
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 삼성SDS
- 영상제작기
- 캐글
- 직원 이직률
- 데이터 분석
- 팀 분석
- 혼공머신러닝딥러닝
- 추천시스템
- 삼성SDS Brigthics
- Brigthics를 이용한 분석
- 데이터분석
- 혼공학습단
- Brightics를 이용한 분석
- 포스코 청년
- Brightics
- Brightics Studio
- Brigthics
- Brigthics Studio
- 노코드AI
- 혼공
- 포스코 아카데미
- 직원 이직여부
- 삼성 SDS
- 브라이틱스 서포터즈
- 삼성 SDS Brigthics
- 혼공머신
- 브라이틱스
- 삼성SDS Brightics
- 모델링
- 개인 의료비 예측
- Today
- Total
데이터사이언스 기록기📚
[삼성 SDS Brightics 서포터즈] #06_팀 프로젝트_개인 의료비 예측(1) 본문
안녕하세요~!
오랜만에 돌아온 Brightics 서포터즈입니다!
이번 포스팅부터 약 7주간 팀 프로젝트를 진행하게 됩니다!
저희 팀의 프로젝트 궁금하지 않으신가요?!?!
이번 포스팅의 목차는 다음과 같이 진행됩니다!

그럼 바로!!
팀 프로젝트 첫 번째 포스팅 시작하겠습니다!
1. 팀 이름 및 프로젝트 선정
1-1. 팀 이름
저희는 팀을 한눈에 알아볼 수 있는 이름을 지으면 좋겠다고 생각해서
팀 명을 먼저 정해보았습니다!
팀 명은 바로바로....!!!!
.
.
.
HI:FIVE입니다!
HI는 높이 올라가자는 의미를 담고 있고
FIVE는 5명의 팀원, 5조의 의미를 담고 있습니다!
1-2. 프로젝트 선정 배경
OECD Health Statistics 2020 통계에 따르면
우리나라뿐만 아니라
독일, 미국, 호주 등
1인당 의료비가 증가하는 것을 확인할 수 있었습니다.
이에 따라 저희 팀은
의료비 부분에 초점을 맞춰 프로젝트를 선정하였습니다.
1-3. 프로젝트 목적
저희 팀의 프로젝트 목적은 다음과 같습니다.
사회적 ∙ 신체적 개인정보를 기반으로 하는 의료비 예측을 통해,
개인은 본인의 의료비를 직접 예측하여 과납을 막고 그에 상응하는 보험금을 납부한다.
또한 보험회사는 보험료 변화 추세를 파악하여, 그에 따른 맞춤형 상품을 기획한다.
다음과 같은 세부 목적을 설정하였고 이후
목적에 알맞은 데이터를 찾아보았습니다!
2. 데이터셋
2-1. 데이터셋 선정
저희 팀은
'어떻게 하면 각자의 역량을 빛내어 팀 프로젝트를 완수할 수 있을까?'
대한 내용에 초점을 맞춰 데이터를 선정해 보았습니다!
다양한 데이터 후보에 대한 논의가 있었지만
최종 선정된 데이터셋은.....!
바로!!!!!
Medical Cost Personal Datasets
Insurance Forecast by using Linear Regression
www.kaggle.com
상단에 있는
'개인 의료비 관련 데이터셋'
(Medical Cost Personal Datasets)
으로 선정하였습니다!
2-2. 데이터셋 설명
저희가 사용하려고 하는 데이터셋은 총 7개의 칼럼으로 구성되어 있습니다.
| 칼럼 명 | 칼럼 설명 |
| Age | 보험 계약자(User)의 나이 |
| Sex | 보험 계약자(User) 성별(여성, 남성) |
| Bmi | 체질량 지수 |
| Children | 건강보험 적용 자녀 수/ 피보양자 수 |
| Smoker | 흡연 여부 |
| Region | 미국 수혜자(User) 주거 지역(북동쪽, 남동쪽, 남서쪽, 북서쪽) |
| Charges | 건강보험에서 청구하는 개별 의료비 |
다음과 같은 칼럼으로 구성되어 있으며
X지표는 Age, Sex, Bmi, Children, Smoker, Region을 지정하였고
Y지표는 Charges를 지정하여
분석 최종 목적은
'개인이 납부할 의료비(Charges) 예측'
으로 선정하였습니다.
3. EDA
저희는 EDA를 통해
데이터셋이 어떻게 구성되어 있는지,
칼럼 간에 어떤 관계가 있는지
파악해보았습니다!
3-1. 데이터 확인
데이터를 시각화하기 앞서,
Brightics Studio의 Profile Table 함수를 이용하여
전반적인 데이터 분포를 확인해보았습니다!
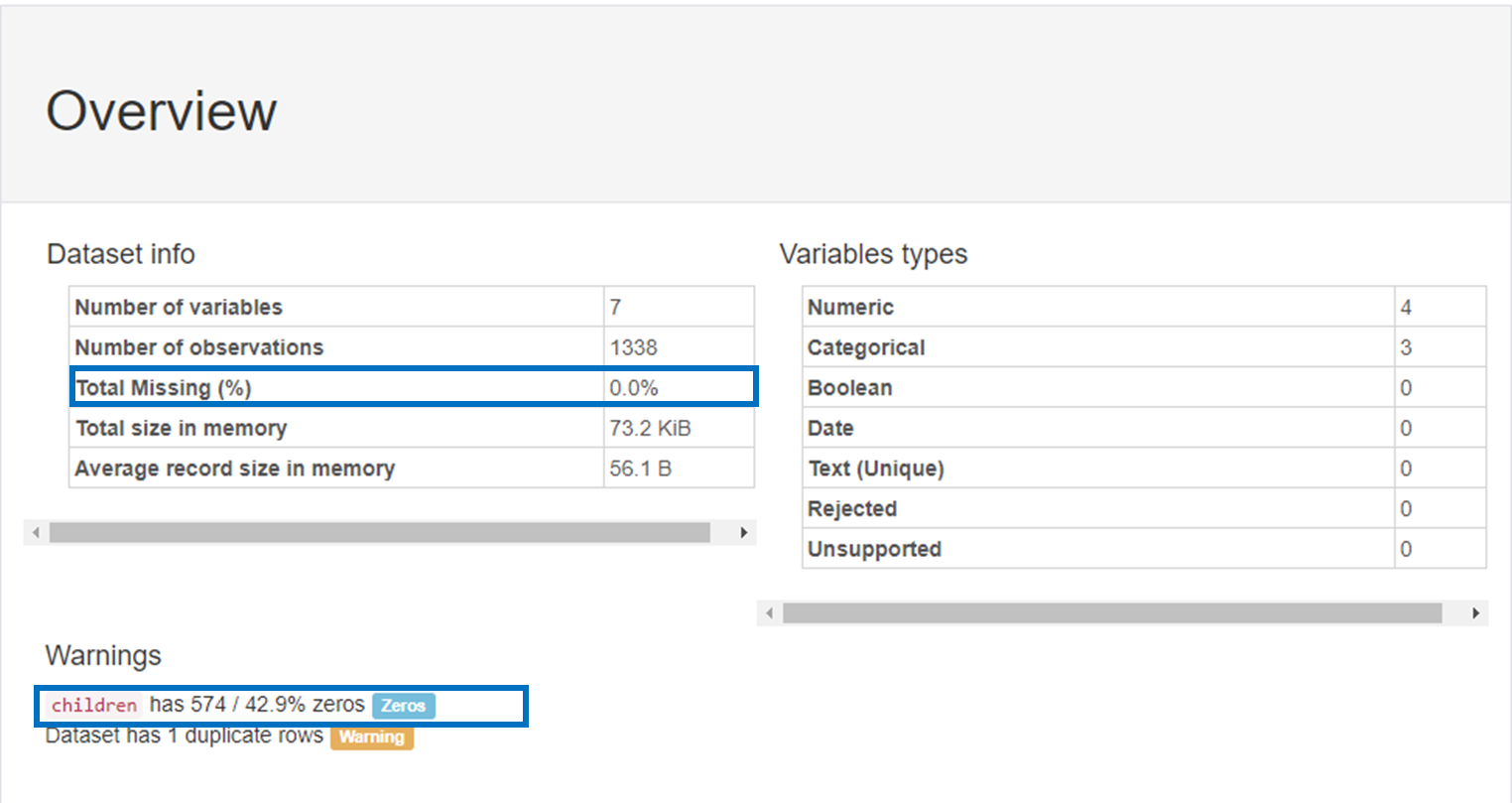
Overview의
Dataset info를 확인해본 결과,
데이터 셋의 결측치(Total Missing) 부분은 없는 것을 확인할 수 있었습니다!
