
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 팀 분석
- Brigthics
- 삼성SDS Brigthics
- 혼공머신러닝딥러닝
- Brigthics Studio
- 영상제작기
- 데이터 분석
- 개인 의료비 예측
- 브라이틱스
- 삼성SDS Brightics
- 삼성 SDS
- 추천시스템
- 혼공
- 직원 이직여부
- 포스코 청년
- 삼성 SDS Brigthics
- 브라이틱스 서포터즈
- 모델링
- Brightics
- 혼공학습단
- 혼공머신
- 삼성SDS
- 노코드AI
- 데이터분석
- Brigthics를 이용한 분석
- 직원 이직률
- Brightics Studio
- 포스코 아카데미
- Brightics를 이용한 분석
- 캐글
- Today
- Total
데이터사이언스 기록기📚
[삼성 SDS Brightics 서포터즈] #03_개인 프로젝트(1) 고객 성격 분석_데이터 구성, 데이터 로드, 통계량 확인 본문
[삼성 SDS Brightics 서포터즈] #03_개인 프로젝트(1) 고객 성격 분석_데이터 구성, 데이터 로드, 통계량 확인
syunze 2022. 6. 28. 22:00안녕하세요~!
이번 포스팅은 개인 분석 프로젝트로,
평소에 분석해보고 싶은 데이터를 이용하여 분석을 진행해보았습니다.
목차는 다음과 같습니다.

그럼 지금부터 Brightics Studio를 활용한 프로젝트 분석을 시작해 볼까요?
1. 데이터 구성
https://www.kaggle.com/datasets/imakash3011/customer-personality-analysis
Customer Personality Analysis
Analysis of company's ideal customers
www.kaggle.com
저는 Kaggle에 있는 '고객 성격 분석' 데이터를 이용하였습니다!
데이터 샘플을 살펴보면 29개의 칼럼이 있는 것을 확인해볼 수 있습니다.
29개의 칼럼은 다음과 같이 4가지 분야로 나뉘어 있습니다.
People
| ID | 고객의 고유 식별자 |
| Year_Birth | 고객의 생년월일 |
| Education | 고객의 학력 |
| Marital_Status | 고객의 결혼 상태 |
| Income | 고객의 연간 가구 소득 |
| Kidhome | 고객 가구의 자녀 수 |
| Teenhome | 고객 가구의 청소년 수 |
| Dt_Customer | 고객이 회사에 등록한 날짜 |
| Recency | 고객의 마지막 구매 이후 일수 |
| Complain | 고객이 지난 2년 동안 불만을 제기한 경우 1, 그렇지 않는 경우 0 |
Products
| MntWines | 지난 2년 동안 와인에 지출한 금액 |
| MntFruits | 지난 2년동안 과일에 지출한 금액 |
| MntMeatProducts | 지난 2년 동안 육류에 지출한 금액 |
| MntFishProducts | 지난 2년 동안 물고기에 지출한 금액 |
| MntSweetProducts | 지난 2년 동안 과자에 지출한 금액 |
| MntGoldProds | 지난 2년 동안 골드에 지출한 금액 |
Promotion
| NumDealsPurchases | 할인된 구매 횟수 |
| AcceptedCmp1 | 고객이 첫번째 캠페인에서 제안을 수락한 경우 1, 그렇지 않은 경우 0 |
| AcceptedCmp2 | 고객이 두번째 캠페인에서 제안을 수락한 경우 1, 그렇지 않은 경우 0 |
| AcceptedCmp3 | 고객이 세번째 캠페인에서 제안을 수락한 경우 1, 그렇지 않은 경우 0 |
| AcceptedCmp4 | 고객이 네번째 캠페인에서 제안을 수락한 경우 1, 그렇지 않은 경우 0 |
| AcceptedCmp5 | 고객이 다섯번째 캠페인에서 제안을 수락한 경우 1, 그렇지 않은 경우 0 |
| Response | 고객이 마지막 캠페인에서 제안을 수락한 경우 1, 그렇지 않은 경우 0 |
Place
| NumWebPurchases | 회사 웹사이트를 통한 구매 건수 |
| NumCatalogPurchases | 카탈로그를 사용한 구매 수 |
| NumStorePurchases | 매장에서 직접 구매한 횟수 |
| NumWebVisitsMonth | 지난 달 회사 웹사이트를 방문한 횟수 |
People, Products, Promotion, Place 4가지 분야로 29개의 칼럼이 나뉘어서 구성되어 있습니다.
