
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 영상제작기
- 혼공머신러닝딥러닝
- 팀 분석
- 포스코 아카데미
- Brightics를 이용한 분석
- 직원 이직률
- 개인 의료비 예측
- 삼성SDS
- 삼성SDS Brightics
- Brightics Studio
- 데이터분석
- Brigthics Studio
- 모델링
- 브라이틱스 서포터즈
- 브라이틱스
- Brigthics를 이용한 분석
- 직원 이직여부
- 삼성SDS Brigthics
- 혼공
- 캐글
- 삼성 SDS Brigthics
- 혼공학습단
- 혼공머신
- 노코드AI
- Brightics
- 추천시스템
- 데이터 분석
- 포스코 청년
- 삼성 SDS
- Brigthics
- Today
- Total
데이터사이언스 기록기📚
[삼성 SDS Brightics 서포터즈] #08_팀 프로젝트_개인 의료비 예측(3) 본문
안녕하세요!
이번 포스팅은 팀 프로젝트 3번째 포스팅으로
팀프로젝트 분석 마지막 포스팅입니다!
이전 포스팅이 궁금하시다면 하단 링크를 클릭해주세요!
[삼성 SDS Brightics 서포터즈] #06_팀 프로젝트_개인 의료비 예측(1)
안녕하세요~! 오랜만에 돌아온 Brightics 서포터즈입니다! 이번 포스팅부터 약 7주간 팀 프로젝트를 진행하게 됩니다! 저희 팀의 프로젝트 궁금하지 않으신가요?!?! 이번 포스팅의 목차는 다음과 같
subinze.tistory.com
[삼성 SDS Brightics 서포터즈] #07_팀 프로젝트_개인 의료비 예측(2)
안녕하세요~! 두 번째 팀 프로젝트로 돌아온 Brightics 서포터즈입니다! 이전 포스팅에서는 데이터 분석 목적과 EDA 부분에 초점을 맞춰 포스팅을 진행하였습니다. 이전 포스팅이 궁금하시다면 아
subinze.tistory.com
이번 포스팅에서 제가 맡은 부분은
교차검증과 평가지표에 대한 설명과 결론부분입니다!
이번 포스팅의 목차는 다음과 같습니다!

그럼 이제부터 세번째 포스팅 시작하겠습니다!
1. 교차검증
1-1. 교차검증과 진행하는 이유
교차검증
교차검증은 CrossValidation으로
데이터를 1/N으로 나누어서
N-1개는 Train, 1개는 Test로 진행하여 모든 N개의 데이터가 Test가 되어
모델 학습할 때 모든 데이터를 Train과 Test로 교차하여 선택하고
학습 및 검증하는 방법입니다!

교차검증을 진행하는 이유
흔히 알고있는 Train과 Test로 나누어
Train set은 모델 학습으로
Test set은 모델 검증 및 결과 도출로 사용하는 경우가 있는데
왜 교차검증을 진행하는지 의문을 가지고 계실 수 있습니다.
일반적인 Train, Test 방법을 이용하여 고정된 Test set을 통해 검증하게되면
현재 만든 Test set에만 잘 적용이 되는 모델을 제작하게 됩니다.
즉, 과적합을 만들게되어 다른 데이터셋을 이용하여 검증하게되면 성능이 낮아지는 현상을 겪게됩니다!
이를 방지하기 위한 방법으로
교차검증을 사용하게되며
교차검증 사용 시
편향된 데이터 학습을 막을 수 있습니다!
1-2. 교차검증의 장단점
| 장점 | 단점 |
| 데이터 셋이 적을 때 과소적합 방지 | 반복 횟수가 증가하여 모델 훈련 및 평가시간 증가 |
| 특정 데이터셋에 대한 과적합 방지 | |
| 편향된 데이터 학습 방지 |
교차검증의 장단점은 간략하게 다음과 같습니다.
1-3. GridSearchCV
앞서 교차검증에대해 설명을 드린 이유는
저희 조는 모델을 돌리면서 GridSearchCV를 사용했기 때문입니다!
GridSearchCV가 어떤거지???
궁금해하시는 분들을 위해 설명드리겠습니다.
GridSearch는 사용자가 직접 모델의 하이퍼파라미터를 리스트의 범위로 입력하면
작성한 리스트의 모든 경우의 수를 탐색하여
최적의 하이퍼파리미터 값을 찾는 과정을 말합니다.
