
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 팀 분석
- Brightics
- 개인 의료비 예측
- 혼공학습단
- 캐글
- 포스코 아카데미
- 삼성SDS
- 삼성SDS Brightics
- 혼공머신러닝딥러닝
- 혼공
- 포스코 청년
- 브라이틱스
- Brigthics Studio
- 삼성 SDS Brigthics
- 브라이틱스 서포터즈
- 추천시스템
- 직원 이직률
- 노코드AI
- Brightics Studio
- 직원 이직여부
- 삼성 SDS
- 모델링
- Brightics를 이용한 분석
- Brigthics를 이용한 분석
- 데이터 분석
- Brigthics
- 혼공머신
- 영상제작기
- 데이터분석
- 삼성SDS Brigthics
- Today
- Total
데이터사이언스 기록기📚
[삼성 SDS Brightics 서포터즈] #16_개인 프로젝트_노코드 AI 오픈소스 Brightics Studio로 분석_직원 이직률④ 데이터 전처리, 모델링 본문
[삼성 SDS Brightics 서포터즈] #16_개인 프로젝트_노코드 AI 오픈소스 Brightics Studio로 분석_직원 이직률④ 데이터 전처리, 모델링
syunze 2022. 10. 25. 20:33안녕하세요~!
16번째 포스팅으로 돌아왔습니다.
이번 포스팅에서는
데이터 전처리 부분인
라벨 인코딩, 원핫인코딩을 진행하고
하이퍼파라미터를 조정하지 않은
기본 모델링을 진행해보고자 합니다!
🔽이전 포스팅이 궁금하시면 아래 링크를 클릭해주세요!🔽
[삼성 SDS Brightics 서포터즈] #13_개인 프로젝트_직원 이직률① 데이터 선정
안녕하세요! Brightics 서포터즈 3기입니다! 저번 주까지는 팀 프로젝트를 진행했었는데요 이번 주부터 약 6주간은 개인 프로젝트를 진행할 예정입니다! 6주간 제 계획은 1주 - 데이터 선정 및 분석
subinze.tistory.com
[삼성 SDS Brightics 서포터즈] #14_개인 프로젝트_직원 이직률② EDA
안녕하세요! Brigthics 서포터즈 3기입니다! 이번 포스팅은 직원 이직률 2번째 편으로 전 편에서 말씀드린 것과 같이 데이터 확인과 EDA를 진행하려 합니다! 🔽전 편이 궁금하시면 아래 링크를 클릭
subinze.tistory.com
[삼성 SDS Brightics 서포터즈] #15_개인 프로젝트_노코드 AI 오픈소스 Brightics Studio로 분석_직원 이직
안녕하세요! Brigthics 서포터즈 3기입니다! 이번 포스팅은 직원 이직률 3번째 편으로 전 편에서 말씀드린 것과 같이 데이터 전처리와 통계적 검정을 진행하려 합니다! 🔽전 편이 궁금하시면 아래
subinze.tistory.com
그럼 16번째 포스팅
시작해보겠습니다!
1. 데이터 전처리
1-1. Label Encoder

저는
gender, coach, head_gender, greywage, age_group
변수를 라벨인코딩하였습니다.
라벨인코딩은
'0,1,2 등 각각의 숫자가 어떤 category를 의미하는지 모른다'
는 단점을 가지고 있습니다.
이에 따라,
지난 포스팅에서 결론지었던
Event(이직 여부)를 결정하는 주요변수가 아닌
gender, coach, head_gender, greywage, age_group를
라벨인코딩을 해주었습니다.
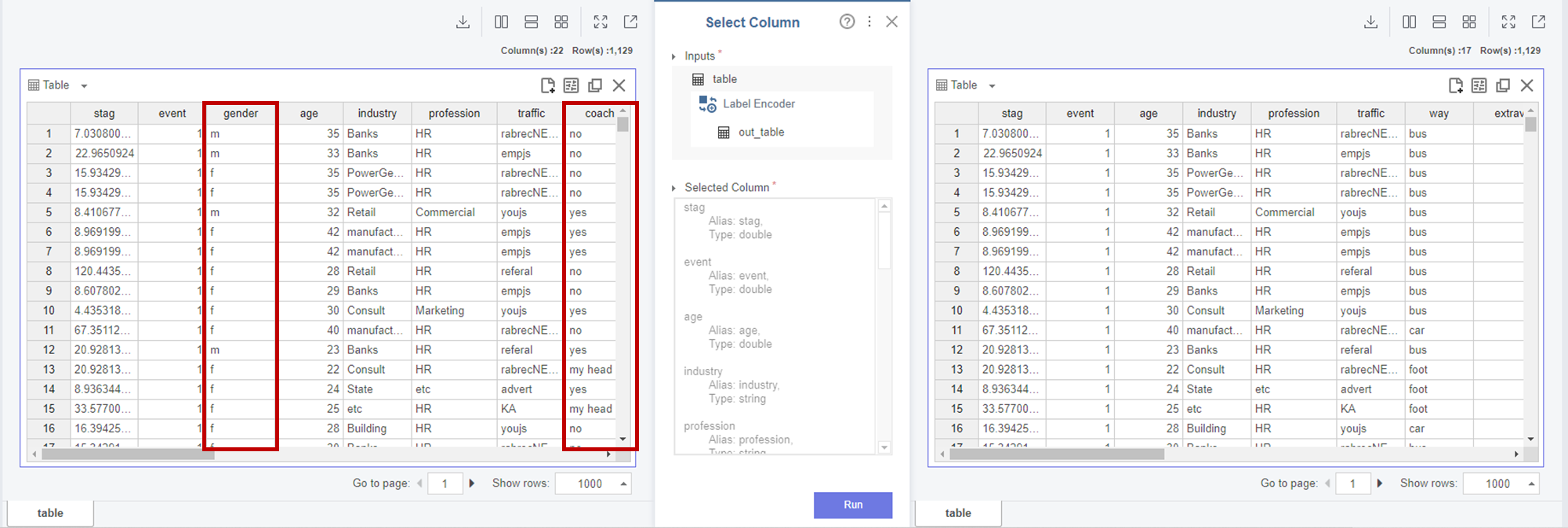
이후
Select Column을 이용하여
라벨인코딩 된 변수들을 삭제하였습니다.
