
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Brightics Studio
- 혼공
- 혼공머신러닝딥러닝
- 모델링
- 영상제작기
- 직원 이직률
- 삼성SDS Brightics
- 개인 의료비 예측
- 캐글
- 혼공학습단
- 팀 분석
- 직원 이직여부
- 삼성 SDS Brigthics
- 삼성SDS
- 삼성 SDS
- Brightics
- 포스코 아카데미
- Brigthics를 이용한 분석
- 포스코 청년
- 삼성SDS Brigthics
- 노코드AI
- 추천시스템
- 브라이틱스
- 데이터분석
- Brightics를 이용한 분석
- Brigthics
- Brigthics Studio
- 혼공머신
- 데이터 분석
- 브라이틱스 서포터즈
- Today
- Total
데이터사이언스 기록기📚
[삼성 SDS Brightics 서포터즈] #14_개인 프로젝트_직원 이직률② EDA 본문
[삼성 SDS Brightics 서포터즈] #14_개인 프로젝트_직원 이직률② EDA
syunze 2022. 10. 11. 17:28안녕하세요!
Brigthics 서포터즈 3기입니다!
이번 포스팅은 직원 이직률 2번째 편으로
전 편에서 말씀드린 것과 같이
데이터 확인과 EDA를 진행하려 합니다!
🔽전 편이 궁금하시면 아래 링크를 클릭해주세요!🔽
[삼성 SDS Brightics 서포터즈] #13_개인 프로젝트_직원 이직률① 데이터 선정
안녕하세요! Brightics 서포터즈 3기입니다! 저번 주까지는 팀 프로젝트를 진행했었는데요 이번 주부터 약 6주간은 개인 프로젝트를 진행할 예정입니다! 6주간 제 계획은 1주 - 데이터 선정 및 분석
subinze.tistory.com
1. 데이터 로드
먼저, 저는 캐글에서 데이터를 가져왔기때문에
데이터 업로드하는 과정을 진행해야합니다!

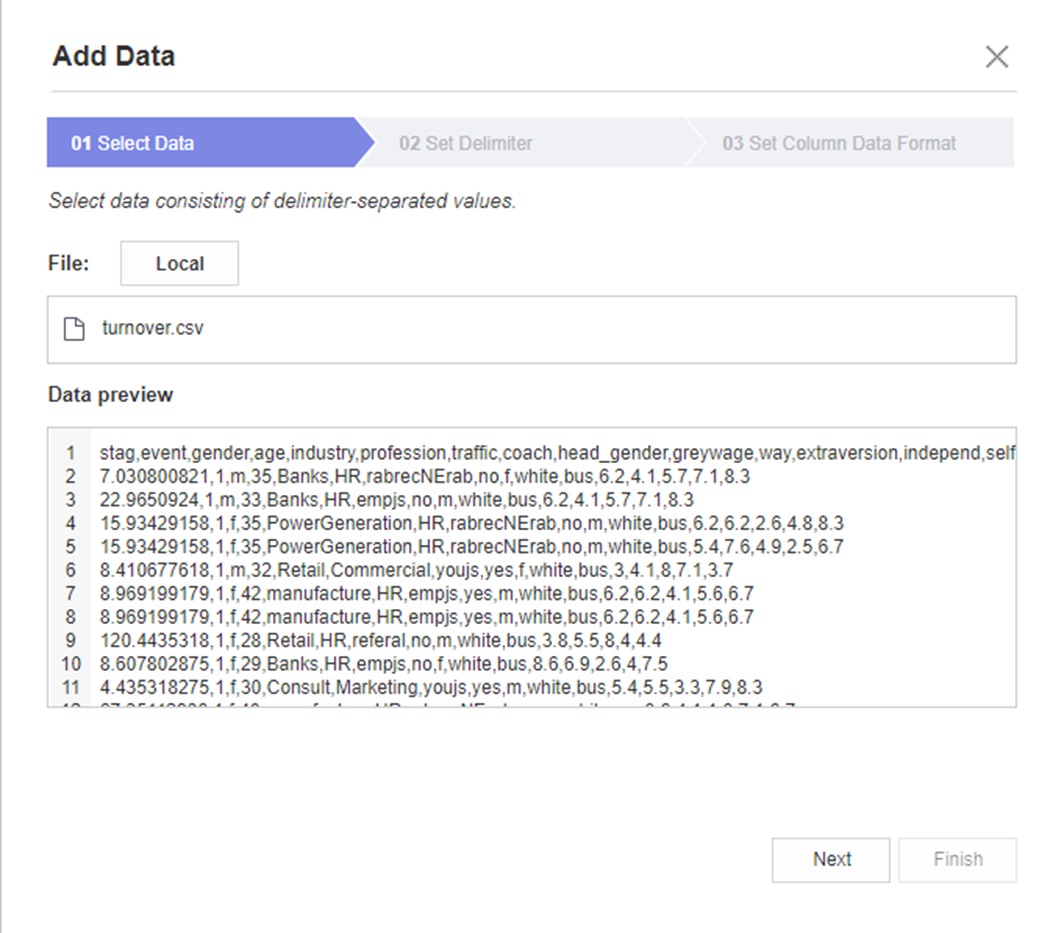
왼쪽 사진처럼
오른쪽 끝 Palette를 선택한 후,
Data - Add를 눌러줍니다.
그럼
오른쪽 사진처럼 Add Data 화면이 뜨게됩니다!
