
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Brigthics를 이용한 분석
- 포스코 아카데미
- 혼공학습단
- 직원 이직률
- 추천시스템
- 포스코 청년
- 삼성 SDS Brigthics
- 데이터 분석
- 개인 의료비 예측
- Brightics를 이용한 분석
- 캐글
- Brigthics
- 혼공머신러닝딥러닝
- 팀 분석
- 브라이틱스
- 영상제작기
- Brigthics Studio
- 삼성SDS Brigthics
- 모델링
- Brightics
- 브라이틱스 서포터즈
- 삼성SDS
- 삼성SDS Brightics
- 혼공머신
- 데이터분석
- 노코드AI
- Brightics Studio
- 직원 이직여부
- 혼공
- 삼성 SDS
- Today
- Total
데이터사이언스 기록기📚
[삼성 SDS Brightics 서포터즈] #17_개인 프로젝트_노코드 AI 오픈소스 Brightics Studio로 분석_직원 이직률⑤ 데이터 전처리, 모델링 본문
[삼성 SDS Brightics 서포터즈] #17_개인 프로젝트_노코드 AI 오픈소스 Brightics Studio로 분석_직원 이직률⑤ 데이터 전처리, 모델링
syunze 2022. 11. 1. 19:42안녕하세요!!
벌써 17번째 포스팅으로 돌아왔습니다!
이제 서포터즈 포스팅도 얼마 남지 않았는데요ㅠㅠ