CV는 앞서 말씀드렸던 CrossValidation, 교차검증입니다.
GridSearchCV를 이용하실 때 주의하셔야할 점은 다음과 같습니다.
- 리스트 안에 지정해 준 값이 많을 수록 시간이 오래걸린다.
- 리스트 안에 있는 값들만 탐색하므로 다른 값을 탐색하고 싶을때는 리스트 안의 값을 바꿔야한다.
1-4. GridSearchCV 사용한 이유
저희 조는 GridSearchCV를 통해 모델에 따른 최적화된 파라미터를 찾고
모델의 평가지표를 이용하여 비교해보았습니다.
2. 성능평가지표
저희 조는 '개인 의료비 예측'으로
'회귀'모델을 이용한 평가지표를 사용하게 되었습니다.
회귀모델을 이용한 평가지표는 다양한데요
저희 조는 그 중 MAE, MAPE, R2를 평가지표로 선정하였습니다!
각각의 설명 및 특징에 대해 알아볼까요?
MAE
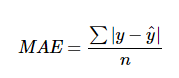
MAE는 Mean Absolute Error로
모델의 실제값(y)과 예측값(y^) 의 차이를 모두 더해 샘플 숫자(n)로 나눈 개념입니다.
'Error'를 포함한 개념으로 MAE가 낮을 수록 성능이 좋은 모델입니다!
MAE의 장점은
- 정답 및 예측값과 같은 단위를 가진다.
- MSE보다 이상치에 덜 예민하다.
MAE의 단점은
- 절댓값을 취해서 모델이 실제보다 낮은값으로 예측했는지, 높은 값으로 예측했는지 알 수 없다.
- 스케일 의존적이다.(모델마다 에러 크기가 동일해도 에러율은 동일하지 않음)
MAPE
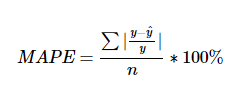
MAPE는 Mean Absolute Percentage Error로
MAE를 퍼센트로 변환한 개념입니다.
'Error'를 포함한 개념으로 MAPE가 낮을 수록 성능이 좋은 모델입니다!
MAPE의 장점은
- MAE와 마찬가지로 MSE보다 이상치에 덜 예민하다.
- 다른 모델과 에러율 비교가 쉽다.
- 스케일 의존의 에러 문제점을 개선
MAPE의 단점은
- 절댓값을 취해서 모델이 실제보다 낮은값으로 예측했는지, 높은 값으로 예측했는지 알 수 없다.
- 모델에 대한 편향이 존재한다.
R2
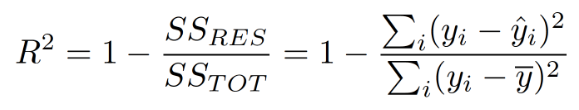
R2는 Coefficient of Determination으로
상대적으로 얼마나 성능이 나오는지 측정하는 지표입니다.
R2은 1에서 Error 값을 제거하는 형식이어서
1에 가까울 수록 성능이 좋습니다!
R2의 장점은
- scale에 영향을 받지 않는 상대적 성능이라 직관적으로 판단할 수 있다.
평가지표의 특징을 살펴보면서
저희가 왜 해당 지표를 프로젝트 평가지표로 사용하였는지 설명드리겠습니다!
MAE : 이상치에 민감하지 않아 선정
MAPE : 다른 모델과 에러율 비교가 쉬워서 선정
R2 : 상대적인 성능으로 비교하기 쉬워서 선정
저희가 선정한 3가지 지표를 토대로 팀프로젝트 분석 결론에 대해 설명드리고자합니다!
3. 결론
저희 조는
전체 모델을 돌려 의료비를 예측하는 것과
성별에 따라 의료비를 예측하는 방법 두 가지로 나누어 진행하였습니다.
먼저 전체 모델에 관련된 결론을 살펴볼까요?
3-1. 전체 모델에 따른 의료비 예측
자세한 내용은 하단의 팀원들 포스팅에서 확인해보실 수 있습니다!