1~3까지 순차적으로 확인해보며 데이터 업로드를 마무리합니다.
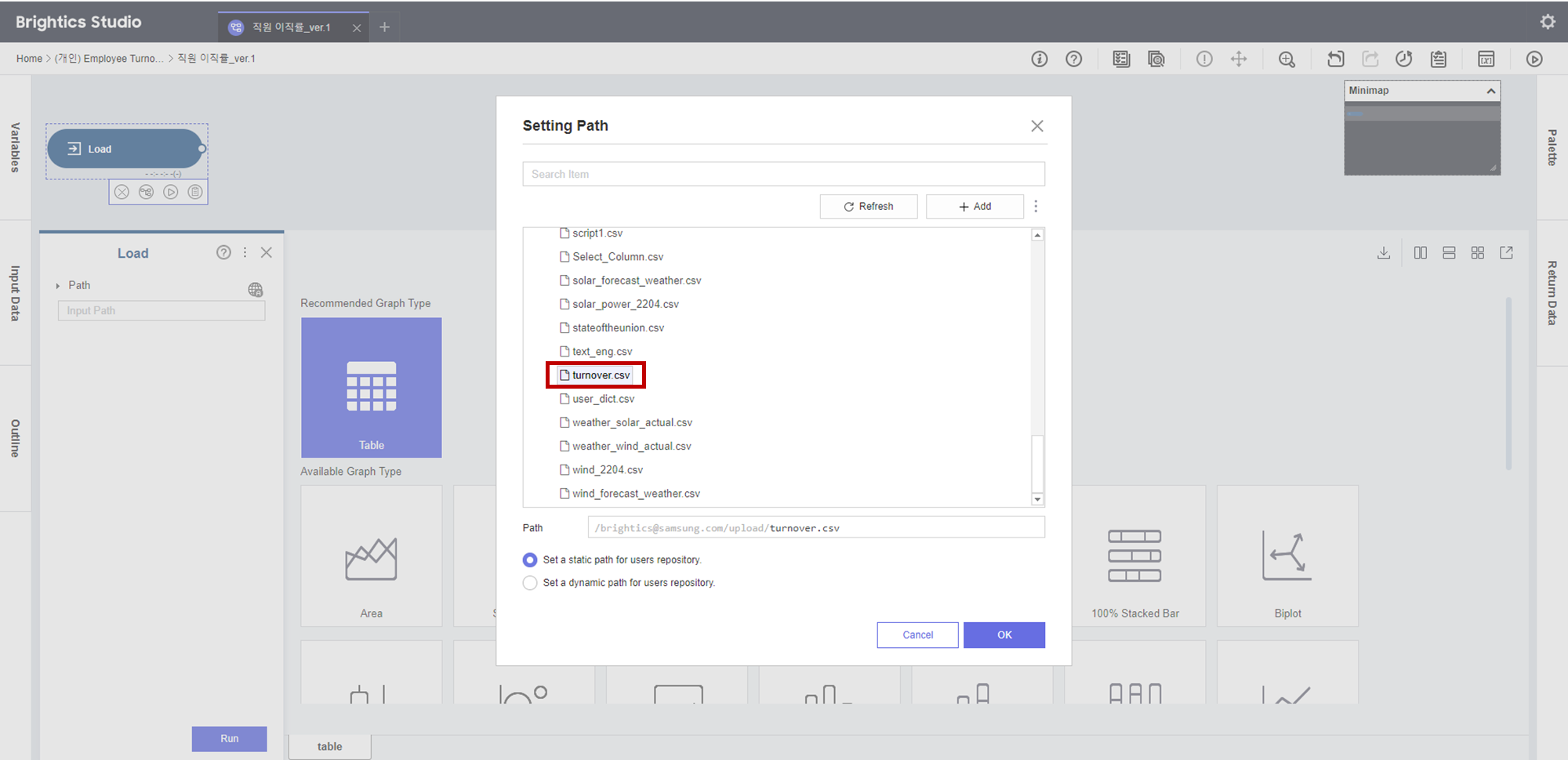
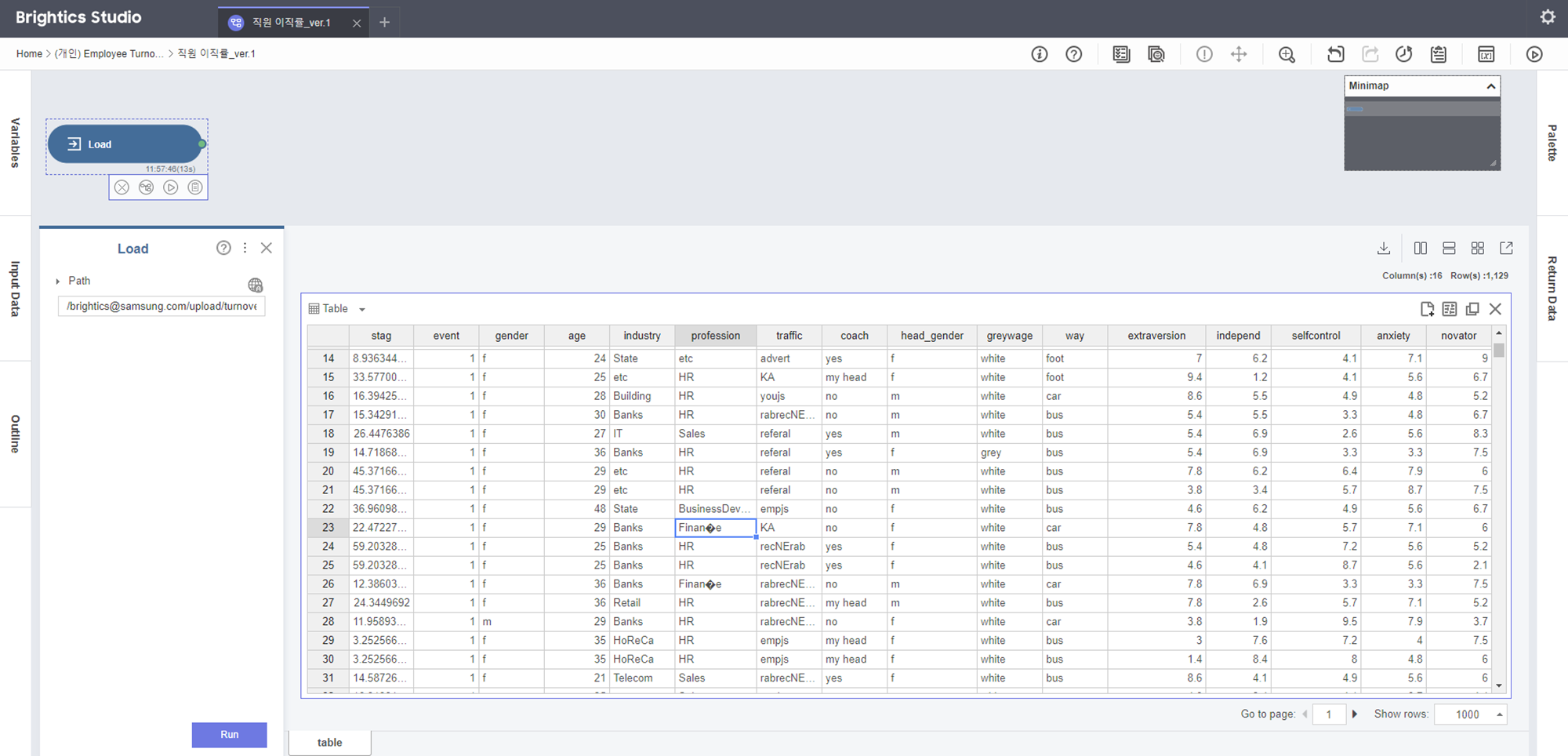
Load 블록을 이용해
turnover.csv가 업로드 된걸 확인할 수 있었습니다!
2. 데이터 확인
2-1. Profile Table