1-2. One Hot Encoder
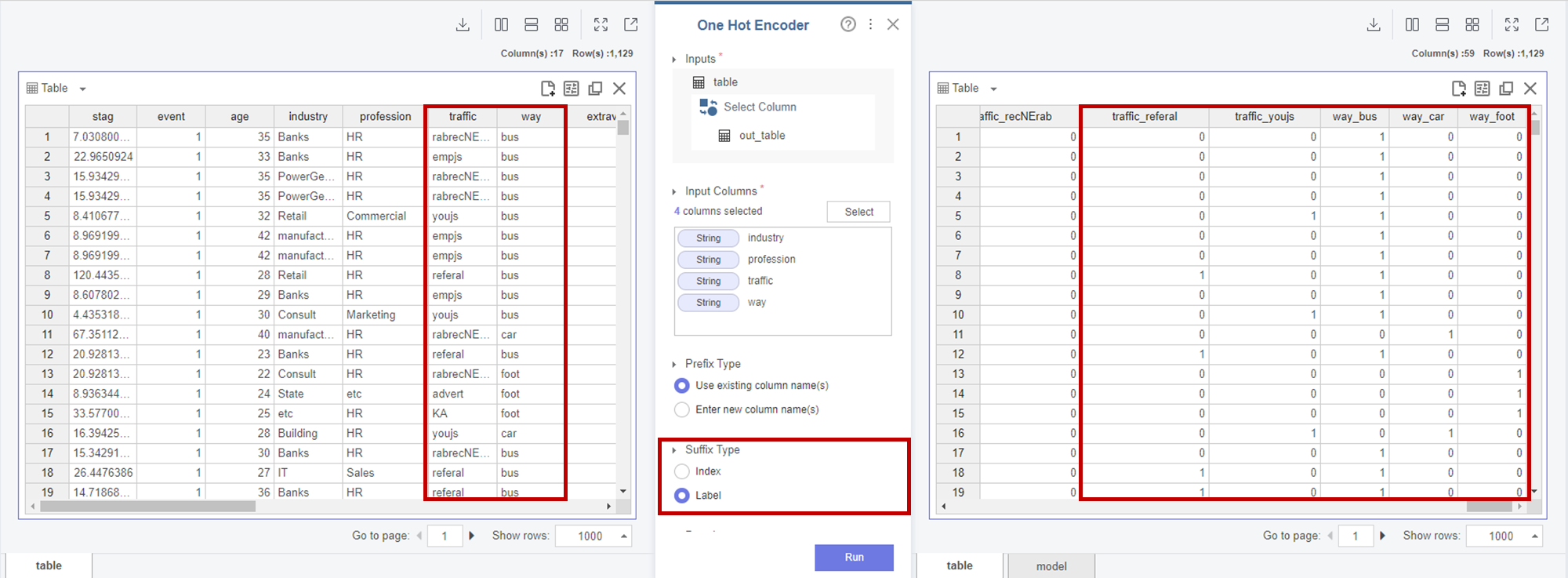
저는 나머지 category형 변수인
industry, profession, traffic, way 변수를
원핫인코딩하였습니다.
원핫인코딩은
데이터양이 많아진다는 단점이 있지만
해당 변수들은
지난 포스팅에서
Event(이직 여부)를 결정하는 주요 변수로
칼럼의 요소들이 의미있다고 판단하여
칼럼의 요소를 구분하는 원핫 인코딩을 하였습니다.

동일하게
Select Column을 이용하여
원핫인코딩 된 변수들을 삭제하였습니다.
1-3. Split Data
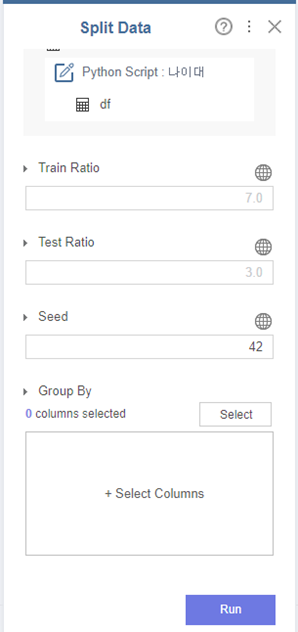
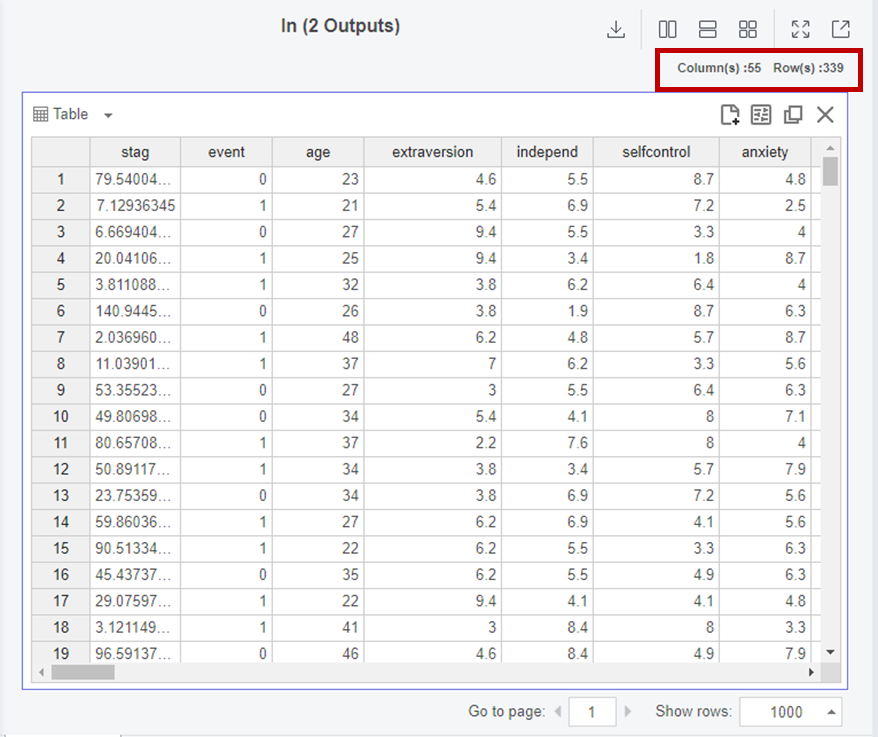
Split Data 코드 블럭을 통해
7:3으로 train, test로 나누었습니다.
코드를 실행할 때마다
train, test 항목이 변하는 것을 막기 위해
Seed는 42로 고정하였습니다.
2. 모델링
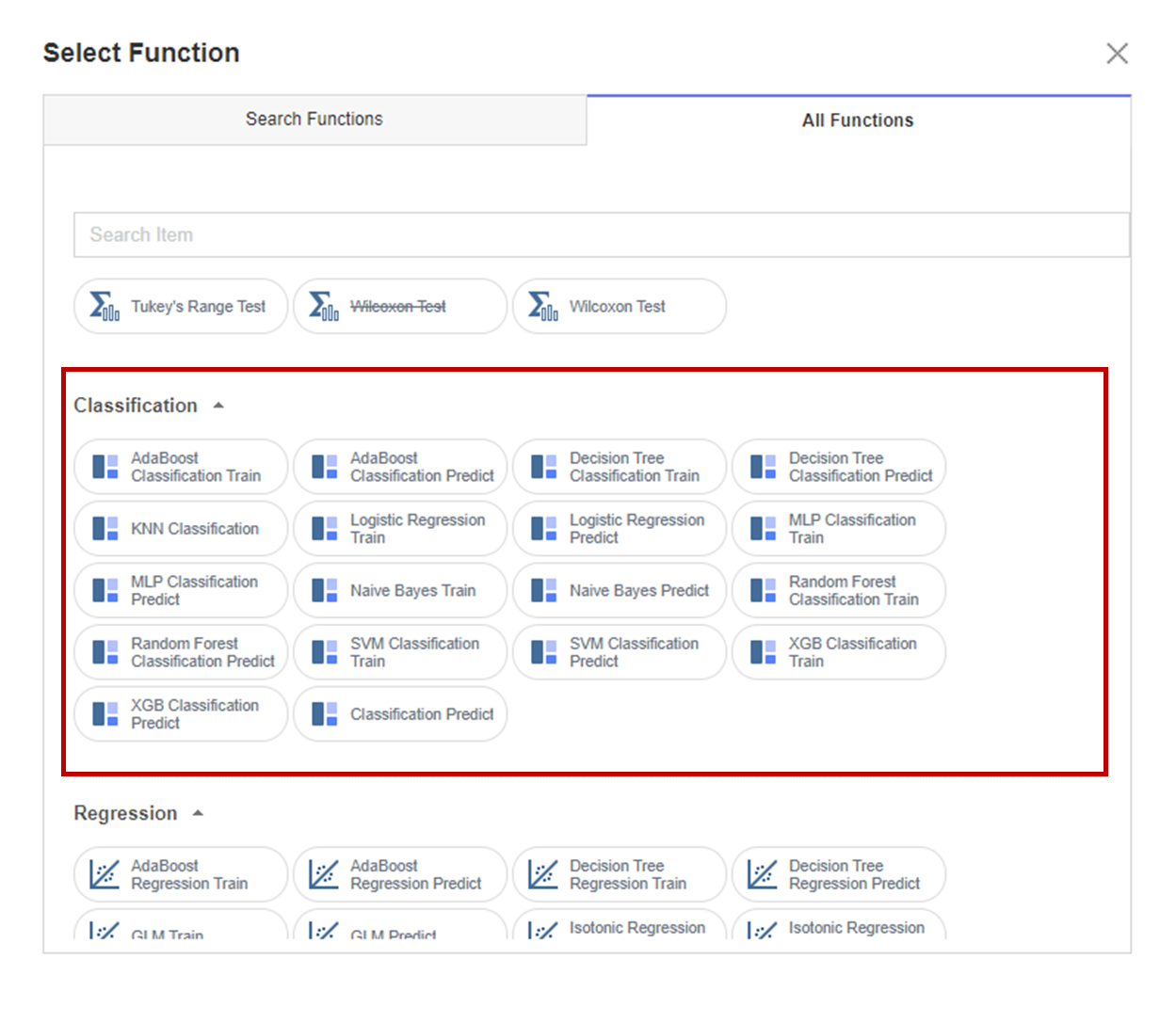
Brightics Studio는
함수 블록을 선택할 때
다음과 같이 Function이 항목별로 구별되어있는
화면을 보실 수 있습니다.