Warnings 부분에서는
children에 0이 42.9% 있는 것을 확인해 볼 수 있는데
이는 자녀가 0명인 경우가 다수 있을 수 있다고 판단하여
신경 쓰지 않아도 됨을 파악할 수 있었습니다!

다음은 Correlations를 확인해보았습니다!
Pearson과 Spearman 두 가지 방법 모두 확인해본 결과
age와 charges가 변수 상관관계가 높은 것을 확인할 수 있었습니다!
3-2. 단일 EDA
다음은 하나의 칼럼만을 이용하여
EDA를 진행해보았습니다!
1) Age
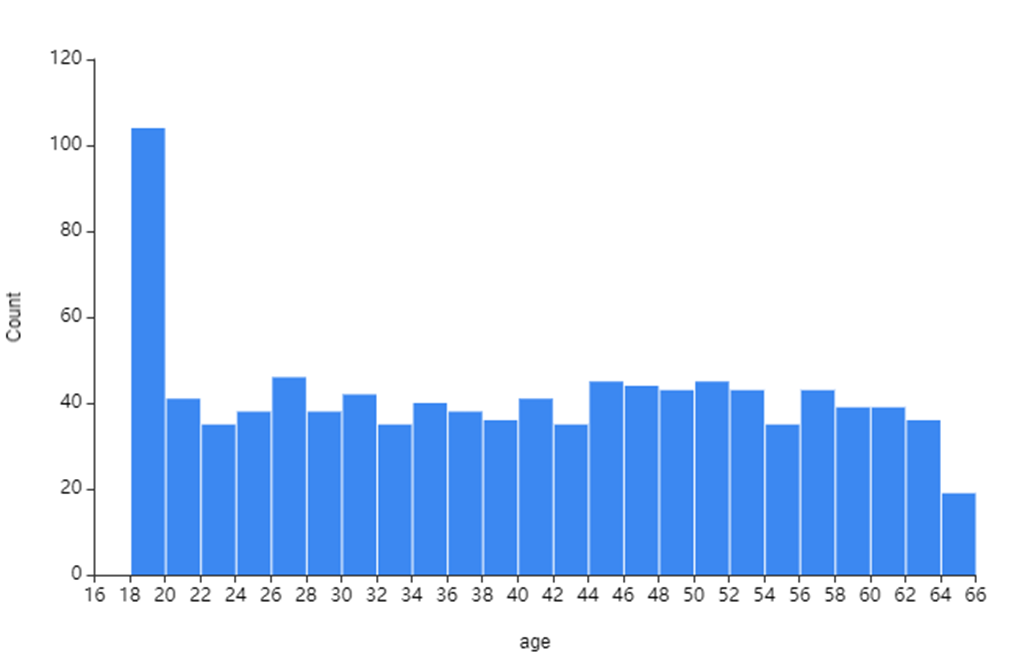
데이터셋의 Age 분포를 확인해보았습니다!
Age는 18세~66세 사이로 구성이 되어있었습니다.
하지만 Age 분포가 한눈에 안 들어온다고 판단하여
Age_group 변수를 생성하여
나이대별로 시각화를 해보았습니다!
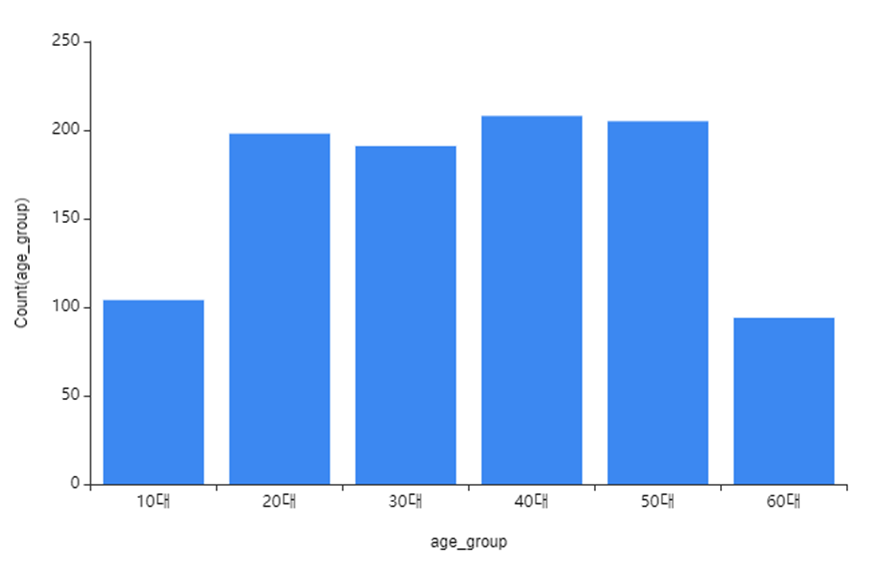
Age_group 시각화를 확인해 보니
10대, 60대 분포가 가장 적었고
40대가 가장 많았으며
20대~50대는 비슷한 분포인 것을 확인할 수 있었습니다!