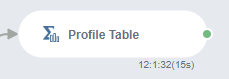
가장 먼저, Profile Table 블록을 통해
데이터 분포 및 특징을 한 눈에 알아보도록 하겠습니다!
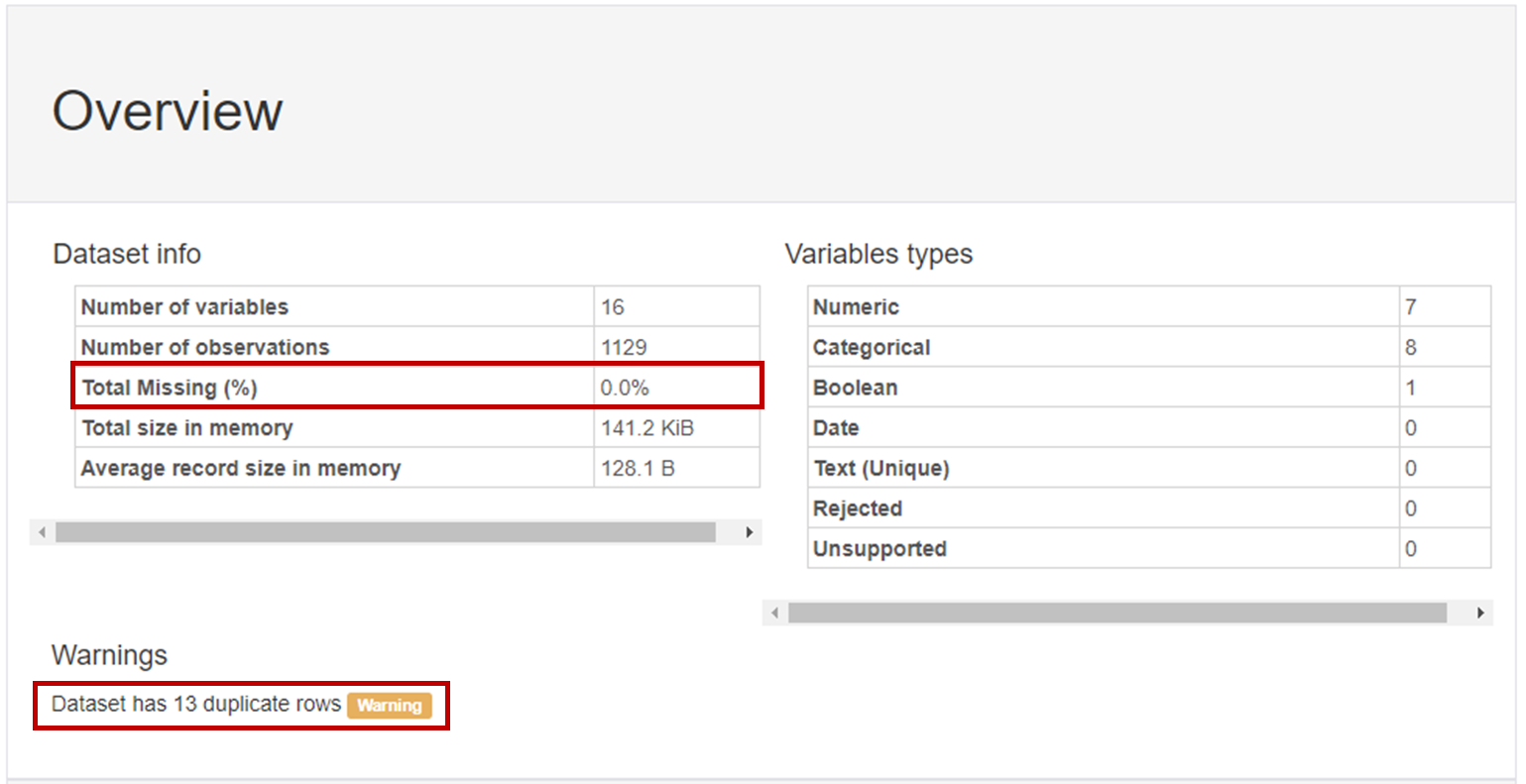
Overview에서
Missing 데이터는 없는 것으로 확인되었고
이후 전처리할 때 주의깊게 봐야하는 Warning을 확인하였습니다!