해당 프로젝트의 분석 목적은
이직 여부로, 분류이기 때문에
Classification 항목들을 이용할 것 입니다.
노코드 AI 오픈소스로
Classification을 손쉽게 사용할 수 있습니다!
그럼 이제부터
Classification 모델링을 하나씩 시작해볼까요?!
2-1. Logistic Regression

하이퍼파라미터를 조정하지 않은
Linear Regression 입니다.
0.62의 정확도를 보이고 있고
Treu label 1, Predicted label 0(오답)이 0.43으로높은 편임을 확인할 수 있었습니다.
2-2. Decision Tree

하이퍼파라미터를 조정하지 않은
Decision Tree 입니다!
노드들이 많이 분기되어
한 눈에 파악하기 어렵습니다😥
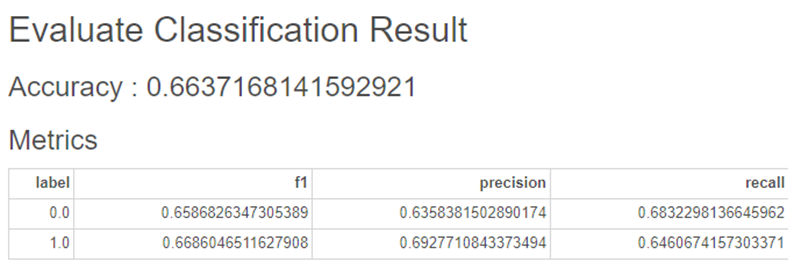
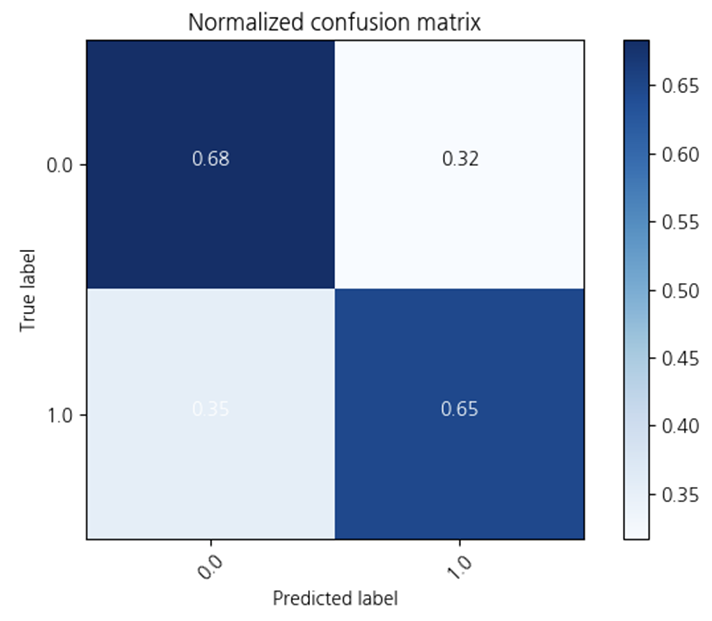
하지만,
Linear Regression보다
정확도가 0.04 향상되었습니다!
정답을 맞춘 확률도 높고,
오답을 맞춘 확률은 감소하였습니다!
2-3. Random Forest
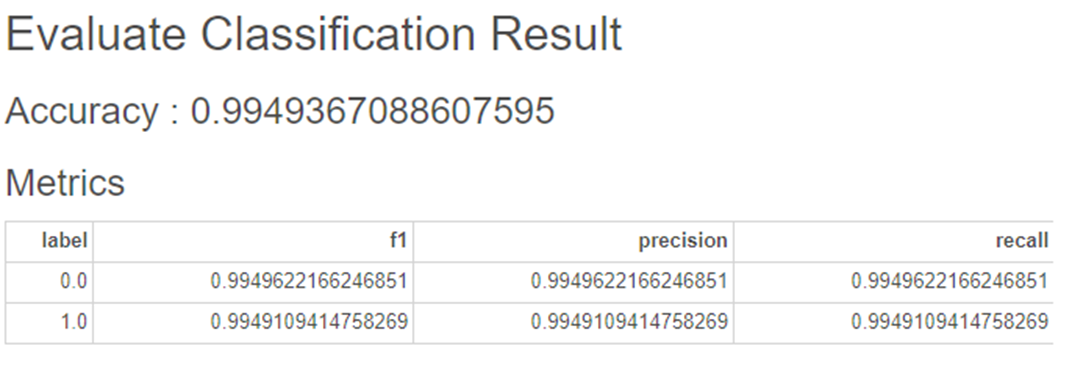
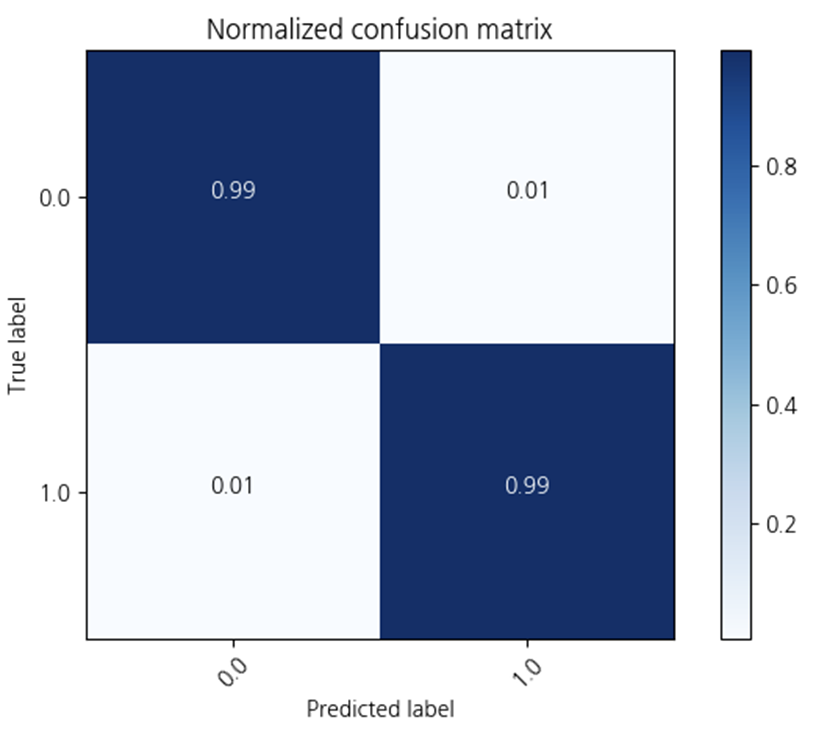
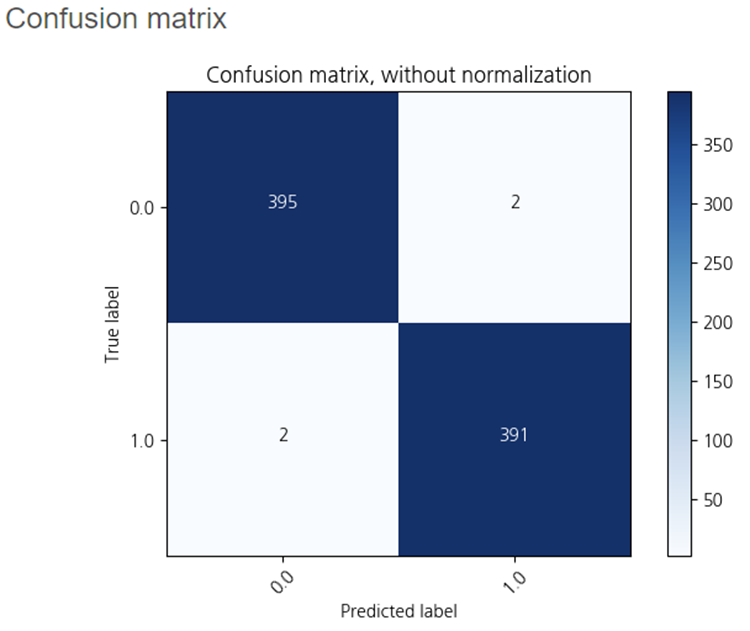
하이퍼파라미터를 조정하지 않고
Random Forest를 사용해보았습니다.
