
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Brigthics를 이용한 분석
- 노코드AI
- 혼공
- Brightics Studio
- 삼성 SDS
- 직원 이직여부
- 팀 분석
- Brightics를 이용한 분석
- 삼성SDS Brigthics
- 포스코 청년
- 포스코 아카데미
- 직원 이직률
- 개인 의료비 예측
- 데이터 분석
- 브라이틱스 서포터즈
- 삼성SDS Brightics
- 브라이틱스
- 삼성 SDS Brigthics
- 데이터분석
- 삼성SDS
- 영상제작기
- Brigthics Studio
- Brigthics
- Brightics
- 혼공학습단
- 혼공머신러닝딥러닝
- 모델링
- 추천시스템
- 혼공머신
- 캐글
- Today
- Total
데이터사이언스 기록기📚
[혼공 10기/혼공 머신러닝+딥러닝] 4주차_Ch.5 트리 알고리즘 본문
📌 Ch5. 트리 알고리즘
🖊️ Ch.5-1) 결정 트리
✔️(복습) 로지스틱 회귀로 와인 분류 실습
1) 데이터 불러오기 및 정보 확인
- info() : 각 열의 데이터 타입, 누락된 데이터 확인
- describe() : 열에 대한 통계. 개수,평균, 최소, 최대, 4분위수, 표준편차 제공


2) 데이터 나누기

3) 데이터 전처리
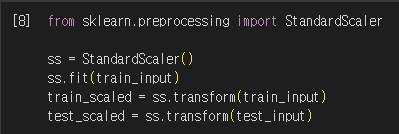
4) 로지스틱 회귀로 학습

✔️결정 트리
- 결정 트리 : 데이터를 잘 나눌 수 있는 질문을 추가해서 분류 정확도를 높이는 모델
- 노드 : 훈련 데이터의 특성을 나누는 질문
- 루트노드 : 가장 상위 노드(루트노드는 1개)
- 리프노드 : 가장 하위 노드(리프노드는 다수 존재)
- 결정트리 예측 : 리프노드에서 가장 많은 클래스 → 예측 클래스
- 트리 알고리즘 장점 : 특성값의 스케일이 계산에 영향 미치지 않음 → 표준화 전처리 할 필요 없음
- 매개변수 criterion : 노드에서 데이터를 분할하는 기준을 정하는 것
- gini(지니 불순도) : 1 - (음성 클래스 비율**2 + 양성 클래스 비율**2)
- entropy(엔트로피 불순도) : - 음성 클래스 비율 * log2(음성 클래스 비율) - 양성클래스 비율 * log2(양성 클래스 비율)


- 정보이득 : 부모와 자식 노드 사이의 불순도 차이
- 정보 이득이 최대가 되도록 노드 분할(노드 순수하게 나눌수록 정보 이득 ↑)
- 마지막 노드 클래스 비율을 보고 예측 만듦
- 가지치기 : 트리의 깊이를 지정하여 더 자라지 않도록 하는 것 → 무한 성장을 막아 테스트 결과가 더 좋게 나옴
✔️결정 트리 실습
1) 트리모델로 훈련 및 결과물 보기