🔽전체 모델 의료비 예측 - RandomForest, AdaBoost🔽
[삼성 SDS Brightics] 개인 의료비 예측(3)
안녕하세요.ㅎㅎ Brightics 서포터즈 3기 정민경입니다. 팀미션 마지막이에요! 사실 저번주에 멘토분들의 피드백을 받고 분석과정을 좀 더 변형해서 진행하였는데요, 확실히 함께하니까 내용이 더
inhye-like.tistory.com
🔽전체 모델 의료비 예측 - Decision Tree, XGB🔽
[삼성 SDS Brightics] #4_개인 의료비 예측 프로젝트💊_(의사결정은 나무로 해야 제맛이죠~)
하염! Brighics 서포터즈 3기 수망입니다! 오늘은 저저번주 포스팅부터 시작했던 개인 의료비 예측 프로젝트에서 모델링을 해보는 날이에요!!!! 지금 이 포스팅을 읽고 계시는 분덜, 혹시 제 팀
soomang.tistory.com
평가지표에 대한 결과는 다음과 같습니다!
| 모델구성 | 구분 | R-squared | MAE | MAPE |
| Linear Regression | - | 0.7552 | 0.2878 | 3.1343 |
| RandomForest Regression |
Train | 0.8426 | 2788.7546 | 38.3939 |
| GridSearchCV | 0.8622 | 2776.2132 | 34.3441 | |
| AdaBoost Regression |
Train | 0.8395 | 3900.8289 | 65.1139 |
| GridSearchCV | 0.8527 | 2998.3076 | 36.3278 | |
| DecisionTree Regression |
Train | 0.6649 | 3437.3757 | 56.4213 |
| GridSearchCV | 0.8395 | 3243.4083 | 39.4671 | |
| XGBoost Regression |
Train | 0.8805 | 2455.0297 | 31.8088 |
| GridSearchCV | 0.8511 | 2893.5439 | 33.1910 |
평가지표를 확인해보니
R-square값은 XGBoost Regression Train이 성능이 가장 좋고
MAE, MAPE값은 Linear Regression이 성능이 가장 좋은 것으로 확인되었습니다!
R-squared는 상대적 성능을 비교하는 것이라
R-squared 값이 낮은 XGBoost Regression을 최종 모델로 선정하였습니다!
XGBoost Regression 모델을 확인해 본 결과
Bmi 0.39, Age 0.28, Chlidren 0.14, Smoker_y10n 0.09의 변수 중요도를 확인할 수 있었습니다.
이에따라
사람들은 Bmi, Age, Chlidren, Smoker_y10n 순서대로 의료비가 많이 부가되는 것을 확인할 수 있었습니다.
3-2. 성별에 따른 의료비 예측
자세한 내용은 하단의 팀원들 포스팅에서 확인해보실 수 있습니다!
🔽성별에 따른 의료비 예측 - Linear, RandomForest, AdaBoost🔽
[삼성 SDS Brightics]# 03-3. 팀프로젝트(3) 의료비(보험비) 예측
안녕하세요! 브라이틱스 서포터즈 3기 서영석입니다! 이번에는 팀 프로젝트의 세번째 진행에 대한 포스팅을 가져왔습니다! 이번 포스팅의 경우, 모델의 구성과 평가지표 위주로 하여 최적의 모
honeyofdata.tistory.com
🔽성별에 따른 의료비 예측 - Decision Tree, XGB🔽
삼성 SDS Brightics_팀 분석 프로젝트(3)] 07. 개인 의료비🏥 예측 프로젝트✨ (Decision Tree & XGBoost Regres
안녕하세요~ 이번 주가 벌써 팀 프로젝트 3주 차네요! 지난 포스팅을 보지 못하셨다면...! 📍팀 분석 프로젝트(1)-전처리 & EDA https://blog.naver.com/noonddudung2/222849341179 📍팀 분석 프..
noonddudung2.tistory.com
평가지표에 대한 결과는 다음과 같습니다!