정확도가 0.99로
다른 모델보다 더 좋은 성능을 가지고 있습니다!!
오답으로 분류한
True label 0, Predicted label 1은 2개
True label 1, Predicted label 0은 2개로
가장 적은 오답을 내었습니다!
2-4. XGBoost
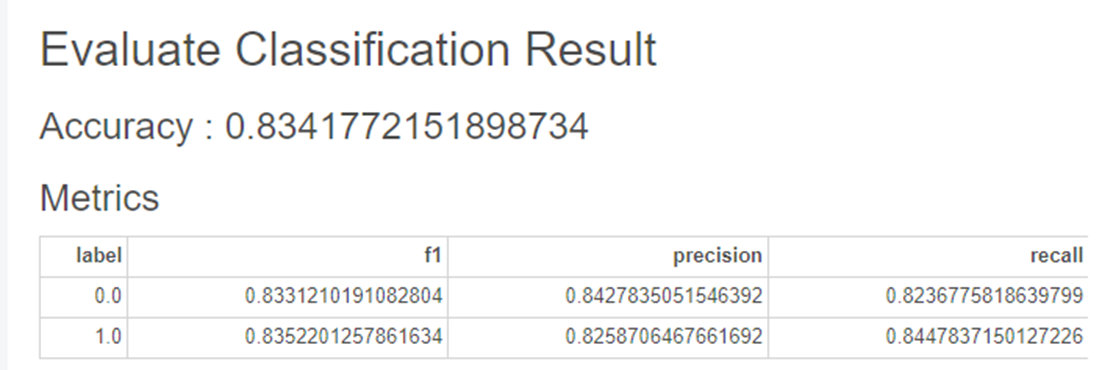
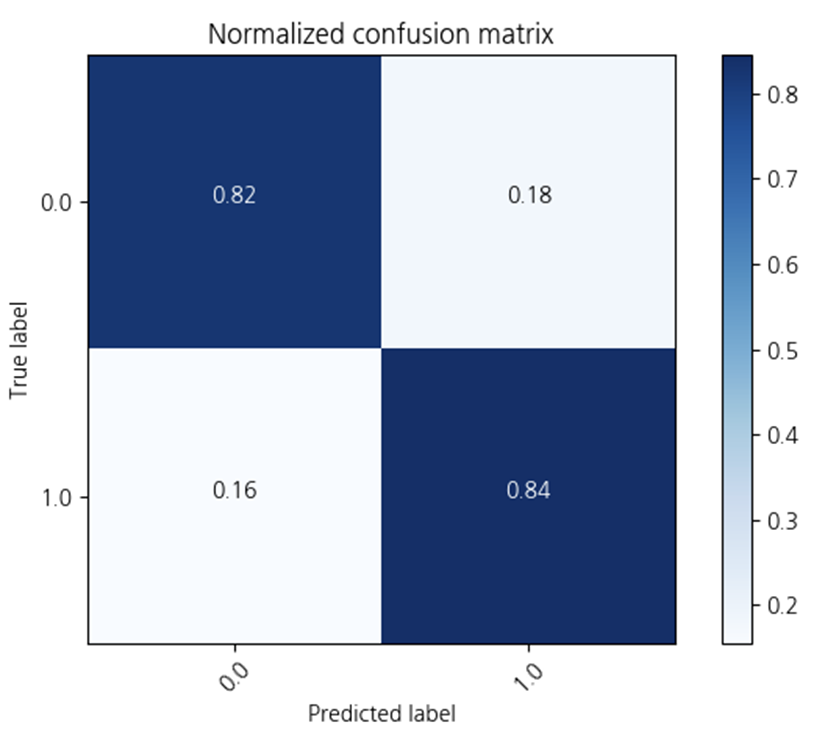
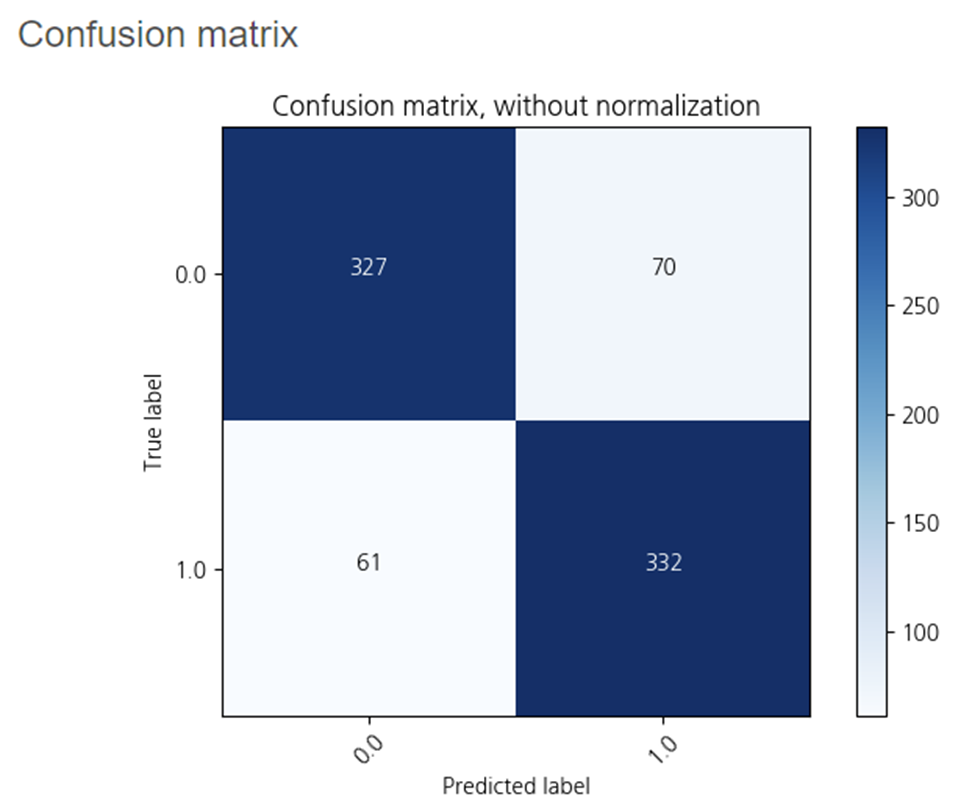
하이퍼파라미터를 조정하지 않고
XGBoost를 사용해보았습니다.