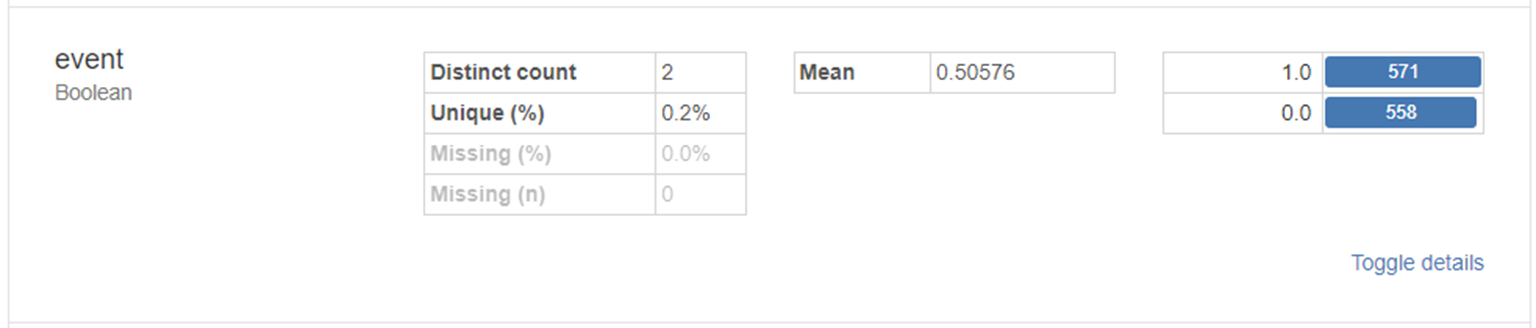
하단의 그래프에서 Y값인 event를 확인해보았습니다.
event는 0과 1의 비율이 대략 1:1로
데이터 불균형 문제는 고려하지 않아도 된다는 결론을 내렸습니다!
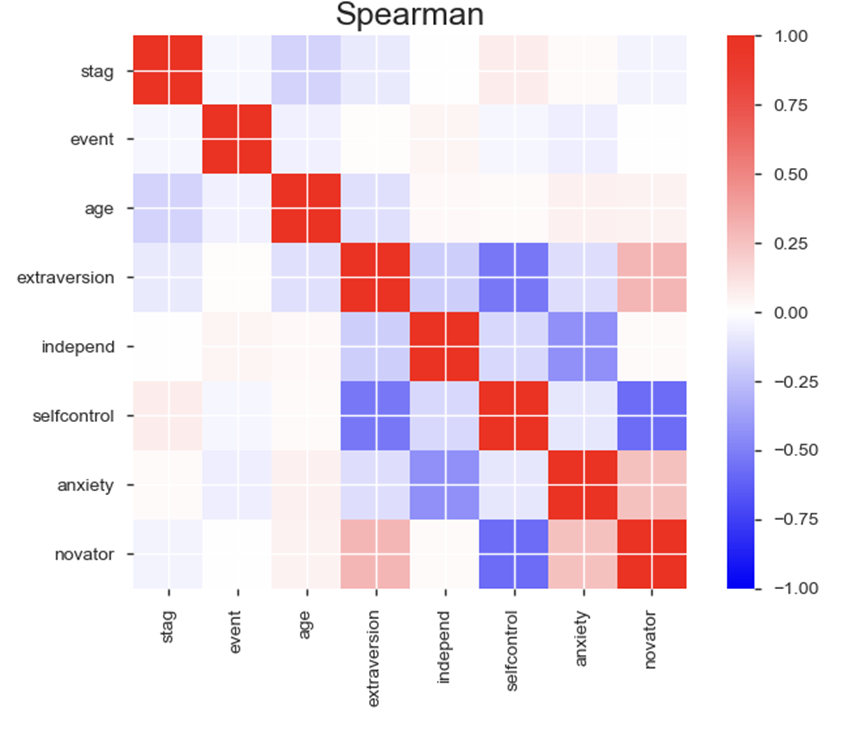
Spearman의 상관계수를 확인해보니
novator와 selfcontrol이 음의 선형 상관관계를 가진다는 것을 확인할 수 있었습니다.