끝까지!! 열심히 포스팅해보겠습니다!
오늘은 저번 포스팅의 오류 수정과
하이퍼파라미터튜닝 된 모델링을 진행해보려합니다!
사실 저번 포스팅의 오류와 개선 방향을
멘토님께서 알려주셔서
해당 방법으로 포스팅을 진행해보도록 하겠습니다.
🔽이전 포스팅이 궁금하시면 아래 링크를 클릭해주세요!🔽
[삼성 SDS Brightics 서포터즈] #16_개인 프로젝트_노코드 AI 오픈소스 Brightics Studio로 분석_직원 이직
안녕하세요~! 16번째 포스팅으로 돌아왔습니다. 이번 포스팅에서는 데이터 전처리 부분인 라벨 인코딩, 원핫인코딩을 진행하고 하이퍼파라미터를 조정하지 않은 기본 모델링을 진행해보고자 합
subinze.tistory.com
그럼 포스팅, 시작해보겠습니다!
1. 이전 포스팅 오류 수정
이전 포스팅에
RF,XGB,AdaBoost의 Prediction에서
Test Data를 사용하지 않고 Train Data를 사용하였습니다ㅠㅠ
그래서 해당 오류를 수정 후, 진행해보겠습니다.
1-1. Random Forest

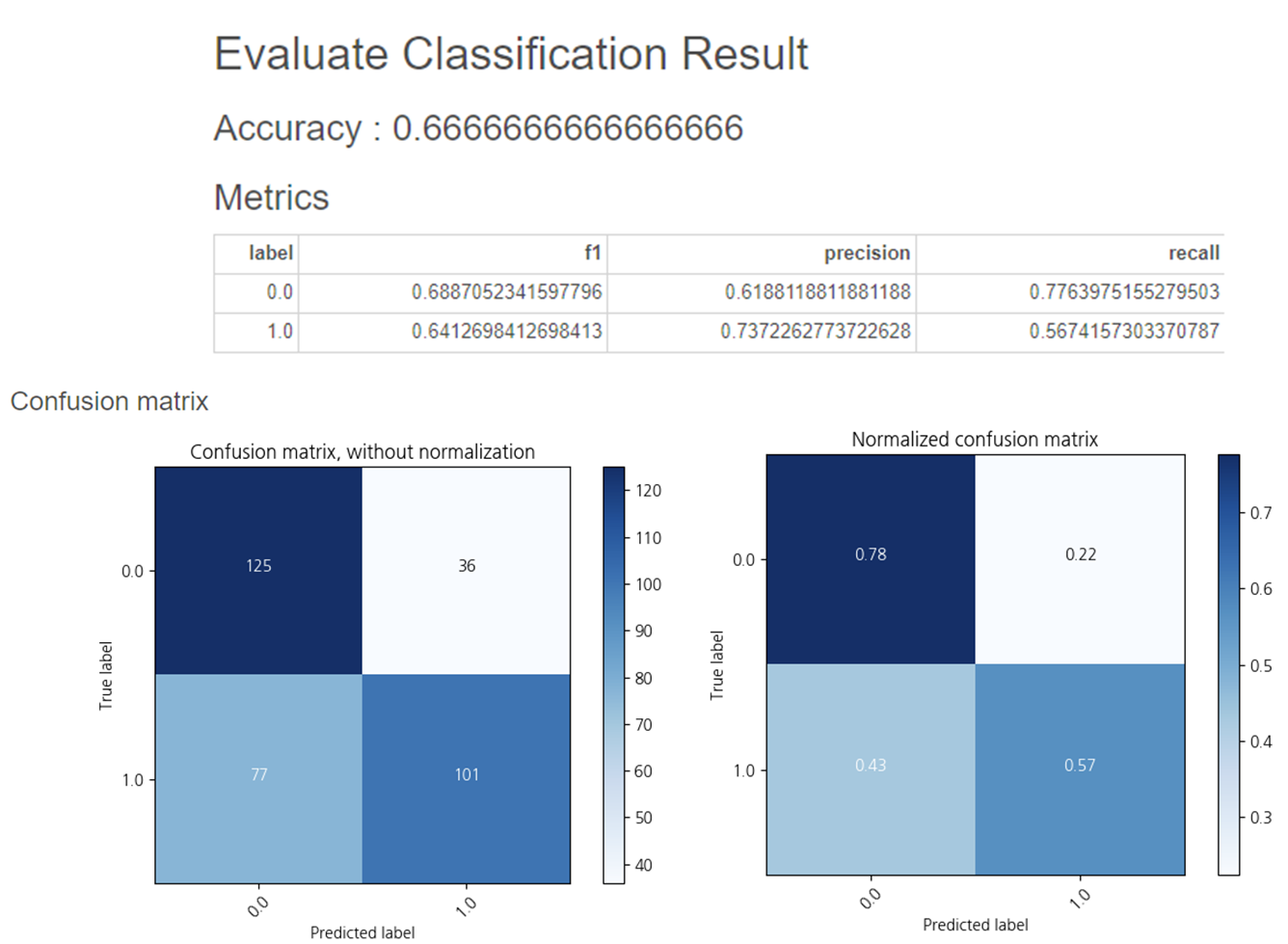
Input Data를 test_table로 수정하여 결과를 내보았더니,
정확도는 0.666이 나왔습니다.
정확도가 다른 모델보다 높다면
Input Data에 올바른 데이터가 있는지 꼭!!!확인해주세요!