정확도가 0.83로
790개 중 131개가 오분류 되었습니다.
2-5. AdaBoost
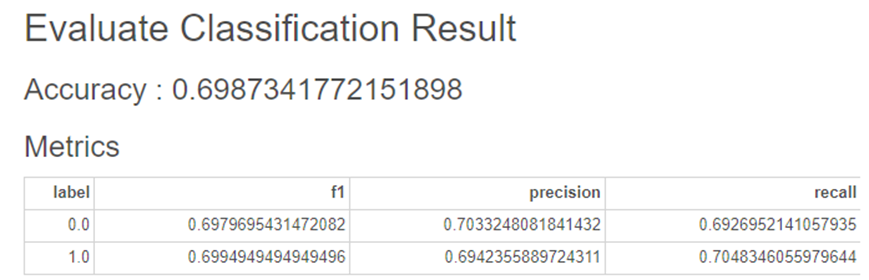

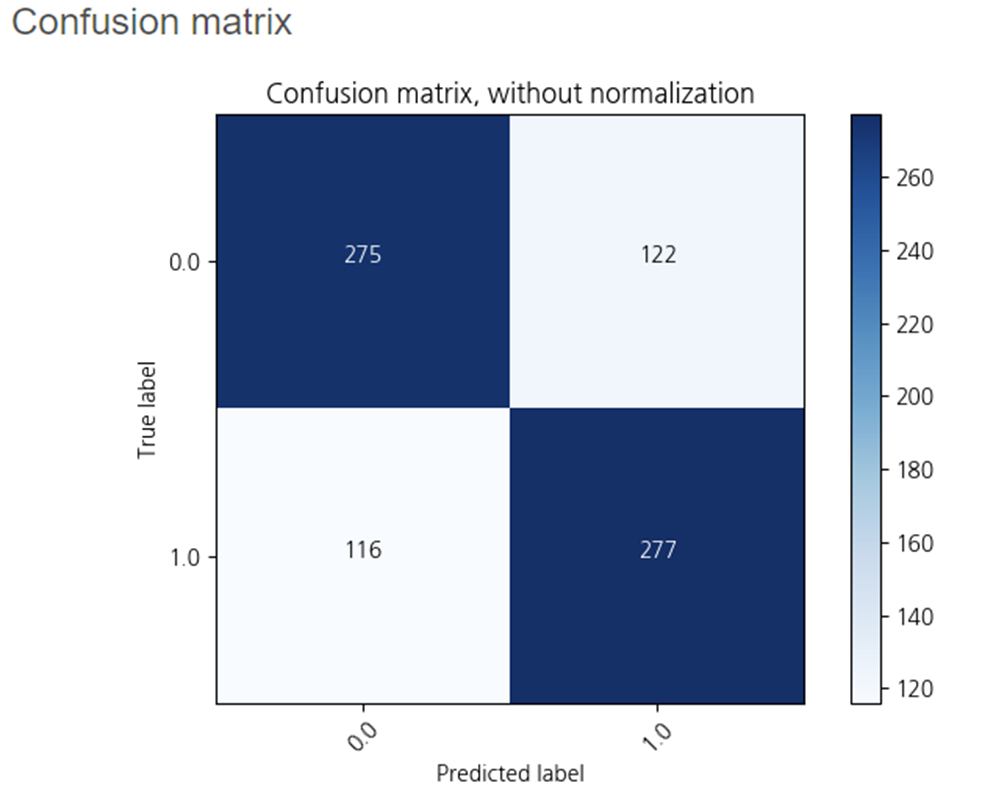
하이퍼파라미터를 조정하지 않고
AdaBoost를 사용해보았습니다.
정확도가 0.69로
Decision Tree와 유사한 정확도를 보이고 있습니다.
2-6. KNN
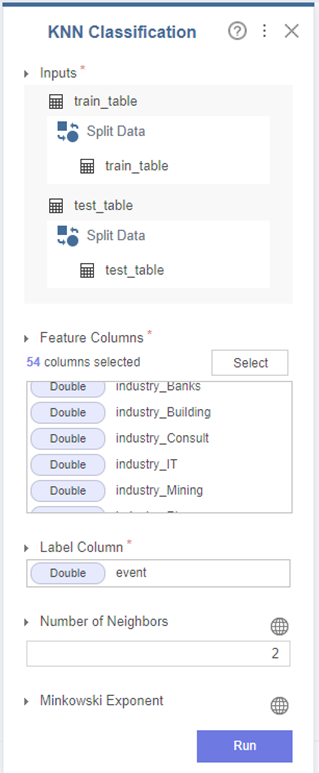
KNN 모델은
타 모델과 다르게
한 번에 train set과 test set을 넣어 분류를 진행합니다.
저는
이직 여부(0,1)에 따라
Number of Neighbors를 2로 설정하였습니다.
이외에는 하이퍼파라미터를 조정하지 않고 진행하였습니다.