이제부터 해당 데이터로 데이터 분석을 시작해볼까요?
2. 데이터 로드
이제 Brightics Studio를 이용하여 분석을 시작해 보겠습니다!
1) 새 프로젝트 만들기
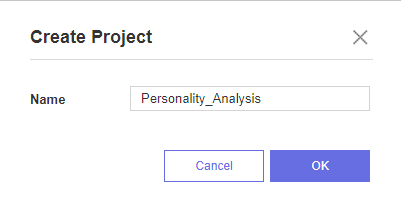
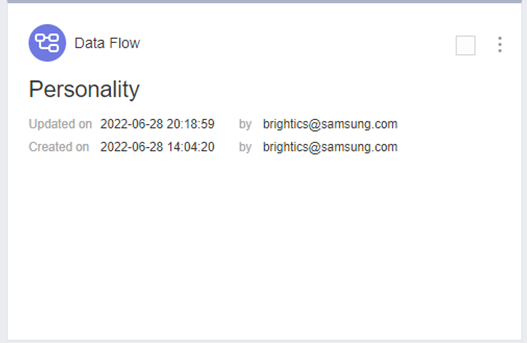
이전 포스팅과 다른 데이터를 이용하여
새 프로젝트와 모델을 생성하였습니다.
프로젝트 이름은 Personality_Analysis, 모델 이름은 Personality로 지정하고 프로젝트를 시작하였습니다!
2) 데이터 로드
① 데이터 추가
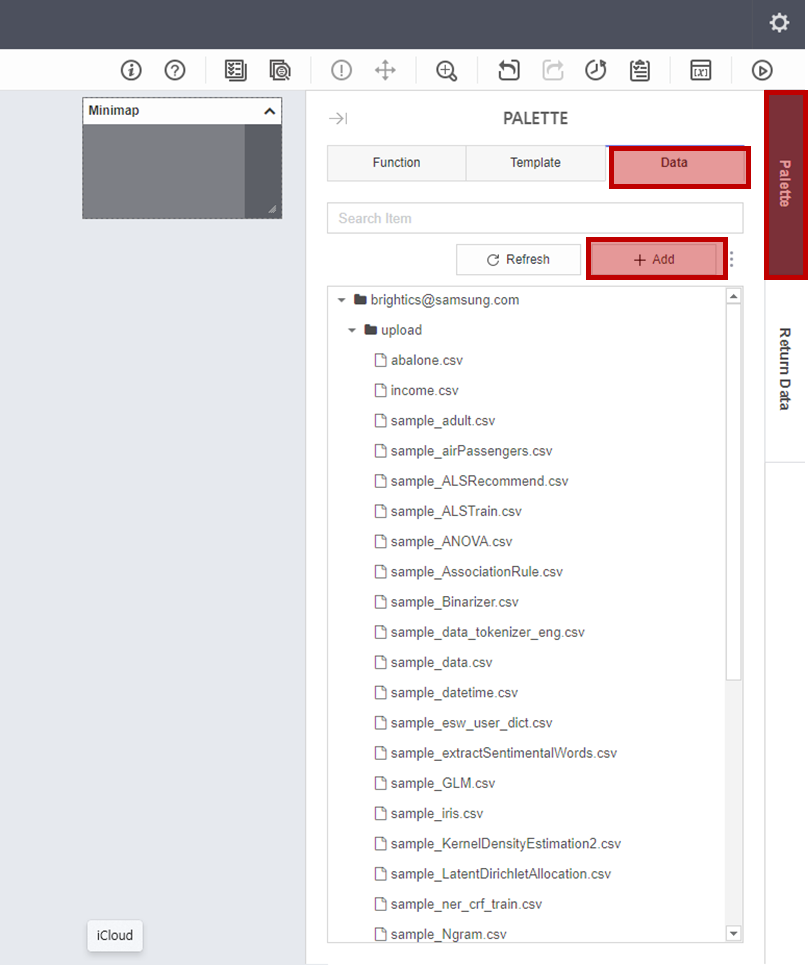
데이터를 로드하기 전, Brightics Studio에 데이터를 추가해 주어야합니다!