2) Sex
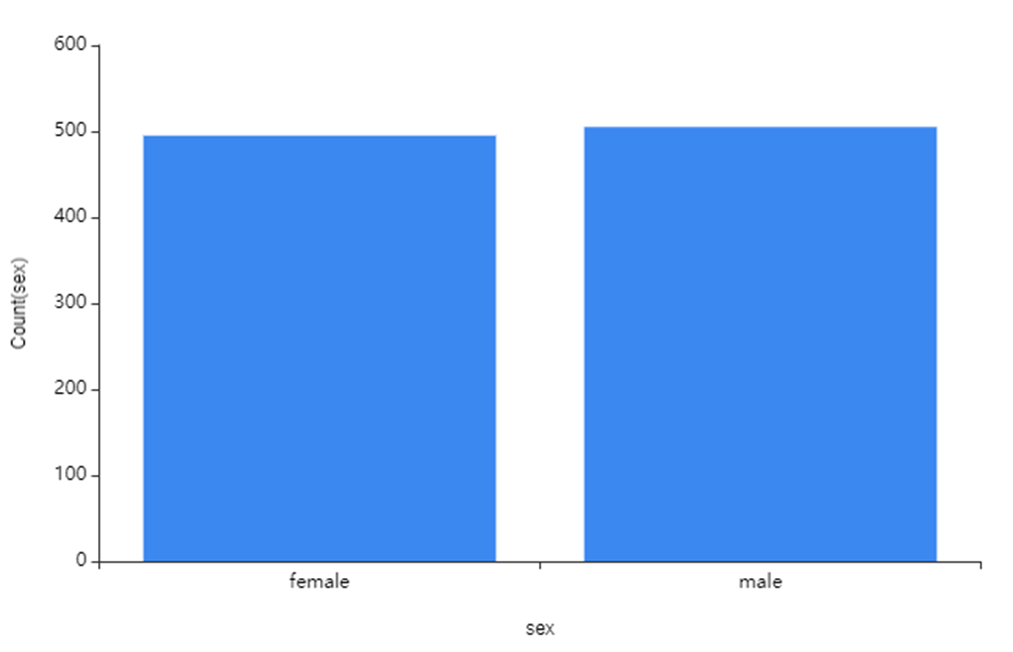
남성의 비율이 약간 높았지만
여성, 남성의 비율은 비슷한 것을 확인할 수 있었습니다!
3) Children
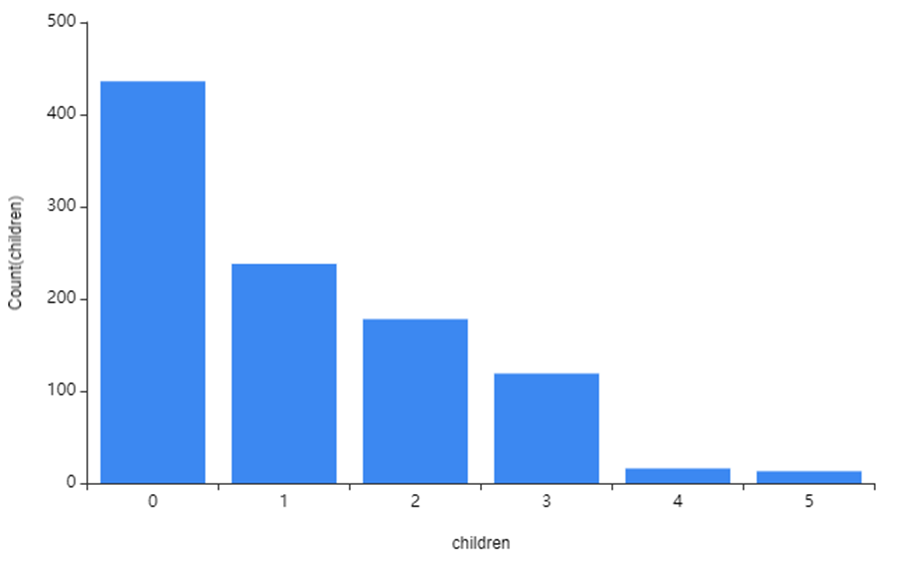
자녀 수는
0~5까지 있었으며
0명이 가장 많은 것을 확인할 수 있었습니다!
4) Smoker

흡연하지 않은 사람이 800명 정도로
비흡연자 : 흡연자 = 4 :1
비율인 것을 확인할 수 있었습니다!
5) Region
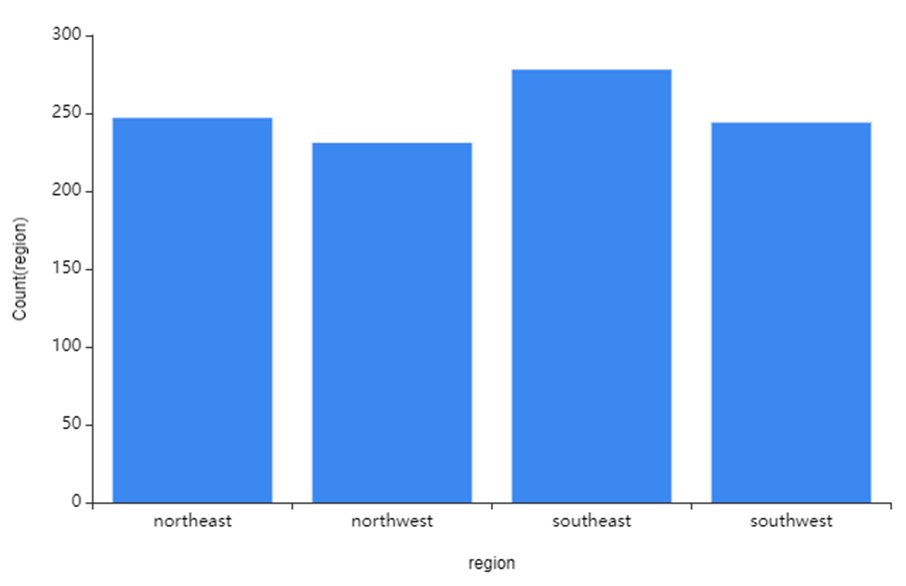
해당 그래프를 통해
southeast - northeast - southwest - northwest 순서대로
많이 거주하는 것을 확인할 수 있었습니다!
3-3. 복합 EDA
이번에는 2개 이상의 칼럼을 가지고
시각화를 진행해보았습니다!
