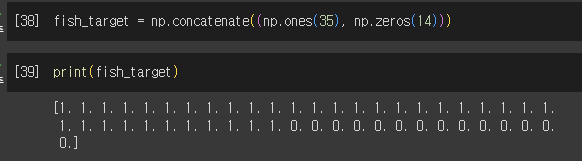
1) Data 만들기
- column_stack() : 전달받은 리스트 연결. 열 형식으로 묶임


- concatenate() : 2개의 데이터를 1차원 형태로 붙이는 것
2) train, test 나누기
- train_test_split() : train,test로 나누어 줌. 기본적으로 25%를 테스트로 사용

- train_test_split(stratify = ) : 클래스 비율에 맞게 데이터 나누어 줌 (데이터 양 적을 때 유용)

3) (잘못된 방법) 데이터 훈련시키기




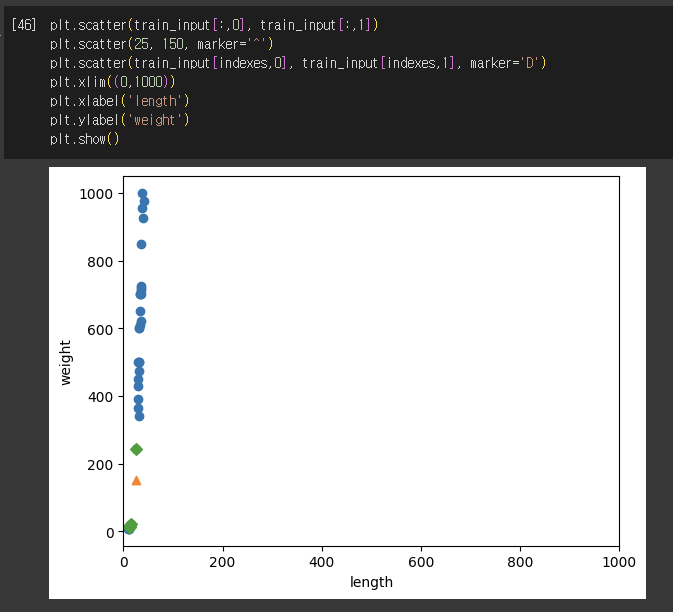
4) 데이터 전처리
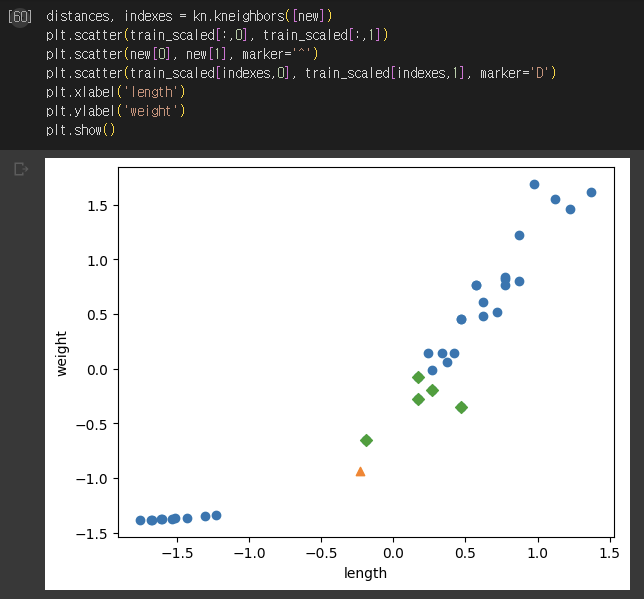
- 표준점수로 샘플간의 거리를 일정한 기준으로 맞추기



5) 데이터 전처리 후 훈련

'대외활동 > 혼공10기 - 머신러닝, 딥러닝' 카테고리의 다른 글
| [혼공10기/혼공 머신러닝 + 딥러닝] 5주차_Ch.6 비지도 학습 (0) | 2023.08.08 |
|---|---|
| [혼공 10기/혼공 머신러닝+딥러닝] 4주차_Ch.5 트리 알고리즘 (0) | 2023.08.01 |
| [혼공 10기/혼공 머신러닝+딥러닝] 3주차_Ch.4 다양한 분류 알고리즘 (0) | 2023.07.23 |
| [혼공 10기/혼공 머신러닝+딥러닝] 2주차_Ch.3 회귀 알고리즘과 모델 규제 (0) | 2023.07.16 |
| [혼공 10기/혼공 머신러닝+딥러닝] 1주차_Ch.1 나의 첫 머신러닝 (0) | 2023.07.03 |