2-2. Statistic Summary
다음은 Statistic Summary를 통해
수치형 변수의 특징들을 알아봤습니다.
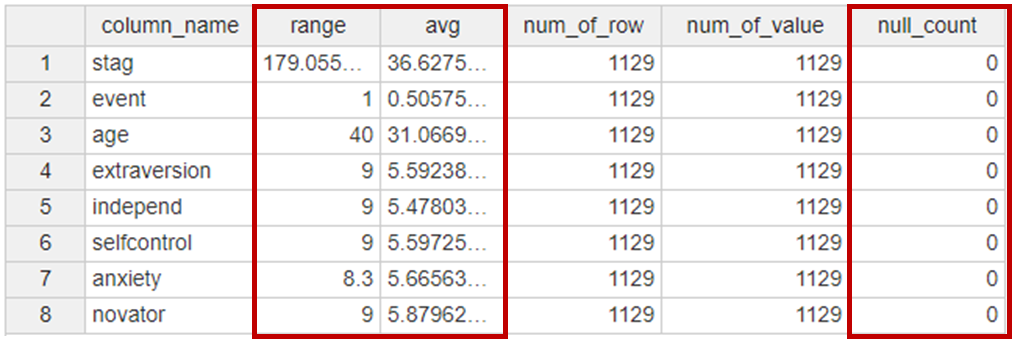
수치형 변수들의 range는
변수 특징에 맞게 있을 수 있는 범주에 있음을 확인할 수 있었습니다.
Avg를 확인해보니,
stag는 앞쪽에 데이터가 몰려있는 것을 확인할 수 있었습니다.
또한, 모든 변수의
null count가 없음을 확인할 수 있었습니다.
2-3. String Summary
다음은 String Summary를 통해
카테고리형 변수의 특징들을 알아봤습니다.

카테고리형 변수들은
모두 null count가 없음을 확인할 수 있었습니다.
또한 num of distinct를 통해
각 변수별 개수 확인을 해 보았습니다.
2-4. Replace String Variable
Replace String Variable 함수를 통해
일부 String값을 바꾸어보았습니다.

데이터를 로드하던 중,
Finance의 c 철자를 인식하지 못하는 것을 확인할 수 있었습니다.
그래서 Replace String Variable 함수를 통해
이를 교정해보았습니다.
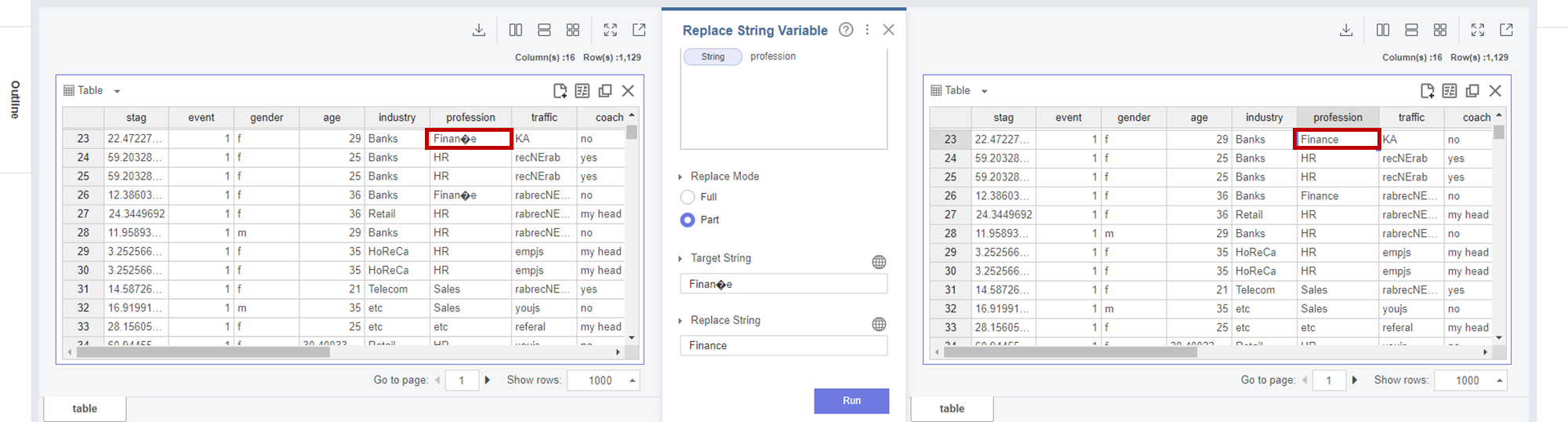
Target String에 원래 단어를 입력하고,
Replace String에 변경할 단어를 입력하였습니다.
Python에서는
칼럼 선택 후, replace 함수를 이용하여 변경하게 되는데
간단하게 단어로 변경할 수 있어 매우 편리했습니다!