1) Charges
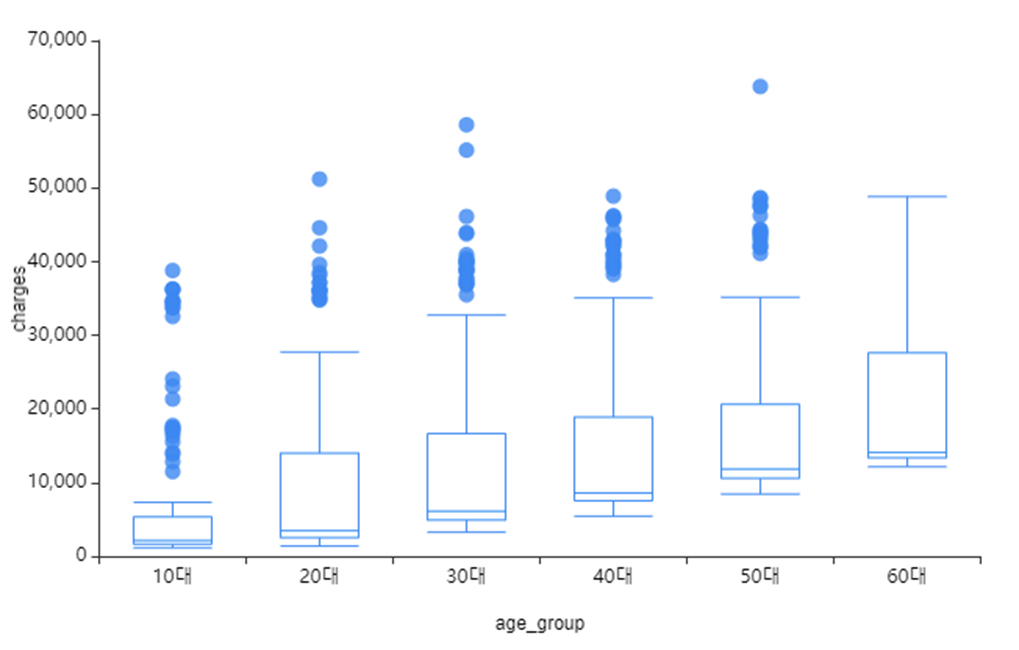
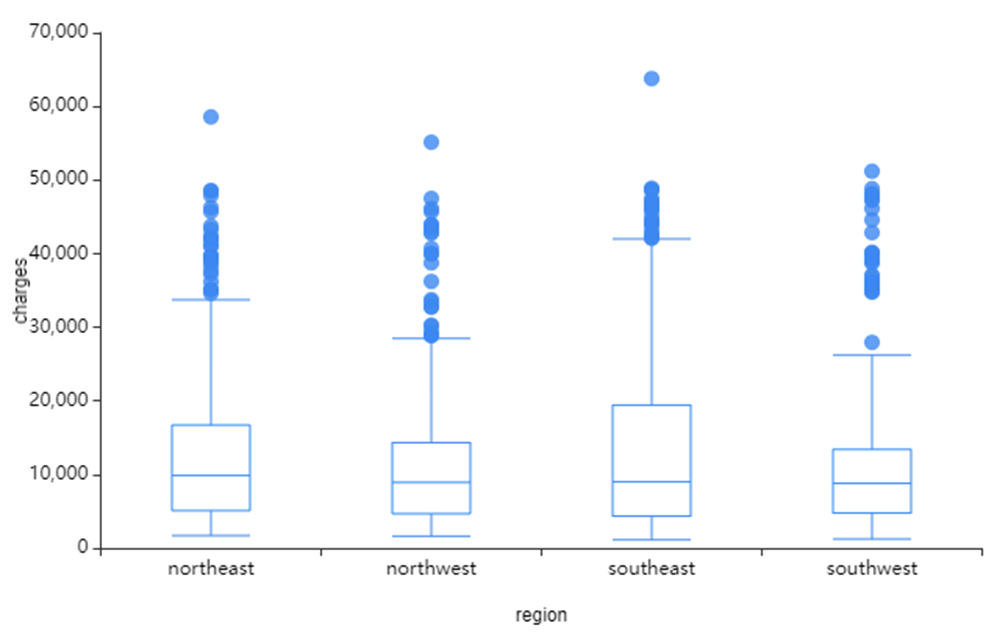
왼쪽 사진은 age_group과 charges의 시각화,
오른쪽 사진은 region과 charhges의 시각화를 진행하였습니다!
age_group이 커질수록 charges는 점차 올라갔으며
10대에서 이상치가 많은 것을 확인할 수 있었습니다.
region은 east 지방 쪽이 charges가 폭넓게 분포된 것을 확인할 수 있었으며
이상치는 west 지방에서 많다는 것을 확인할 수 있었습니다.