1-2. XGBoost
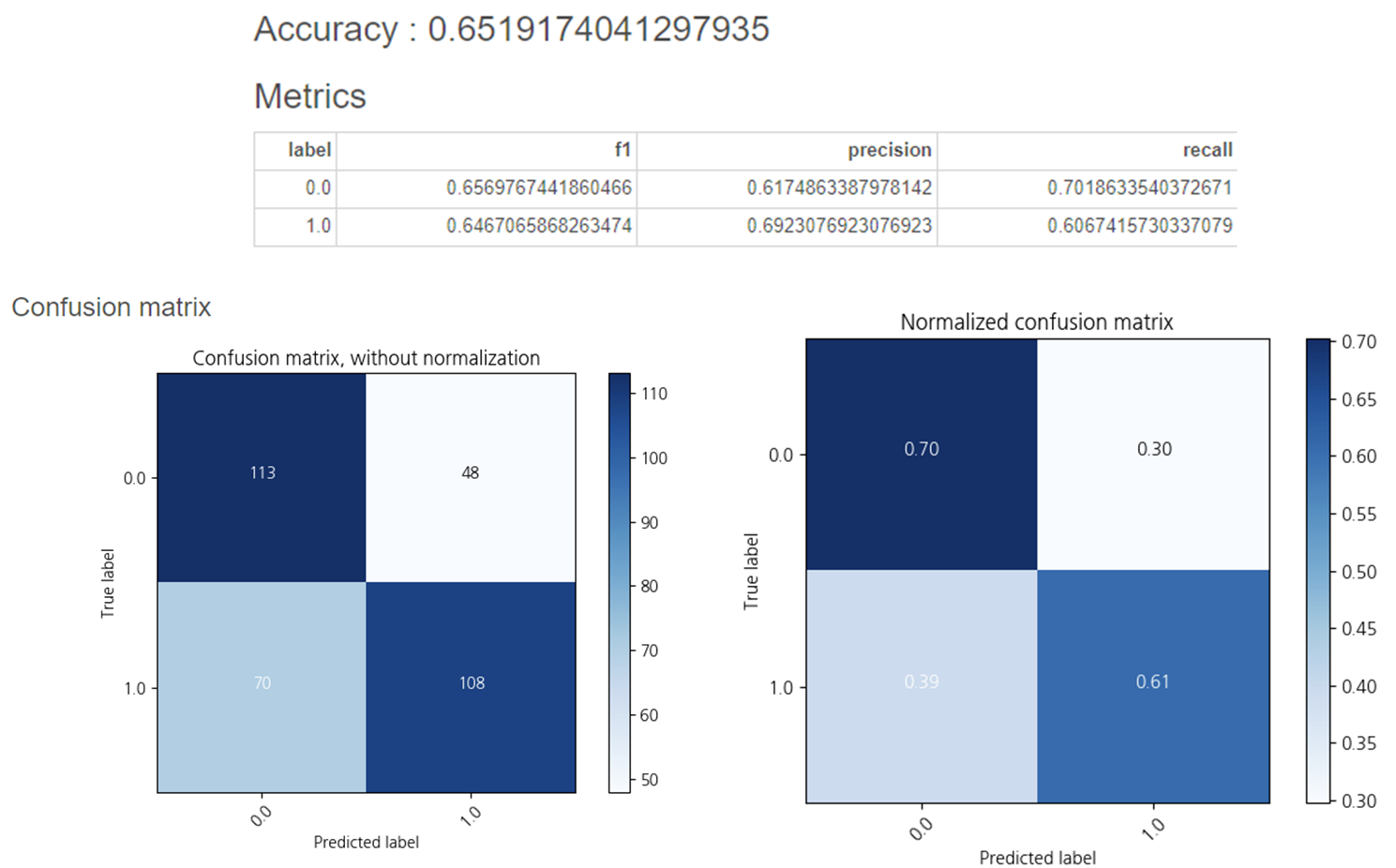
XGBoost의 정확도는 0.651임을 확인할 수 있었습니다.
1-3. AdaBoost

AdaBoost의 정확도는 0.625임을 확인할 수 있었습니다.