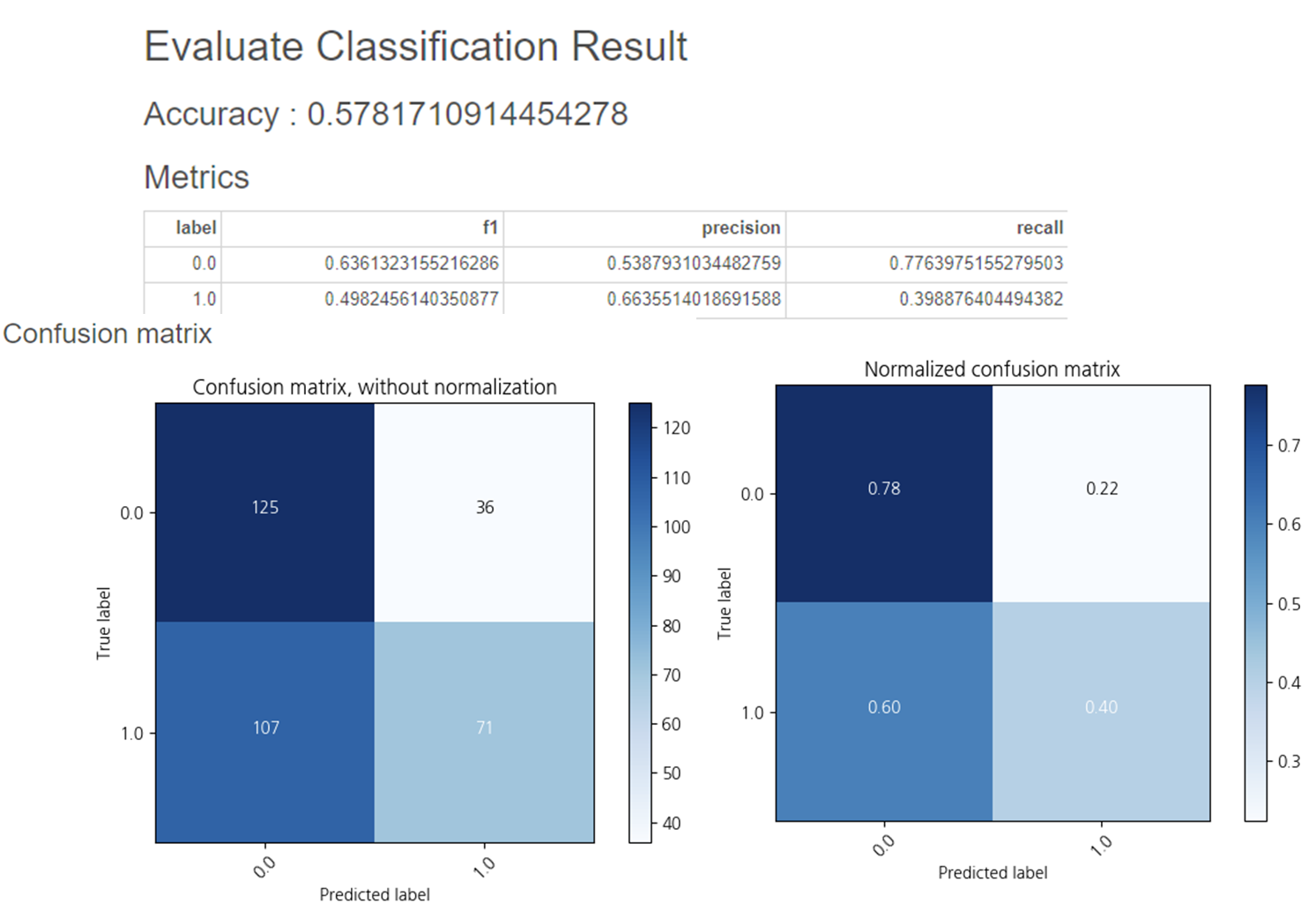
결과적으로
0.57의 정확도를 가지며
True label 1, Predicted label 0(오답)인 부분이 107개로
True label 1, Predicted label 1(정답)인 71개보다 더 높게 분류를 하였습니다.
이후 하이퍼파라미터를 조정할 때
True label 1, Predicted label 0(오답)이 줄어들 수 있는 방향으로 개선해보려합니다.
2-7. Naive Bayes


하이퍼파라미터를 조정하지 않고
Naive Bayes를 사용해보았습니다.
정확도가 0.57로
지금까지 가장 낯은 Linear Regression보다
더 낮은 정확도를 보이고 있습니다.
2-8. MLP
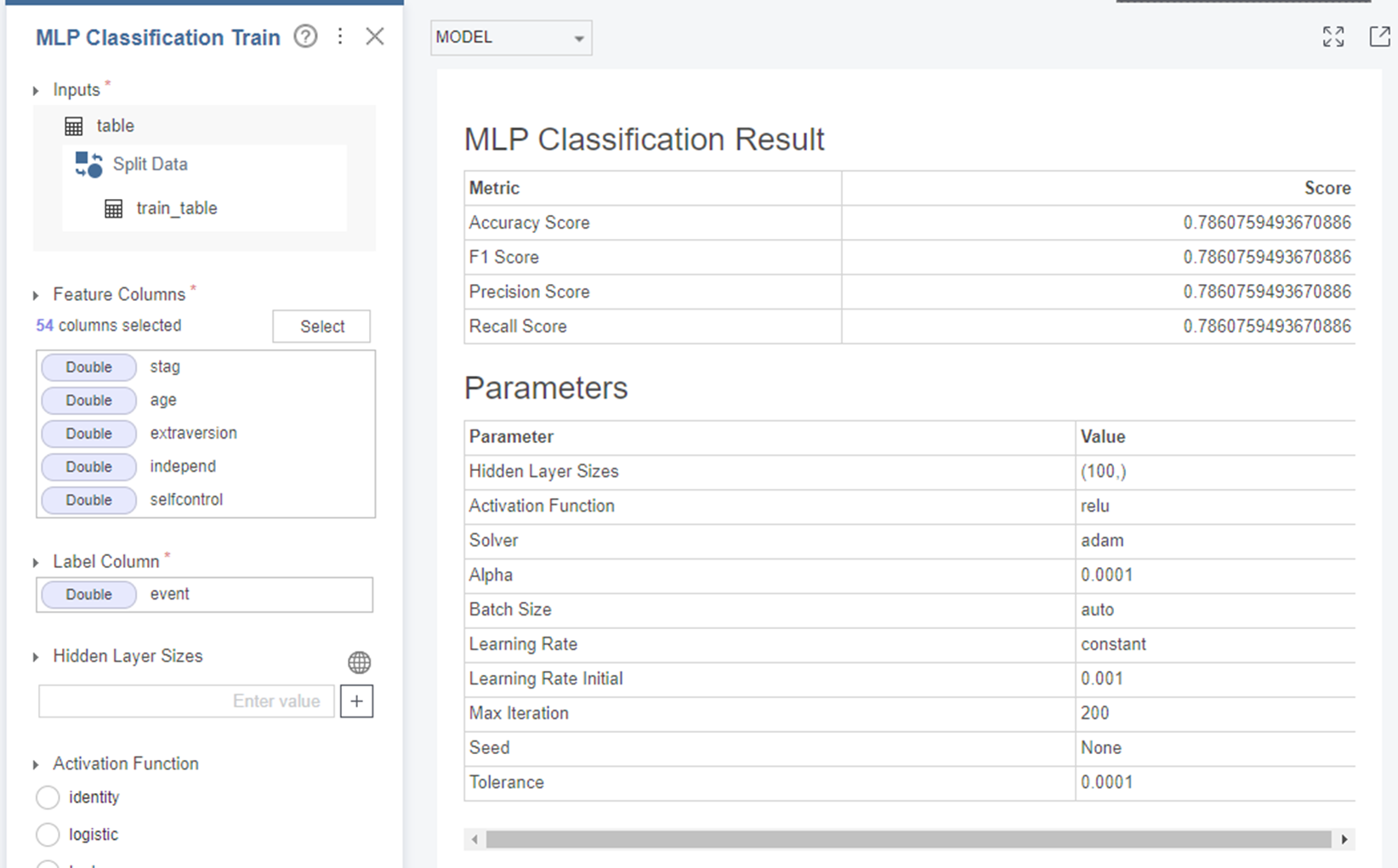
하이퍼파라미터를 조정하지 않고
MLP를 사용해보았습니다.
Train 데이터만 학습하였을 때
정확도는 0.78을 보이고 있었습니다.