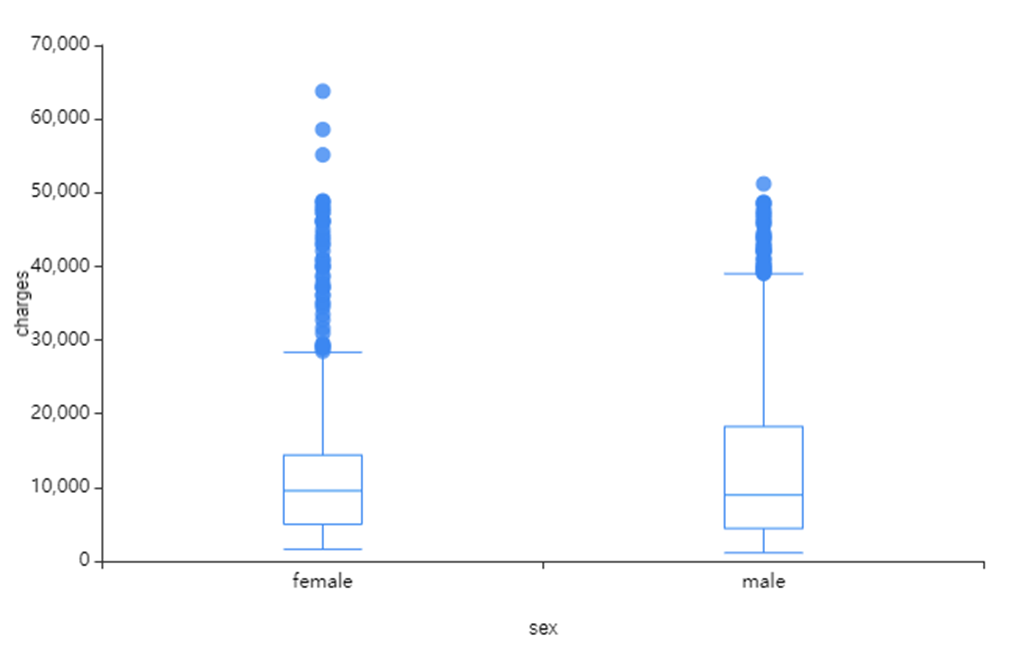
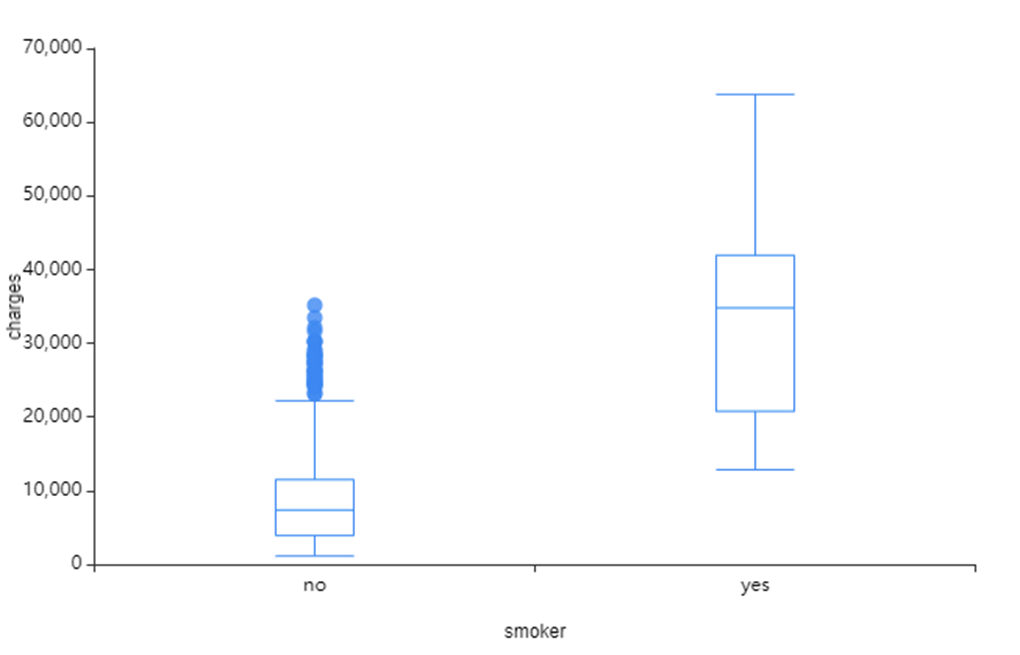
왼쪽 사진은 sex와 charges의 시각화,
오른쪽 사진은 smoker와 charhges의 시각화를 진행하였습니다!
sex는 남성의 charges가 폭 넓게 분포된 것을 확인할 수 있었으며
이상치는 여성이 많은 것을 확인할 수 있었습니다.
smoker는 흡연자가 charges가 비흡연자보다 많다는 것을 확인할 수 있었으며
이상치는 비흡연자가 많은 것을 확인할 수 있었습니다.
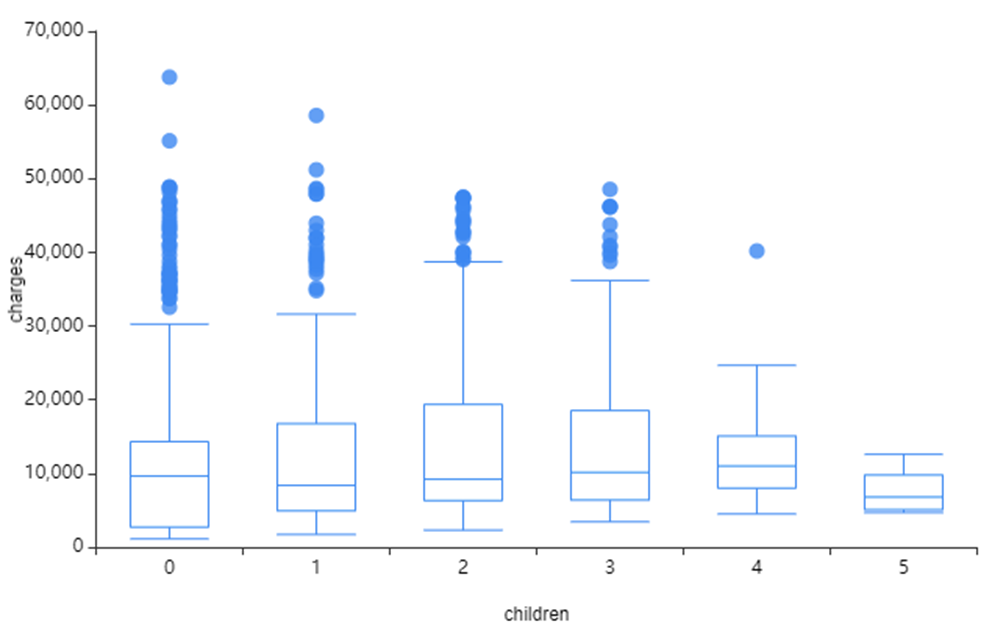
상단 사진은 children과 charhges의 시각화를 진행하였습니다!
children 수가 적을수록
이상치가 많다는 것을 확인할 수 있었습니다.
2) BMI

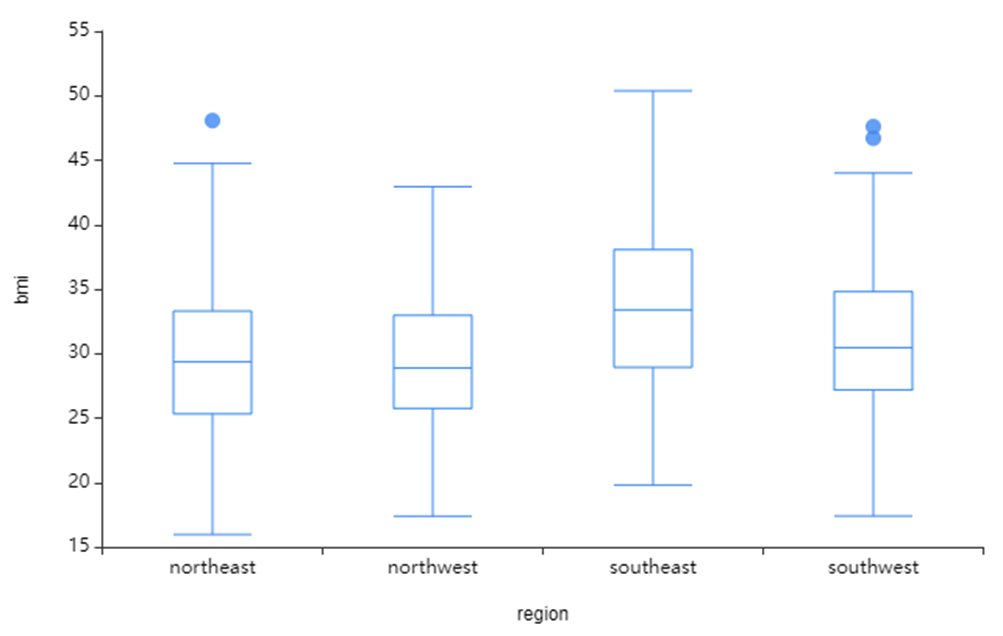
왼쪽 사진은 age_group과 BMI의 시각화,
오른쪽 사진은 region과 BMI의 시각화를 진행하였습니다!
age_group과 BMI 지수는 범주 차이는 약간씩 있지만
큰 차이가 없는 것을 확인할 수 있었습니다.
region은 southeast 쪽이 다른 지역보다 BMI 지수가 높은 것을 확인할 수 있었습니다.