1-4. 종합
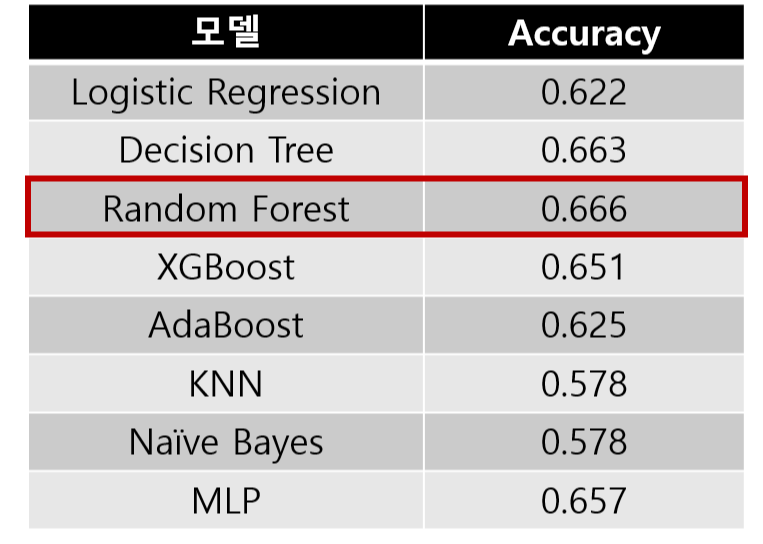
파라미터 수정 전, 모델별 정확도는 다음과 같습니다.
Random Forest가 0.666으로 가장 높은 것을 확인할 수 있었습니다.
2. 하이퍼파라미터 조정
1-4에서 보았던 종합에서 상위 4개인
Random Forest, Decision Tree, MLP, XGBoost로만
하이퍼파라미터를 조정해보았습니다.
2-1. Random Forest
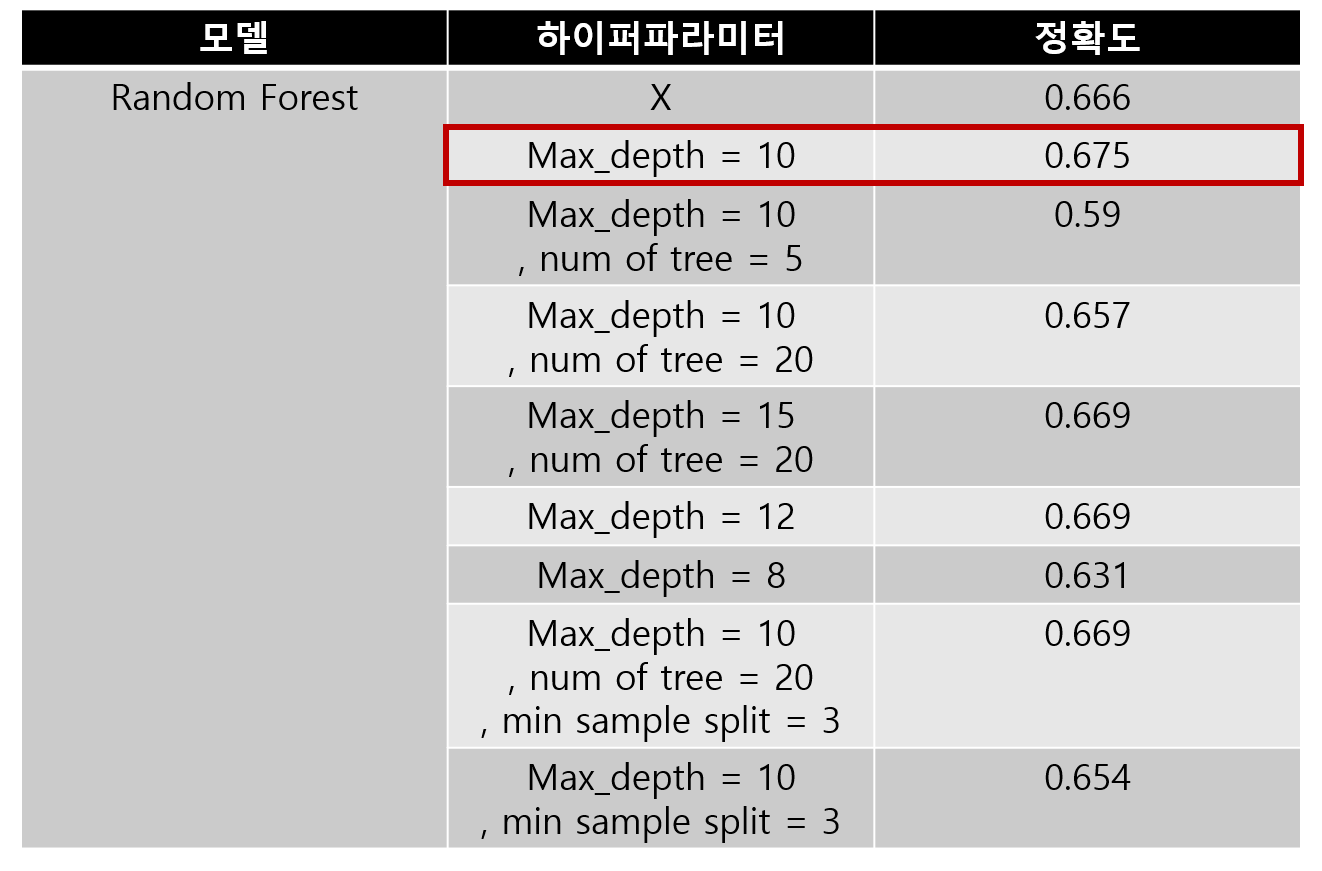