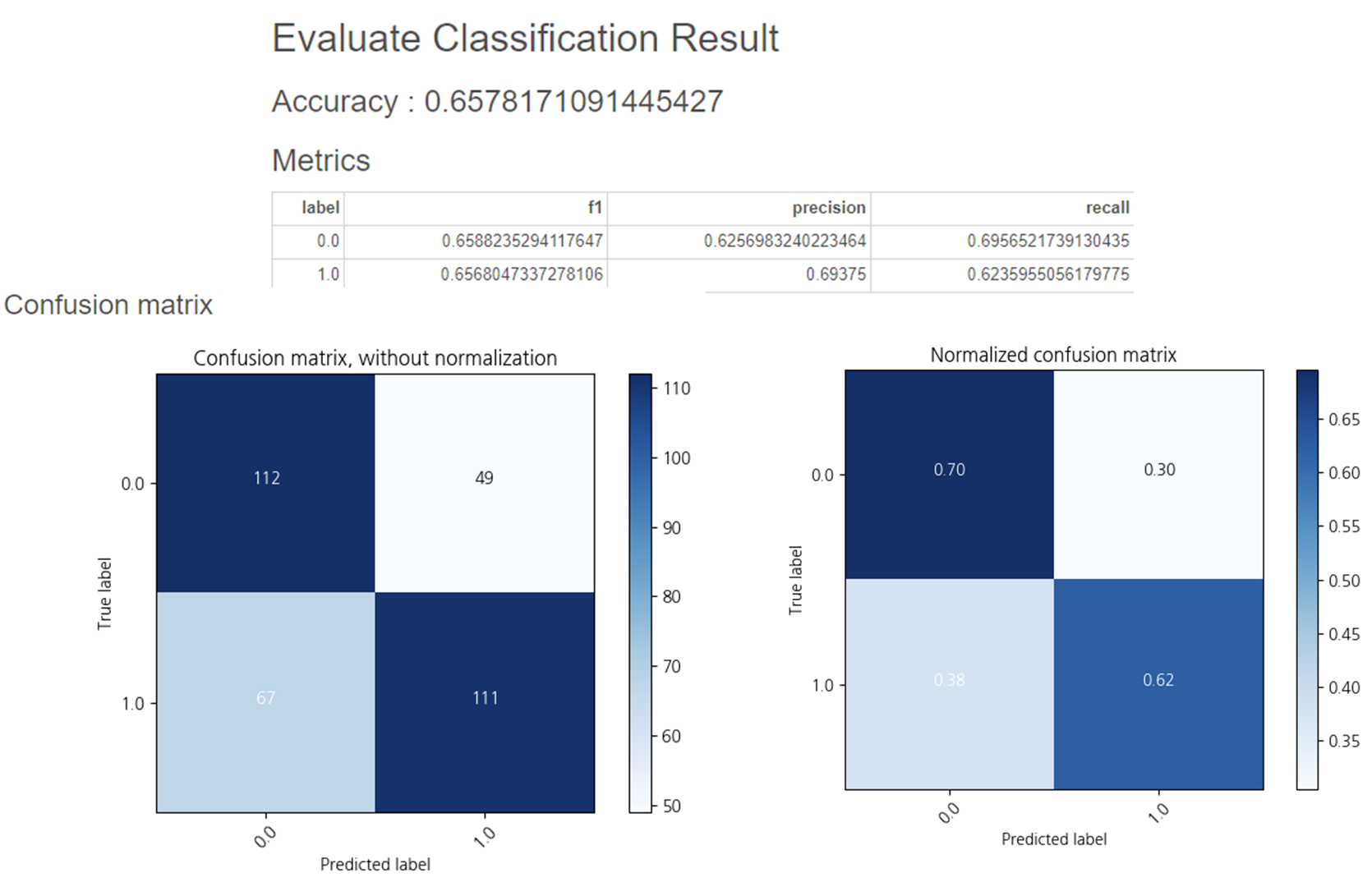
하지만 Test 데이터의 정확도는
0.65로 더 낮아졌습니다.
3. 번외
사실, 처음에는
category형 변수들을 인코딩하지 않고 모델링을 진행하였습니다.
인코딩 적용 후 모델링과 인코딩 적용 전 모델링을 비교하기 위해
번외편을 작성하게 되었습니다!
3-1. 인코딩을 진행하지 않은 Linear Regression
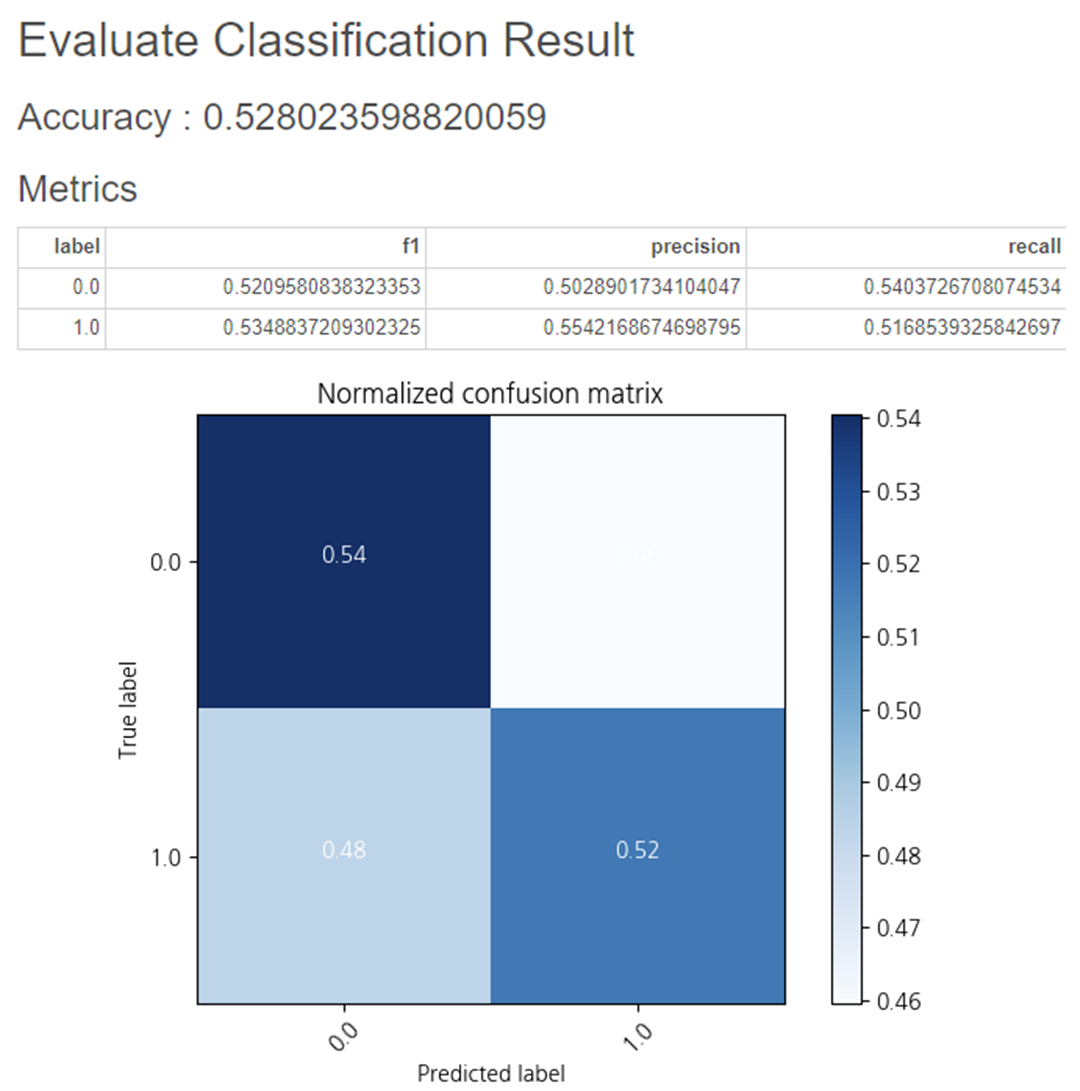
하이퍼파라미터를 조정하지 않은
Linear Regression 입니다.
정확도는 0.52로
인코딩을 진행한 Linear Regression의 정확도인 0.62보다 0.10 감소하였습니다.