2) 트리 깊이 제한
- max_depth : 루트노드 제외한 깊이
- filled : 클래스에 맞게 노드 색 칠하기
- feature_name : 특성의 이름 전달하여 어떤 특성으로 나누는지 이해할 수 있음
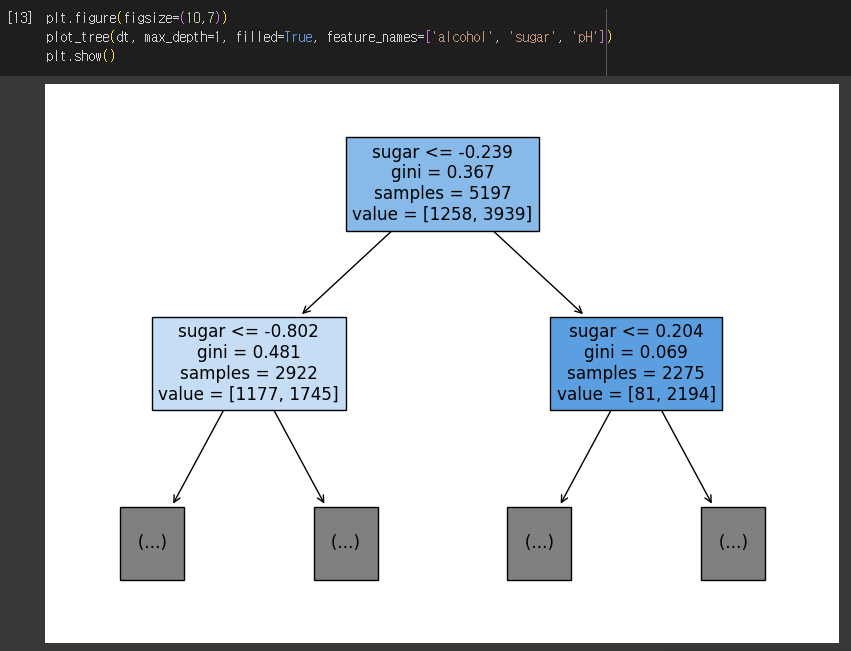
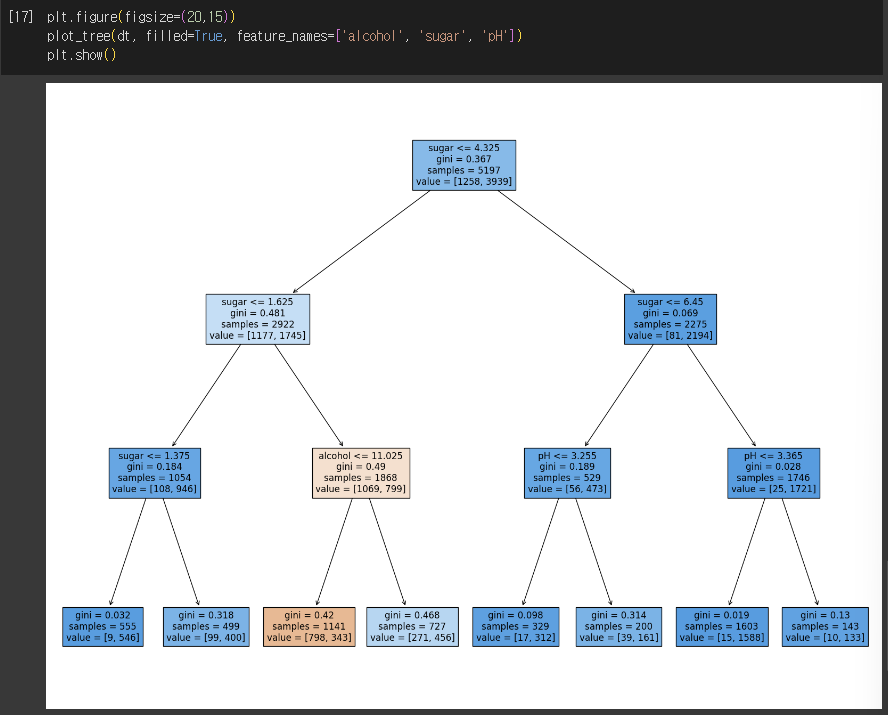
3) 가지치기 적용


4) 표준화 전처리 하지 않은 데이터로 훈련
- feature_importances_ : 어떤 특성이 가장 유용한지 나타내는 특성 중요도


🖊️ Ch.5-2) 교차 검증과 그리드 서치
✔️검증 세트
- 검증 세트 : 훈련세트를 나누어 모델이 과소/과대 적합인지 판단하는 세트

- 훈련세트, 검증세트, 테스트세트로 나눈 훈련 모델 실습


✔️교차 검증
- 교차 검증 : 검증 세트를 떼어 내어 평가하는 과정을 여러번 반복
- K-폴드 교차검증 : 훈련세트를 K개로 나누어 교차검증 수행
- 각각의 교차검증을 평균내어 하나의 검증점수로 나타냄

- cross_validate(평가할 모델 객체, 전체 X, 전체 Y ) : 교차검증 함수
- 분할기(StratifiedKFold) : 교차검증 시 훈련세트 섞는 경우


✔️하이퍼파라미터 튜닝
- 하이퍼파라미터 : 사용자가 지정하는 파라미터
- 하이퍼파라미터 튜닝
- 매개변수가 2개 이상일 때 : 매개변수 전체를 동시에 바꿔가며 최적의 값을 찾아야 함(하나 고정하고 다른 하나 값 찾을 수 없음. 값이 바뀌면 최적값도 바뀜)
- GridSearchCV : 하이퍼파라미터 탐색과 교차검증을 한 번에 수행
- 교차검증 시, 최적의 하이퍼파라미터를 찾으면 전체 훈련세트로 모델을 다시 만들어야 함
- 과정 : 탐색 매개변수 지정 → 그리드 서치 수행, 최상의 매개변수 조합 찾기(그리드 서치 객체에 저장) → 최상의 매개변수 조함을 전체 훈련세트 이용하여 최종 모델 훈련(그리드 서치 객체에 저장)