2-5. Python Script
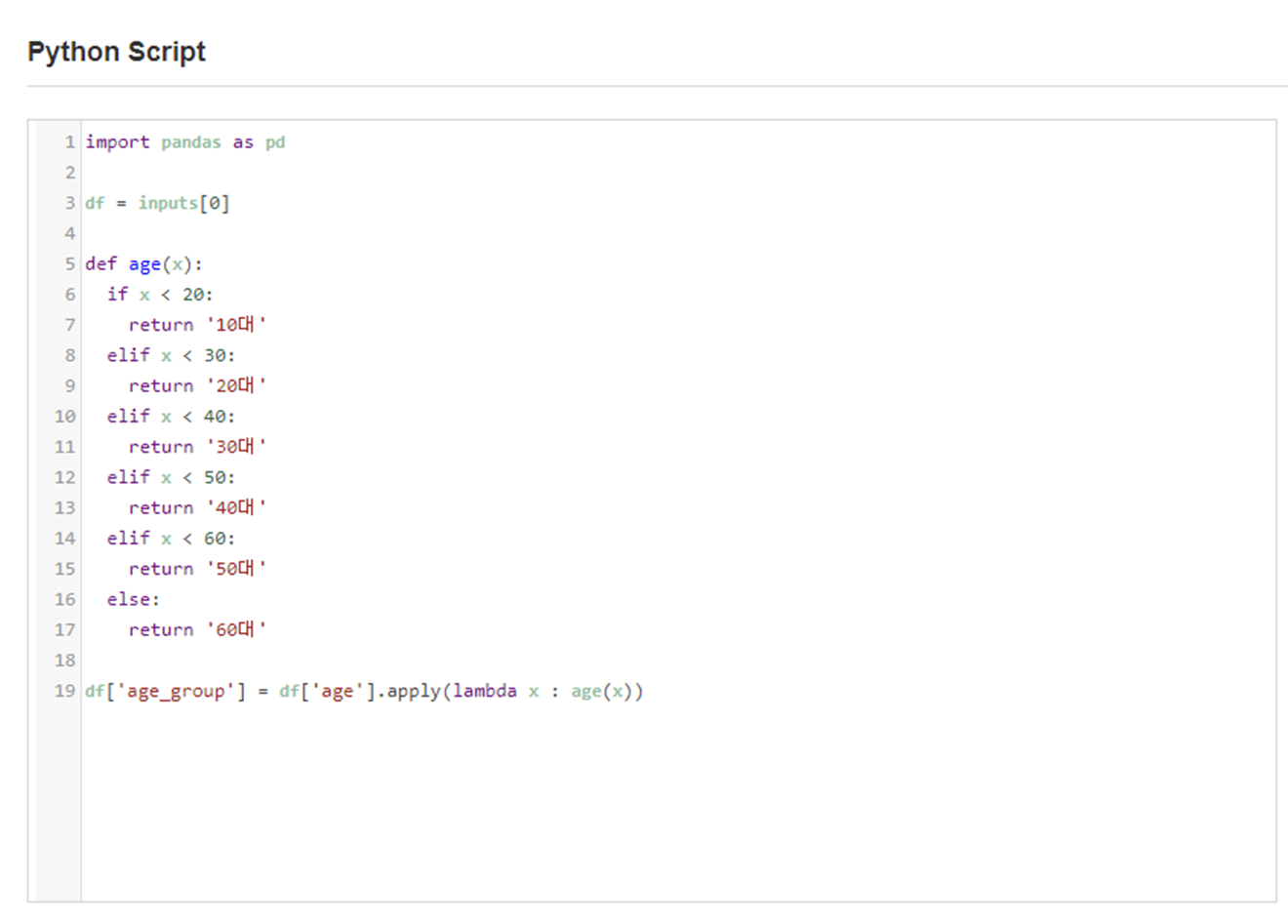
저는 나이 부분의 데이터를 한 눈에 알아보기 위해
Python Script를 이용하여 나이대로 그룹화를 하였습니다!

Python Script로 적용 후
age_group 칼럼이 생성되는 것을 확인할 수 있었습니다.
3. EDA
3-1. stag, age

stag와 age를 히스토그램을 이용하여 확인해보았습니다.
stag를 확인해보면
근무한 시간이 짧은 사람의
분포가 더 많은 것을 확인해 볼 수 있었습니다.
age는 21~43까지는 많고,
21살 이전과 43살 이후에는 적은 것을 파악할 수 있었습니다.
3-2. event
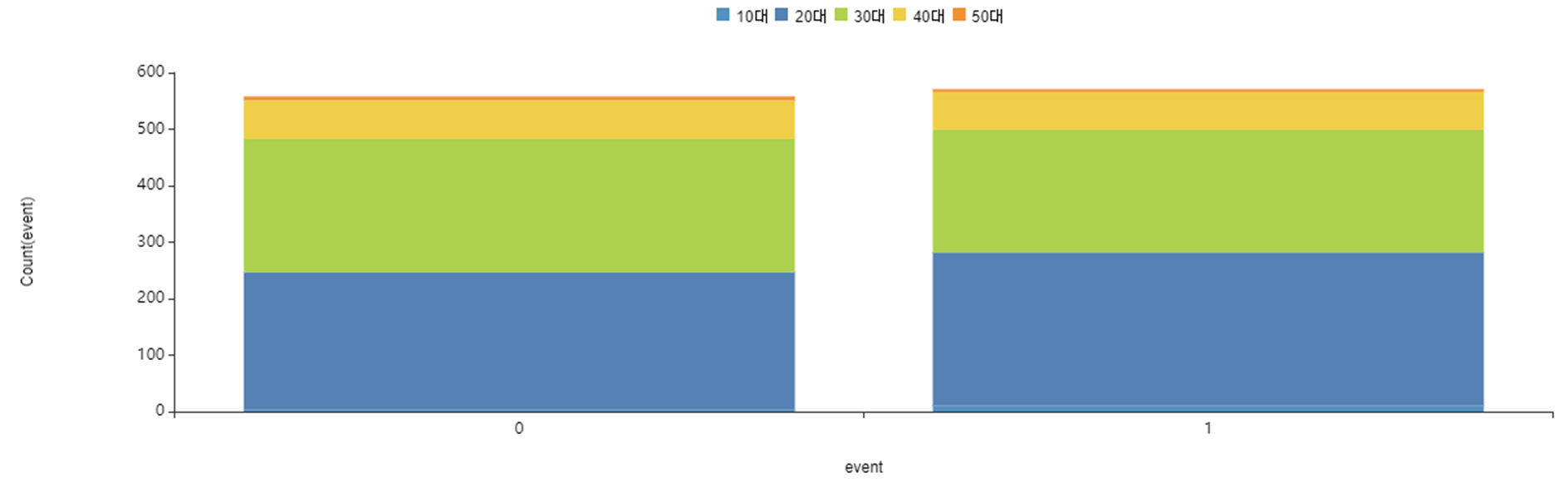
어느 나이대가 가장 이직이 많은지 알아보기 위하여
event를 기준으로 분포를 나타내보았습니다.