3-2. 인코딩을 진행하지 않은 Decision Tree
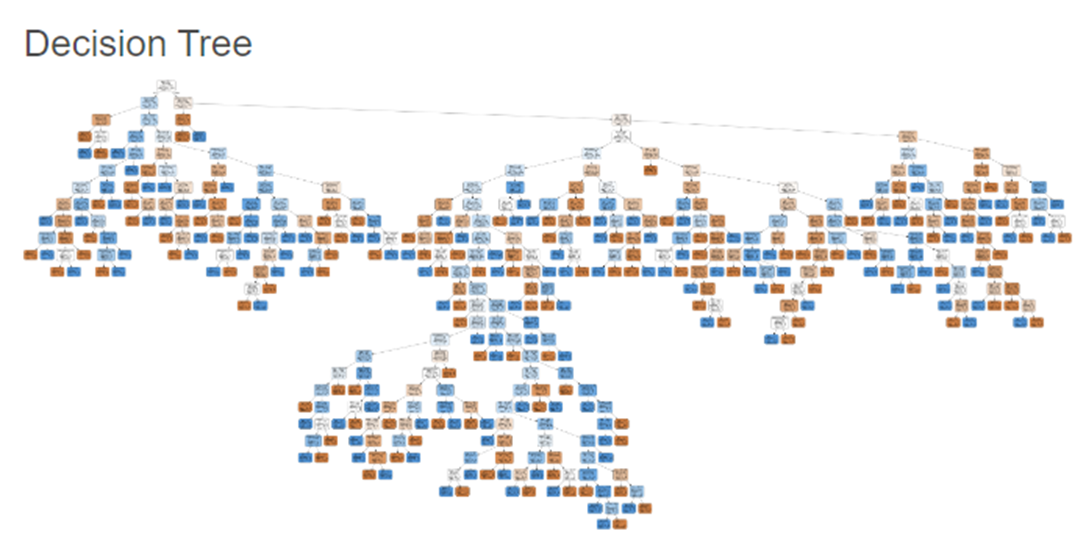
하이퍼파라미터를 조정하지 않은
Decision Tree 입니다!
인코딩을 진행한 Decision Tree보다
노드들이 더 많이 분기되어있습니다.
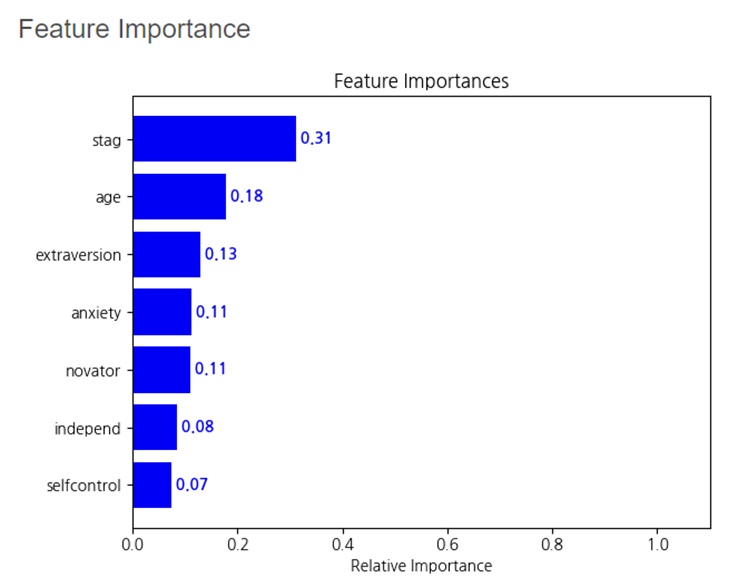
Feature Importance는
stag, age, extraversion 순서대로 중요함을 알 수 있었습니다.
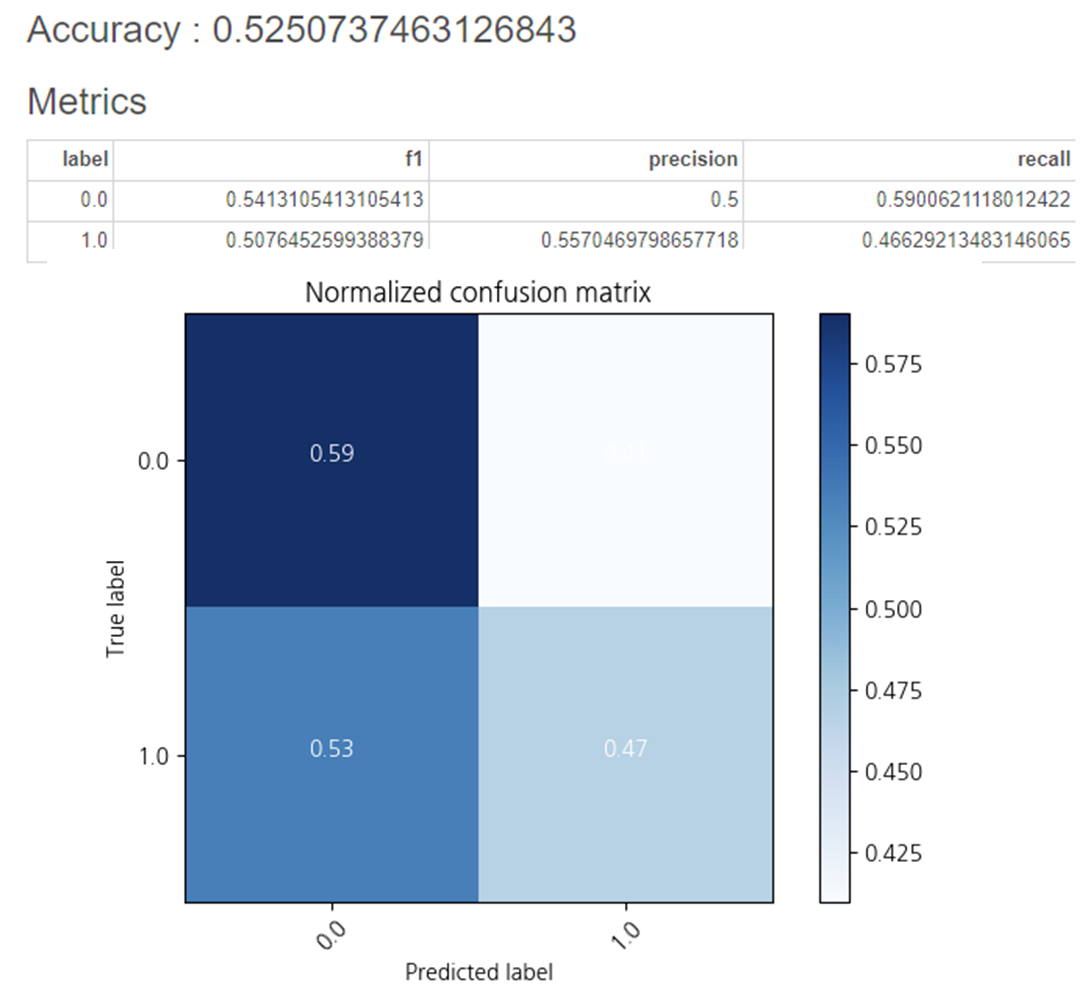
정확도는 0.52로
인코딩을 진행한 Decision Tree의 정확도인 0.66보다 0.14 감소하였습니다.
해당 과정을 통해
Category형 변수의 인코딩을 진행하지 않으면
모델링할 때 적용되지 않고
정확도가 더 낮아진다는 것을 확인할 수 있었습니다.
오늘은 데이터 전처리 인코딩과
하이퍼파라미터를 조정하지 않은 모델링을 진행하였습니다.
다음 포스팅에서는
하이퍼파라미터를 조정한 최적의 모델링과
그룹별로 모델링을 진행해보겠습니다.
다음 포스팅도 기대해 주세요:)
+
조원들과 함께 진행했던 프로젝트가
유튜브에 업로드 되었습니다!
국문판과 영문판 모두 많이 시청해주세요!
* 본 포스팅은 삼성 SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다 *