Random Forest는 max_depth = 10 하이퍼파라미터를 이용하여
0.675의 높은 정확도를 얻을 수 있었습니다.
2-2. Decision Tree

Decision Tree는 max_depth = 20, min_sample_leaf =2 하이퍼파라미터를 이용하여
0.643의 높은 정확도를 얻을 수 있었습니다.
2-3. MLP
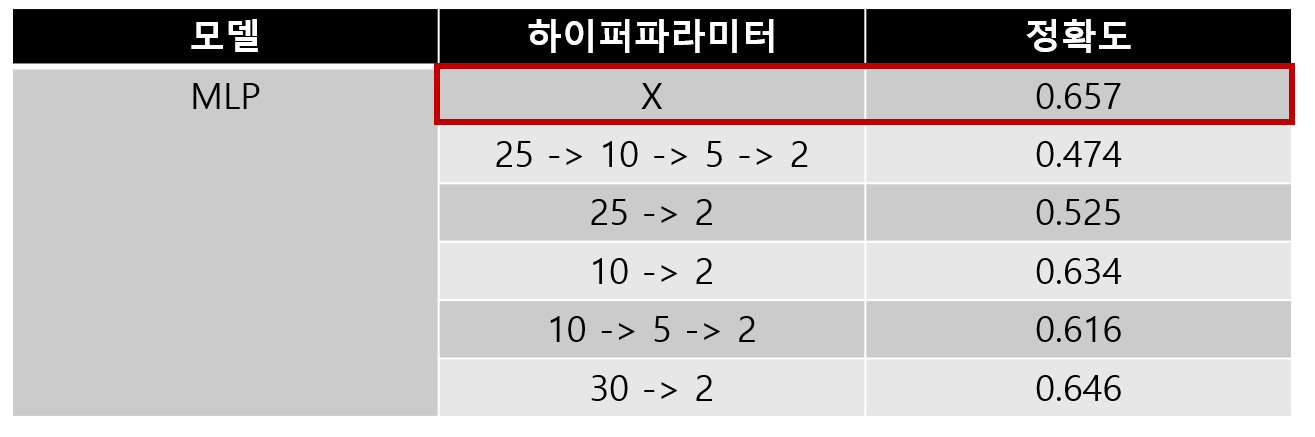
MLP는 하이퍼파라미터가 없을 때
0.657의 높은 정확도를 얻을 수 있었습니다.