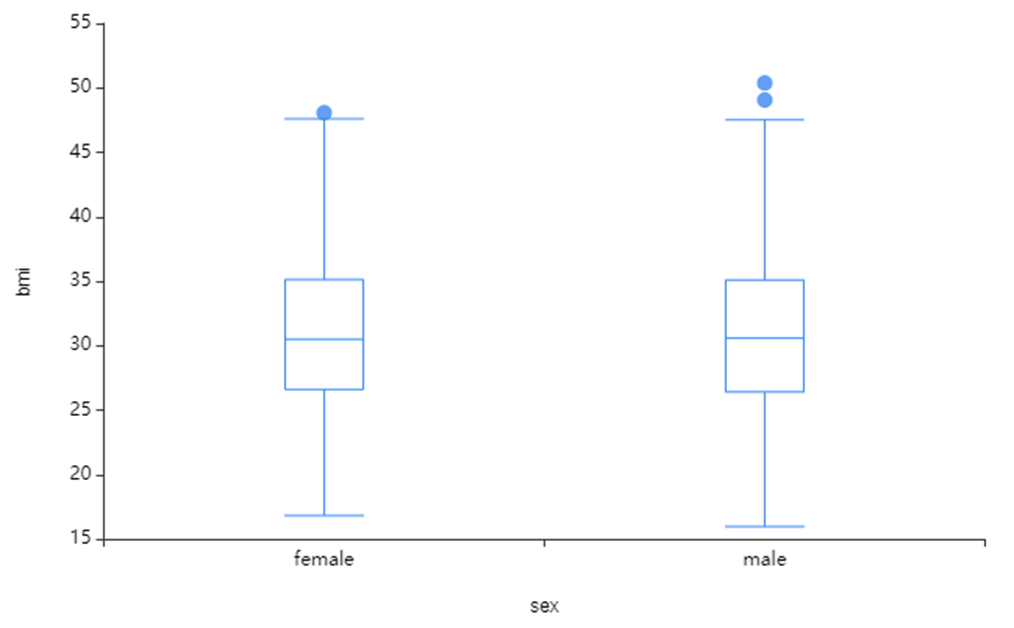
왼쪽 사진은 sex와 BMI의 시각화,
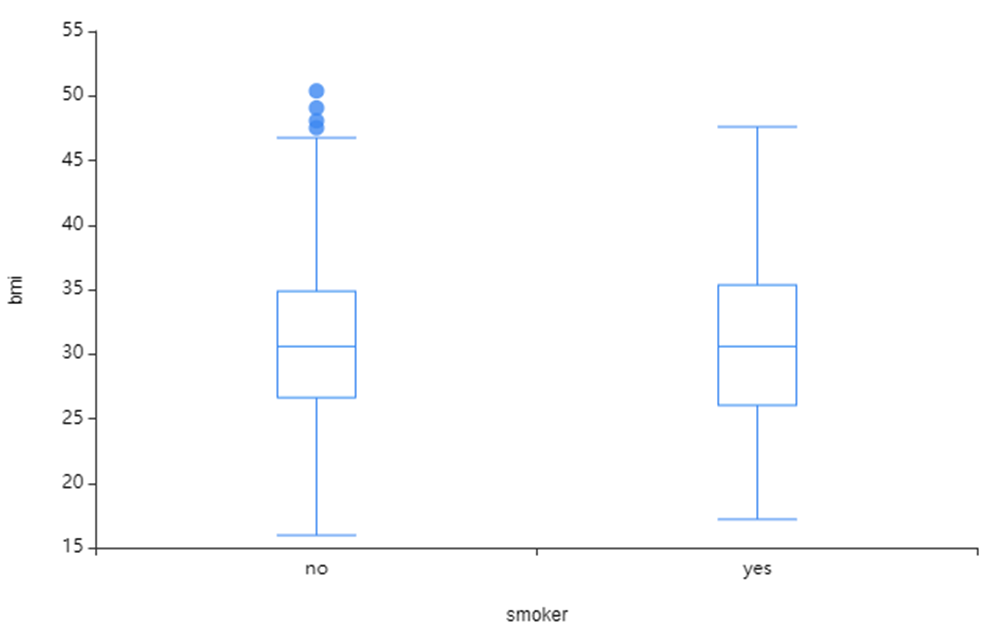
오른쪽 사진은 smoker와 BMI의 시각화를 진행하였습니다!
sex와 BMI 지수는 범주 차이는 약간씩 있지만
큰 차이가 없는 것을 확인할 수 있었습니다.
smoker 또한 sex와 동일하게
BMI 지수가 큰 차이가 없는 것을 확인할 수 있었습니다.
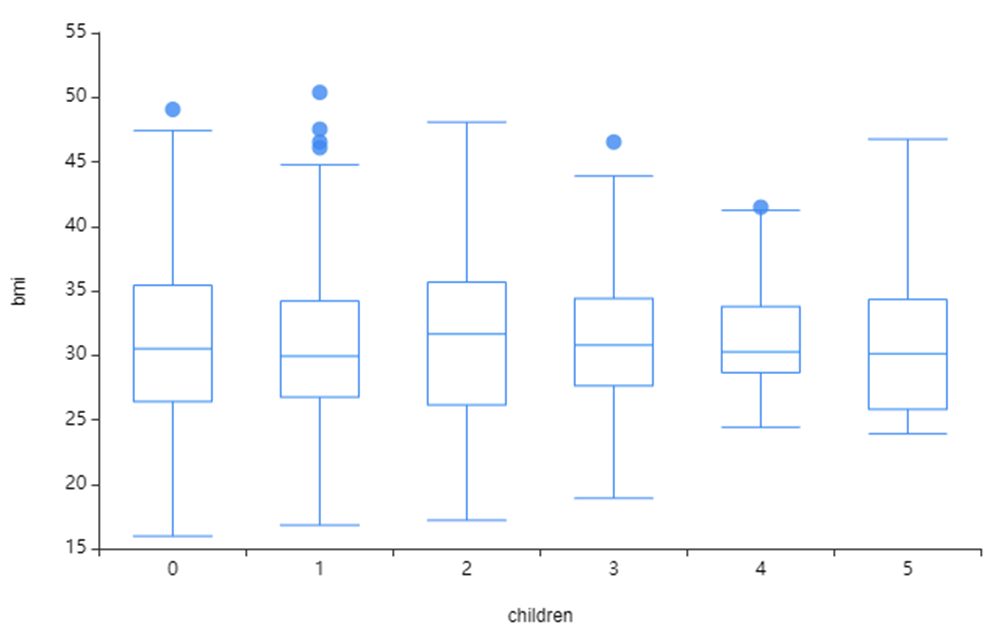
상단 사진은 children과 BMI 지수의 시각화를 진행하였습니다!