<Male>
| 남자 모델구성 | 구분 | R-squared | MAE | MAPE |
| Linear Regression | - | 0.7940 | 0.3022 | 3.3034 |
| RandomForest Regression |
Train | 0.8596 | 2914.2939 | 34.4022 |
| GridSearchCV | 0.8880 | 2408.1813 | 28.6256 | |
| AdaBoost Regression |
Train | 0.8380 | 4491.3278 | 91.6623 |
| GridSearchCV | 0.8883 | 2566.0762 | 32.6333 | |
| DecisionTree Regression |
Train | 0.7636 | 3378.2611 | 32.5279 |
| GridSearchCV | 0.8679 | 3118.2286 | 34.2621 | |
| XGBoost Regression |
Train | 0.8796 | 2562.6684 | 31.3736 |
| GridSearchCV | 0.8560 | 3464.2745 | 50.8212 |
<Female>
| 여자 모델구성 | 구분 | R-squared | MAE | MAPE |
| Linear Regression | - | 0.8018 | 0.2233 | 2.4197 |
| RandomForest Regression |
Train | 0.8023 | 2942.9722 | 31.5469 |
| GridSearchCV | 0.8075 | 2750.8612 | 25.4132 | |
| AdaBoost Regression |
Train | 0.7818 | 4518.3908 | 68.1321 |
| GridSearchCV | 0.8000 | 2859.7498 | 28.6167 | |
| DecisionTree Regression |
Train | 0.6281 | 3393.6735 | 35.7606 |
| GridSearchCV | 0.5878 | 4952.7778 | 46.1039 | |
| XGBoost Regression |
Train | 0.8402 | 2535.7157 | 27.1813 |
| GridSearchCV | 0.8063 | 2621.4972 | 23.6831 |
평가지표를 확인해보니
여상,남성 모두 R-square값은 XGBoost Regression Train이 성능이 가장 좋고
여성, 남성 모두 MAE, MAPE값은 Linear Regression이 성능이 가장 좋은 것으로 확인되었습니다!
R-squared는 상대적 성능을 비교하는 것이라
R-square값이 낮은 XGBoost Regression을 최종 모델로 선정하였습니다!
XGBoost Regression 모델을 확인해 본 결과
Male은 Bmi 0.44, Age 0.33, Chlidren 0.10, Smoker_y10n 0.07의 변수 중요도를 확인할 수 있었습니다.
Female은 Bmi 0.42, Age 0.34, Smoker_y10n 0.08, Chlidren 0.08의 변수 중요도를 확인할 수 있었습니다.
이에따라
남성의 의료비는 여성보다 자녀의 부양자수에 의해 의료비가 더 많이 부가되는 것을 알 수 있었고
여성의 의료비는 흡연 여부와 자녀 부양자수에 의해 의료비가 더 많이 부가되는 것을 확인할 수 있었습니다!
이전에 저희가 프로젝트 진행 목적으로 언급했던

해당 분석을 통해 얻는 결론으로
보험료 변화는 여성, 남성 구분 없이
Bmi, Age, Chlidren, smoker_y10n를 기준으로 맞춤형 상품을 기획할 수 있을 것으로 예상됩니다.
이로써 팀프로젝트 분석이 마무리 되었습니다!
3주동안 팀원들과 함께 프로젝트를 진행하면서
부족한 부분은 서로 채워주고
필요한 부분은 적극적으로 도와주어서
프로젝트가 수월하게 끝난것 같습니다~
또한 개인프로젝트에서는 보이지 않았던 부분들이
다방면으로 팀원들이 하나씩 살펴보면서
'새로운 관점으로도 바라볼 수 있구나!' 라는 점을 많이 느꼈습니다!
개인적으로는
매번 EDA만 확인하고 통계검정을 건너 뛴 채 분석을 시작했었는데
멘토님 덕분에 통계검정을 어떻게 사용하고 적용해야하는지 배울 수 있는 기회여서 감사했습니다ㅎㅎ
다음주는 분석한 팀 프로젝트를 기반으로
영상 제작 포스팅으로 돌아오겠습니다 :)
* 본 포스팅은 삼성 SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다 *
'대외활동 > 삼성SDS Brightics 서포터즈' 카테고리의 다른 글
| [삼성 SDS Brightics 서포터즈] #10_팀 프로젝트_영상 제작기① (0) | 2022.09.15 |
|---|---|
| [삼성 SDS Brightics 서포터즈] #09_팀 프로젝트_개인 의료비 예측(4) (1) | 2022.09.06 |
| [삼성 SDS Brightics 서포터즈] #07_팀 프로젝트_개인 의료비 예측(2) (0) | 2022.08.23 |
| [삼성 SDS Brightics 서포터즈] #06_팀 프로젝트_개인 의료비 예측(1) (0) | 2022.08.16 |
| [삼성 SDS Brightics 서포터즈] #05_개인 프로젝트(1) 고객 성격 분석_데이터 전처리(2), 모델링, 분석 (0) | 2022.07.12 |