2-4. XGBoost
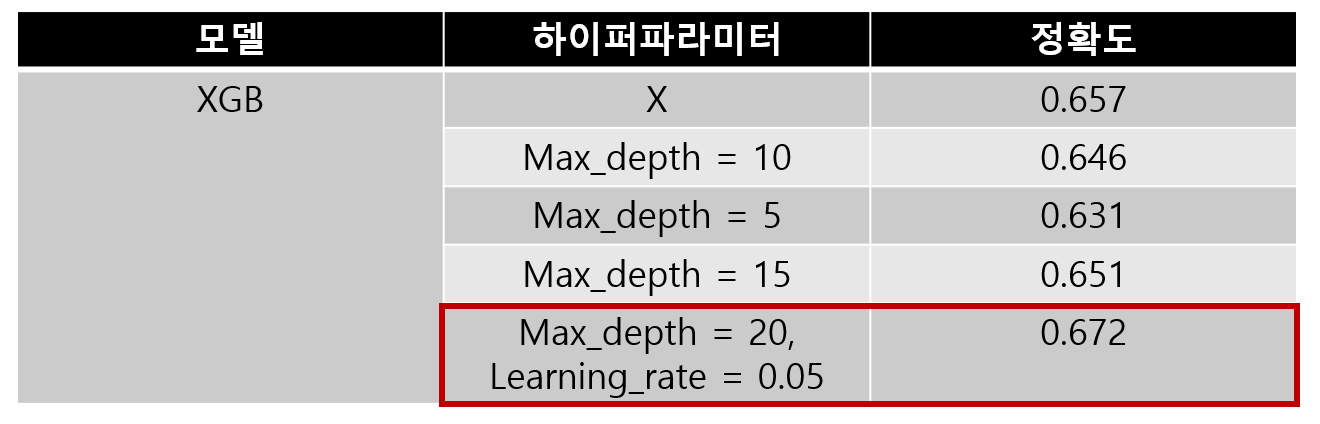
XGBoost는 max_depth = 20, learning_rate = 0.05 하이퍼파라미터를 이용하여
0.672의 높은 정확도를 얻을 수 있었습니다.
3. 필요없는 변수 제외
필요없는 변수의 기준은
Chi-square Test of Independence에서 얻은 결론인

상단의 내용을 근거로 제거해나갔습니다.
나이와 성별에 관련한 변수는 라벨인코더를 진행하여
'변수명_index'로 칼럼 이름이 지칭되어 있습니다.
또한 Feature importance를 확인하며