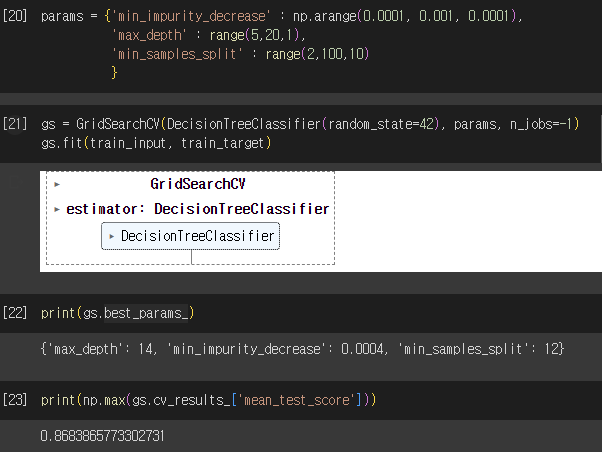
- 랜덤서치 : 매개변수를 샘플링 할 수 있는 확률분포 객체 전달

🖊️ Ch.5-3) 트리의 앙상블
✔️랜덤 포레스트
- 앙상블 : 결정트리 기반으로 만들어졌으며, 여러개의 트리기반 모델을 사용.
- 랜덤 포레스트 : 결정 트리를 랜덤하게 만들어 결정 트리의 숲을 만드는 것. 앙상블 학습에 포함
- 랜덤 포레스트 특징
- 데이터 생성(부트스트랩 샘플) : 각 트리를 훈련하기 위한 데이터를 랜덤으로 생성. 단, 샘플 중복 추출 가능.
- 특성 선택 : (분류) 각 노드 분할 시, 전체 특성 중 일부 특성을 무작위로 고름 → 이 중 최선의 분할을 찾음(보통은 특성개수의 제곱근)
(회귀) 전체 특성 사용 - 예측 : (분류) 각 트리의 클래스별 확률 평균 → 가장 높은 확률가진 클래스를 예측으로 삼음
(회귀) 각 트리의 예측을 평균 - 특징1 : 랜덤 샘플과 특성 이용 → 하나의 특성에 과도하게 집중하지 않음, 많은 특성이 훈련에 기여 →훈련 세트 과대적합을 막음, 안정적인 성능 얻을 수 있음
- 특징2 : OOB 샘플(부트스트랩 샘플에 포함되지 않은 샘플)로 훈련 → 검증 세트 역할
✔️랜덤 포레스트 실습
1) 데이터 분할

2) 교차검증 및 모델 훈련
- return_train_score = True : 검증 점수와 훈련 세트 점수도 같이 반환 → 과대적합 파악 시 용이

3) 특성 중요도 출력

4) OOB 샘플 평가점수 출력

✔️엑스트라 트리
- 랜덤 포레스트와 매우 유사
- 엑스트라 트리
- 각 결정트리 만들 시, 전체 훈련 세트 사용 (부트스트랩 샘플 사용하지 않음)
- 노드 분할 시, 무작위 분할
- splitter = 'random' 설정
- 효과 : 앙상블로 과대적합 막음, 검증 세트 점수 높임
- 장점 : 랜덤 노드 분할로 빠른 계산 속도
- 단점 : 무작위성이 커 랜덤 포레스트보다 더 많은 결정 트리 훈련
- 실습

✔️그레디언트 부스팅
- 그레디언트 부스팅 : 깊이가 얕은 결정 트리 사용하여 이전 트리의 오차 보완하는 방식으로 앙상블
- 특징 : 경사하강법을 사용하여 트리를 앙상블에 추가 , 랜덤 포레스트보다 일부 특성에 더 집중
- 장점 : 트리 개수를 늘려도 과대적합에 강함, 높은 일반화 성능
- 매개변수 subsample : 1보다 작으면 훈련세트 일부 사용. 확률적 경사 하강법 or 미니배치 경사하강법과 유사

✔️히스토그램 기반 그레디언트 부스팅
- 히스토그램 기반 그레디언트 부스팅 : 입력 특성을 256개 구간으로 나눔(노드 분할 시, 최적의 분할 빨리 찾을 수 있음)
- 특징
- 정형 데이터 머신러닝 알고리즘 중 가장 인기 많음
- 입력에 누락된 특성이 있어도 따로 전처리 할 필요 없음
- 기본 매개변수에서 안정적인 성능을 얻을 수 있음
- 아직 테스트 과정에 있음!
- 실습
- permutation_importance() : 특성을 하나씩 랜덤하게 섞어서 모델 성능이 변화하는지 관찰하여 어느 특성이 중요한지 계산

- 히스토그램 기반 그레디언트 부스팅 유사한 알고리즘
- XGB에서 tree_method = 'hist' 지정

- LightGBM

'대외활동 > 혼공10기 - 머신러닝, 딥러닝' 카테고리의 다른 글
| [혼공10기/혼공 머신러닝 + 딥러닝] 6주차_Ch.7 딥러닝을 시작합니다! (0) | 2023.08.20 |
|---|---|
| [혼공10기/혼공 머신러닝 + 딥러닝] 5주차_Ch.6 비지도 학습 (0) | 2023.08.08 |
| [혼공 10기/혼공 머신러닝+딥러닝] 3주차_Ch.4 다양한 분류 알고리즘 (0) | 2023.07.23 |
| [혼공 10기/혼공 머신러닝+딥러닝] 2주차_Ch.3 회귀 알고리즘과 모델 규제 (0) | 2023.07.16 |
| [혼공 10기/혼공 머신러닝+딥러닝] 1주차_Ch.2 데이터 다루기 (0) | 2023.07.07 |