앞서 본 age 그래프와 같이
20대~30대 비율이 높긴 하지만
20대 이직자가 30대 이직자보다 더 많은 것을 확인할 수 있었습니다.
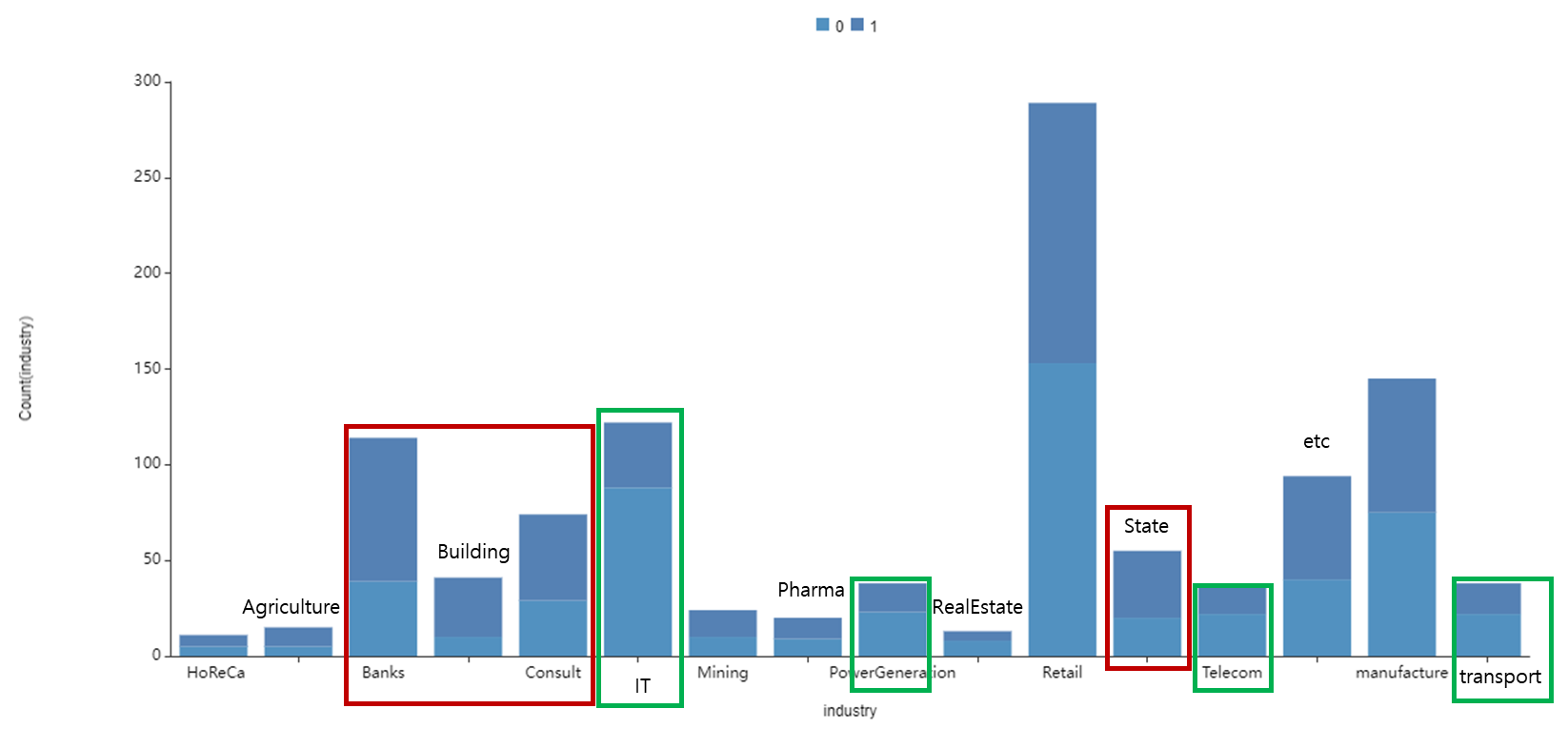
또한, 산업군별로 이직자를 알아보기위해
산업군별 event 분포를 확인해보았습니다.
빨간색인 Banks, Building, Consult, State는 남는 사람보다 이직자가 더 많음을 확인할 수 있었으며
초록색인 IT, PoverGeneration, Telecom, transport는 남는 사람이 더 많음을 확인할 수 있었습니다.