children 수가 많을수록
BMI 지수 최솟값이 높다는 것을 확인할 수 있었습니다.
3) Charges, BMI
이번에는 Charges와 BMI를 기준으로 두고
다른 칼럼들을 추가하여 시각화를 진행해보았습니다!

대체적으로 BMI 지수 높은 User들이
Charges가 크다는 것을 알 수 있었습니다.
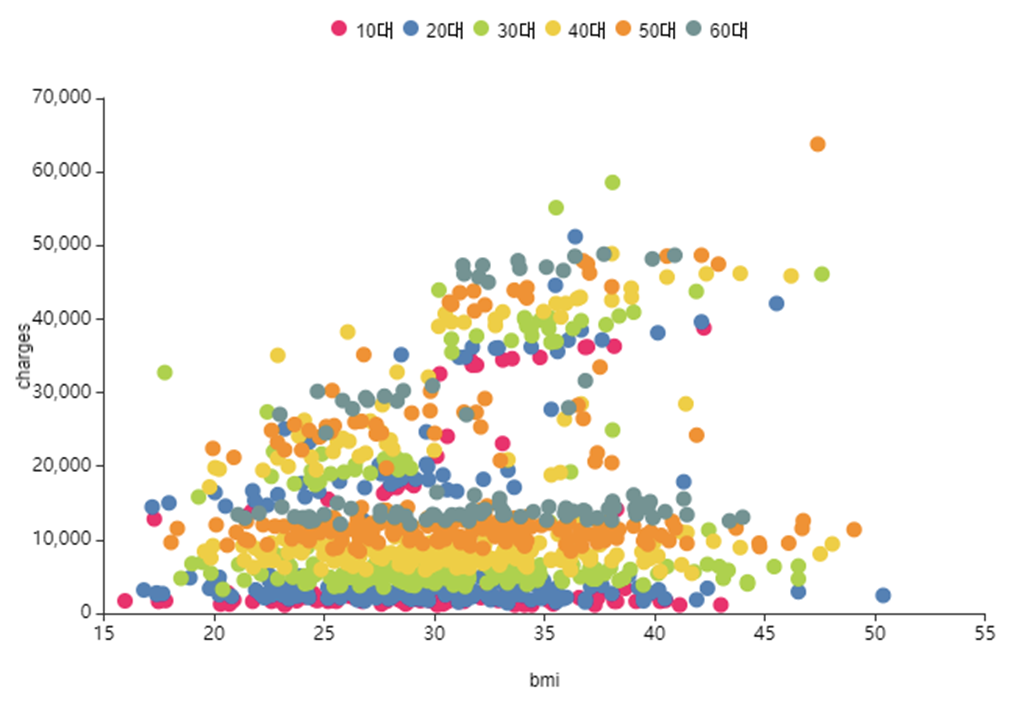
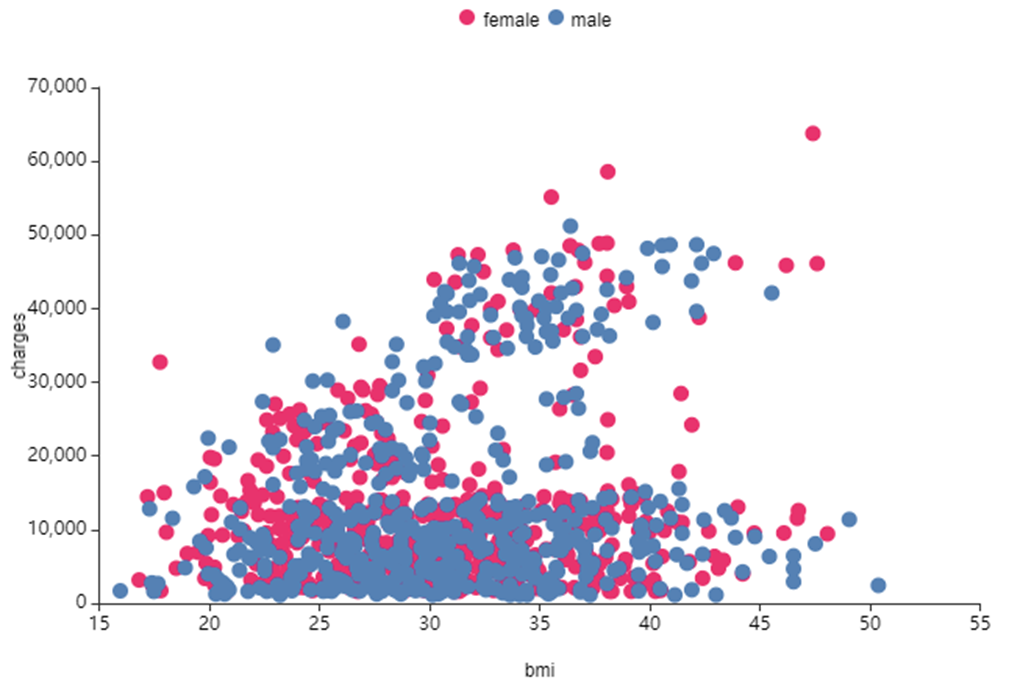
왼쪽 사진은 Charges와 BMI를 age_group으로 색을 구분하여 시각화,
오른쪽 사진은 Charges와 BMI를 sex로 색을 구분하여 시각화를 진행하였습니다!
age_group에 따른 BMI는 고루 분포되어 있지만,
age_group이 높을수록 Charges가 올라가는 것을 확인할 수 있었습니다.
sex가 여성일수록
BMI 지수와 Charges가 큰 것을 확인할 수 있었습니다.