중요도가 낮은 변수들도 함께 제거해나갔습니다.
3-1. Random Forest
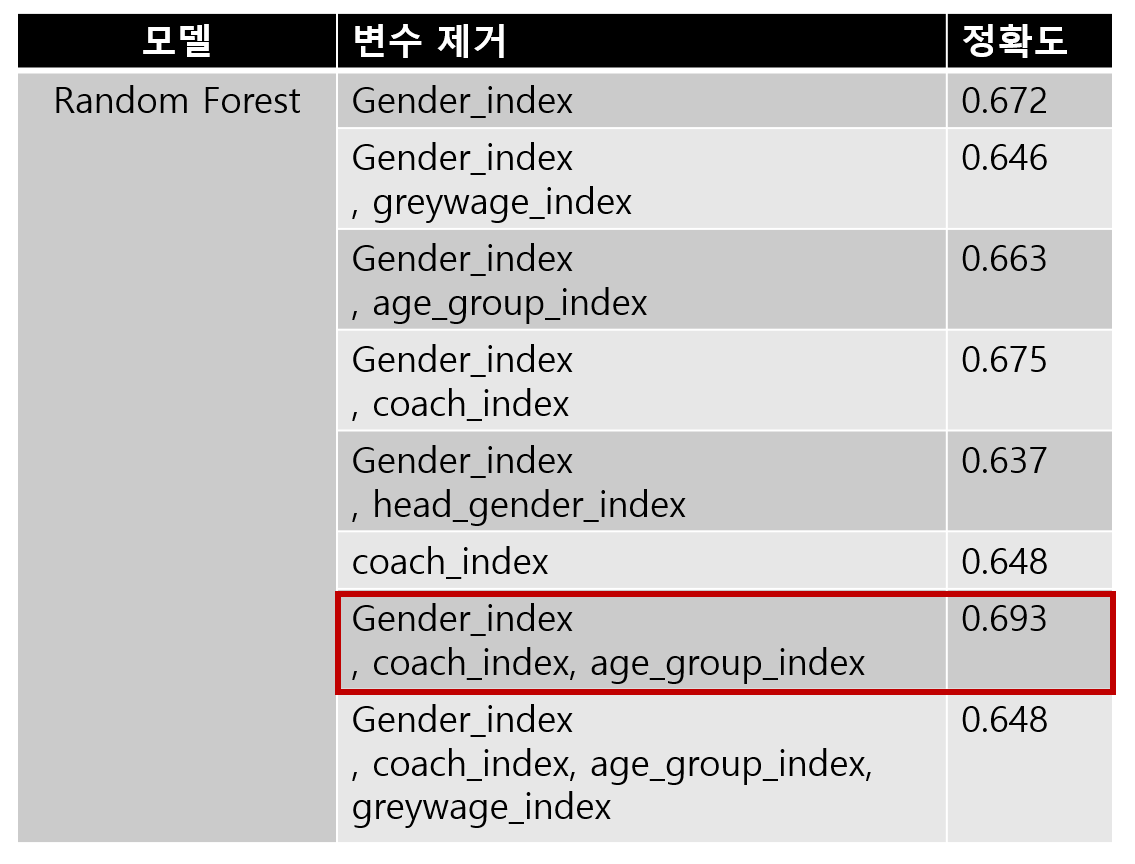
Random Forest는 Gender_index, coach_index, age_group_index를 제거하니
0.693의 정확도를 얻을 수 있었습니다.
3-2. Decision Tree
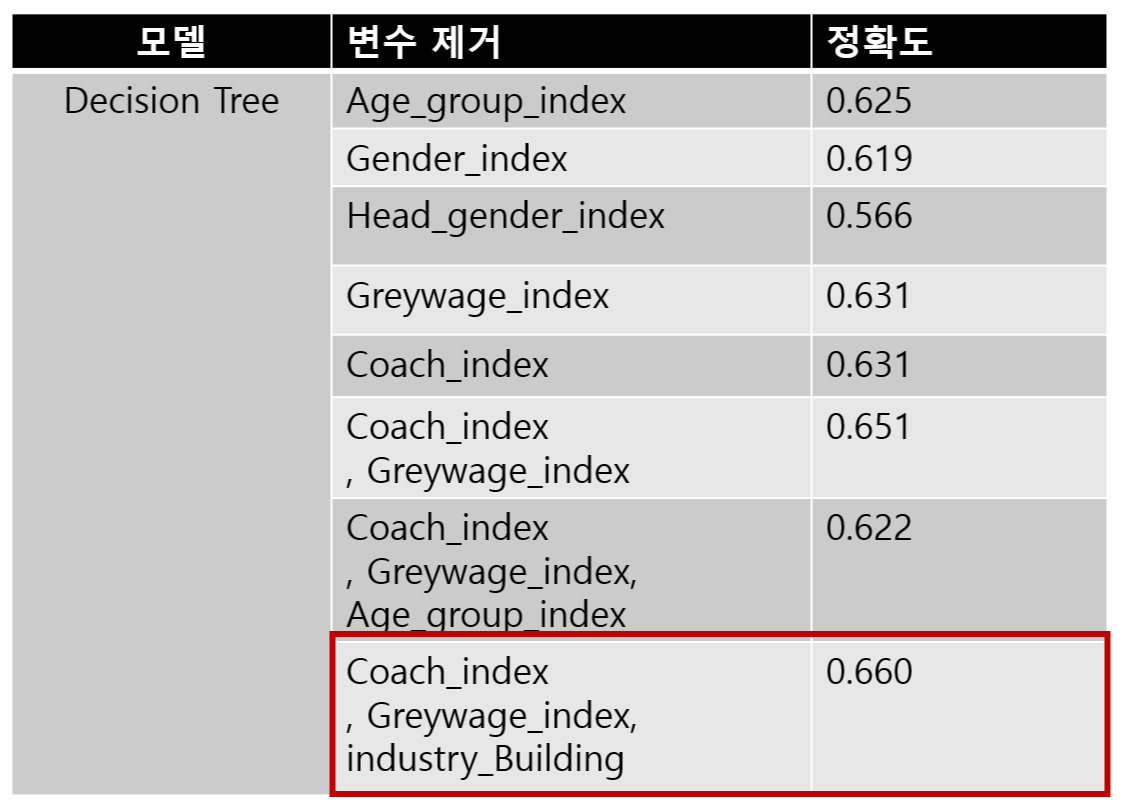
Decision Tree는 Gender_index, Greywage_index,industry_Building을 제거하니
0.666의 정확도를 얻을 수 있었습니다.