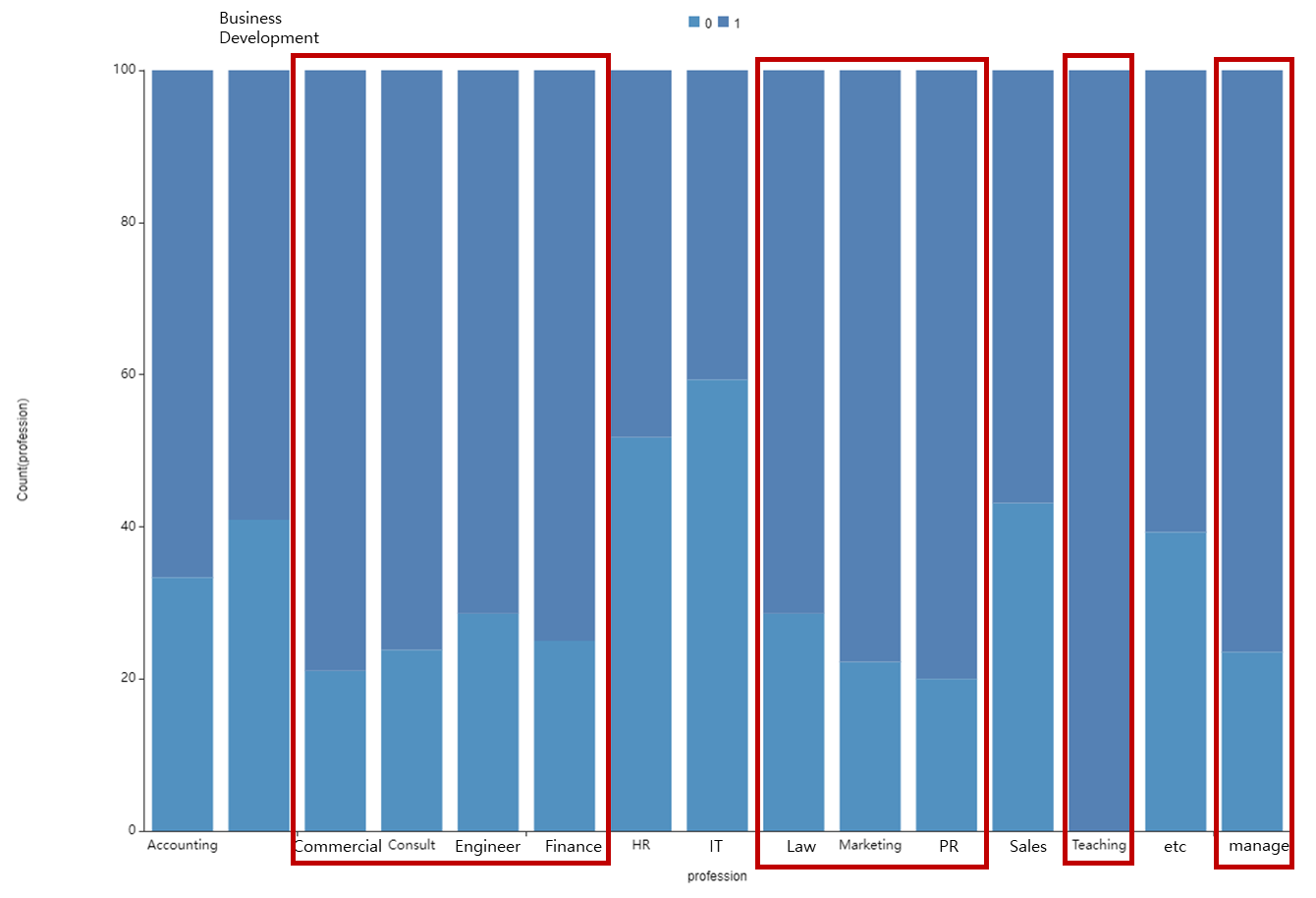
산업군에서 더 들어가, 직업군에서 이직자를 알아보기 위해
직업군별 event 분포를 확인해보았습니다.
Commercial, Consult, Engineer,Finance,
Law, Marketing, PR, Teaching, manage가
다른 직업군보다 이직자가 많다는 것을 확인할 수 있었습니다.
이번 포스팅은
데이터 확인과 EDA를 진행하였습니다!
다음포스팅에는
데이터 통계 분석과 전처리 부분으로 찾아오도록 하겠습니다!
* 본 포스팅은 삼성 SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다 *
'대외활동 > 삼성SDS Brightics 서포터즈' 카테고리의 다른 글
| [삼성 SDS Brightics 서포터즈] #16_개인 프로젝트_노코드 AI 오픈소스 Brightics Studio로 분석_직원 이직률④ 데이터 전처리, 모델링 (0) | 2022.10.25 |
|---|---|
| [삼성 SDS Brightics 서포터즈] #15_개인 프로젝트_노코드 AI 오픈소스 Brightics Studio로 분석_직원 이직률③ 통계적 검정 및 데이터 전처리 (0) | 2022.10.18 |
| [삼성 SDS Brightics 서포터즈] #13_개인 프로젝트_직원 이직률① 데이터 선정 (1) | 2022.10.04 |
| [삼성 SDS Brigthics 서포터즈] #12_팀 프로젝트_영상 제작기③ (1) | 2022.09.27 |
| [삼성 SDS Brigthics 서포터즈] #11_팀 프로젝트_영상 제작기② (0) | 2022.09.20 |