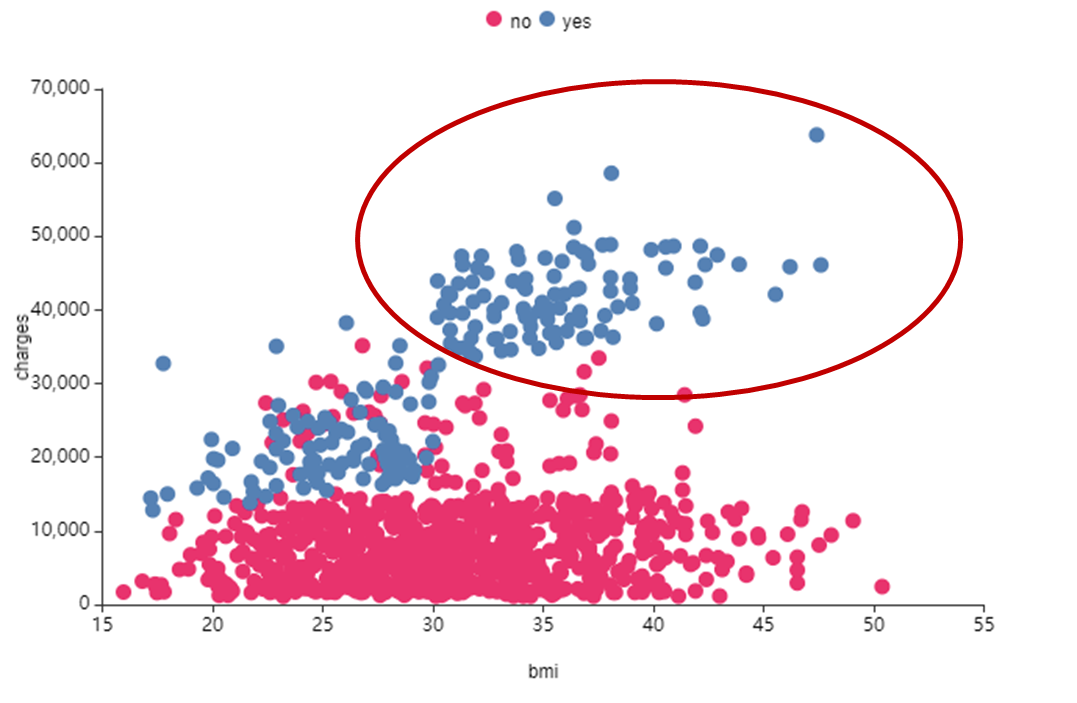
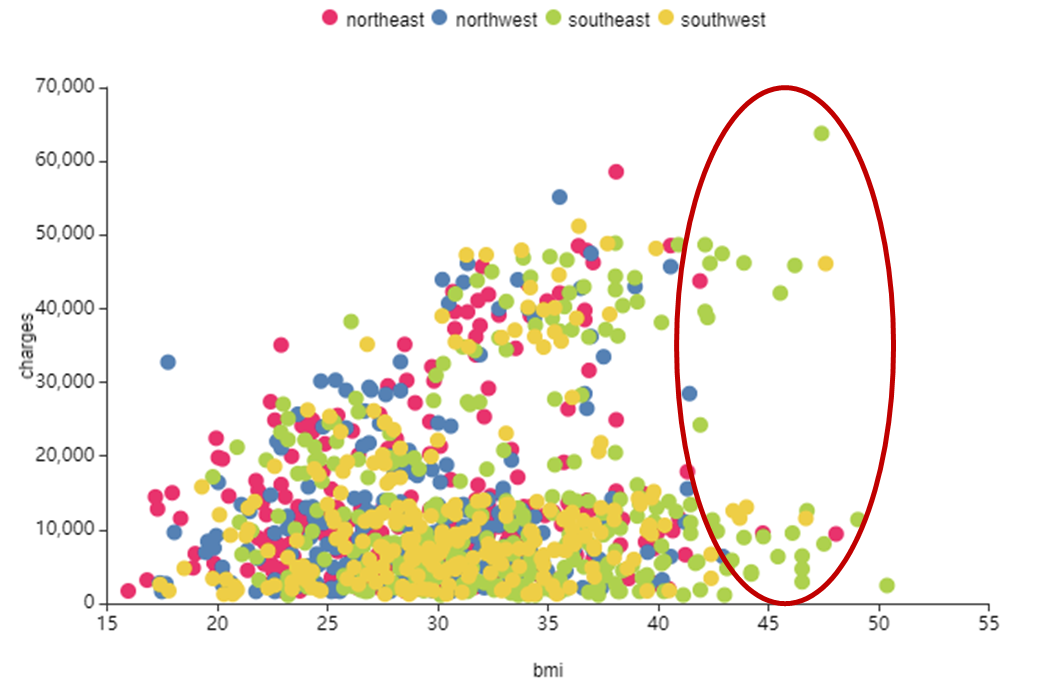
왼쪽 사진은 Charges와 BMI를 smoker으로 색을 구분하여 시각화,
오른쪽 사진은 Charges와 BMI를 region으로 색을 구분하여 시각화를 진행하였습니다!
smoker 칼럼을 확인해 본 결과
흡연자가 Charges가 높은 것을 확인할 수 있었습니다.
region 칼럼을 확인해 본 결과
southeast 지역이 다른 지역보다
BMI가 높은 것을 확인할 수 있었습니다.
프로젝트 배경과 데이터셋 설명,
간단한 EDA로 첫 번째 포스팅을 마무리하였습니다!
팀 프로젝트를 진행하면서
처음으로 팀원들과 맞춰보는 호흡이지만
각자 역할을 너무 잘해주고 있어서
팀 프로젝트를 잘 수행할 수 있다는 생각이 들었습니다!!
다음 포스팅은
데이터 전처리 및 모델링 부분으로
다시 찾아오겠습니다!
* 본 포스팅은 삼성 SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다 *
'대외활동 > 삼성SDS Brightics 서포터즈' 카테고리의 다른 글
| [삼성 SDS Brightics 서포터즈] #08_팀 프로젝트_개인 의료비 예측(3) (0) | 2022.08.30 |
|---|---|
| [삼성 SDS Brightics 서포터즈] #07_팀 프로젝트_개인 의료비 예측(2) (0) | 2022.08.23 |
| [삼성 SDS Brightics 서포터즈] #05_개인 프로젝트(1) 고객 성격 분석_데이터 전처리(2), 모델링, 분석 (0) | 2022.07.12 |
| [삼성 SDS Brightics 서포터즈] #04_개인 프로젝트(1) 고객 성격분석_데이터 전처리 (0) | 2022.07.05 |
| [삼성 SDS Brightics 서포터즈] #03_개인 프로젝트(1) 고객 성격 분석_데이터 구성, 데이터 로드, 통계량 확인 (0) | 2022.06.28 |