3-3. MLP

MLP는 Coach_index를 제거하니
0.693의 정확도를 얻을 수 있었습니다.
3-4. XGBoost

XGBoost는
Age_group_index, Greywage_index, Gender_index, Head_gender_index,
Coach_index, profession_Teaching, PR, Marketing
을 제거하니
0.699의 정확도를 얻을 수 있었습니다.
4. 종합
수치들이 모두 비슷했지만,
2번 파라미터 조정과 3번 변수 제거 항목에서
XGBoost를 이용한 것이 가장 정확도가 높았습니다.
하이퍼파라미터와 변수를 제거하면서 각 모델의 특징을 알아보았습니다.
XGBoost는 Early Stopping 기능을 통해 과적합을 규제하는 특징을 가지고 있습니다.
MLP는 다층 퍼셉트론을 쌓아 문제를 해결하지만, 은닉층의 오차를 구하기 힘들고
이로 인해 과적합이 발생할 수 있습니다.
Random Forest는 데이터 크기에 비례하여 많은 트리를 생성하기 때문데
데이터 크기가 많으면 과적합될 위험성이 큽니다.
Decision Tree 또한 과적합 될 발생률이 높은 단점을 가지고 있습니다.
따라서, 많은 칼럼을 가진 데이터에서
과적합을 규제하는 특징을 가진 XGBoost가 가장 적절하다는 결론을 내렸습니다.
사실 이번 포스팅에서
멘토님이 조언해 주신 Group_by를 이용한
모델링도 진행해보려했습니다.
하지만....!
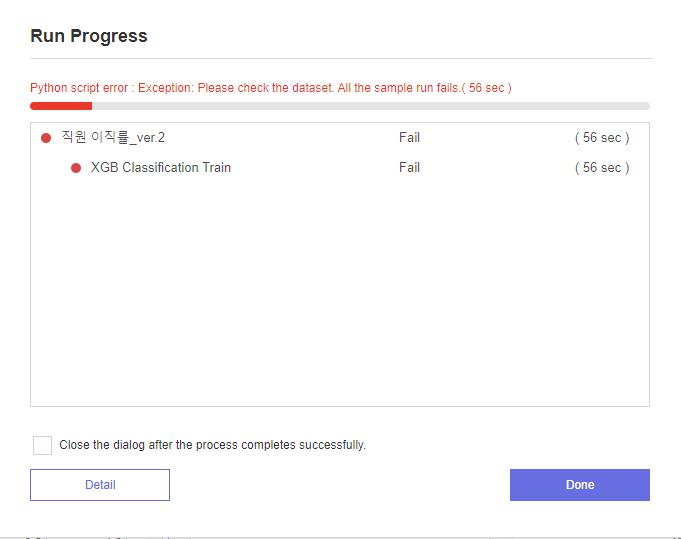
이렇게 오류가 발생하여 해결해보고 있는 중입니다...!ㅠㅠㅠ
다음 포스팅에서는
Group_by를 이용한 모델링과
최종 결론에 대해 포스팅하도록 하겠습니다.
다음 포스팅도 기대해주세요!
* 본 포스팅은 삼성 SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다 *