먼저 맨 오른쪽 Palette - Data - Add를 순서대로 눌러주세요!
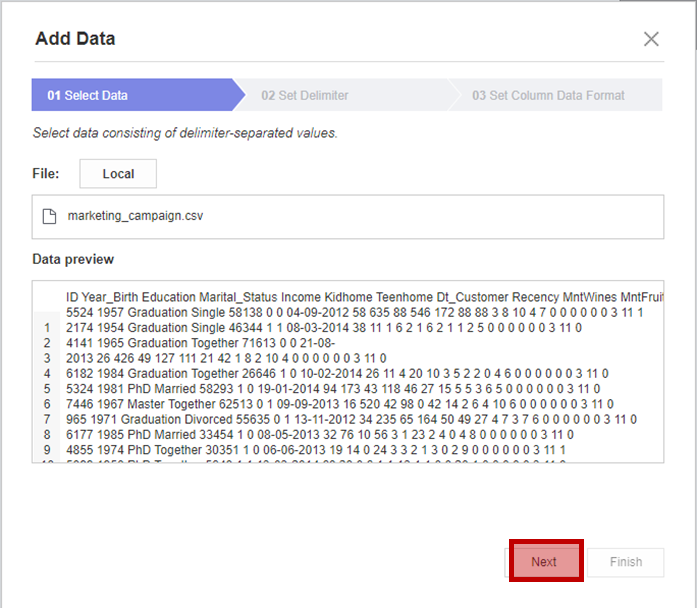
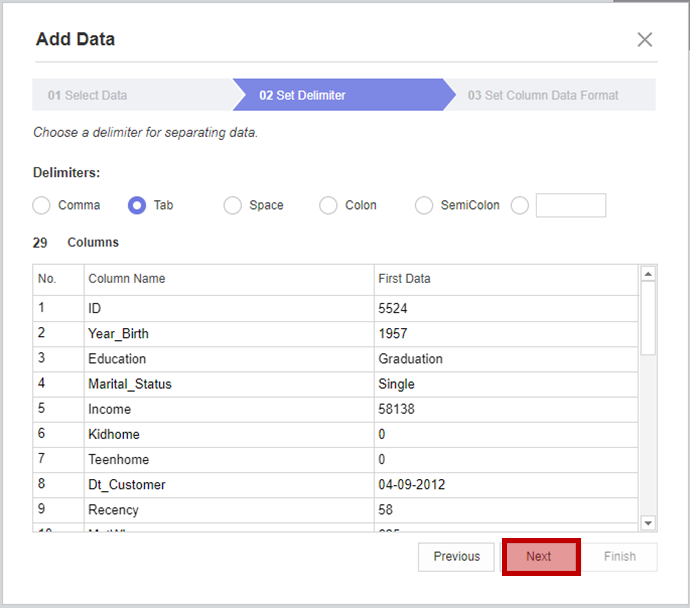
1번 Select Data에서 추가한 데이터 파일을 로드합니다.
2번 Set Delimiter에서 구분자를 선택합니다.
구분자마다 어떻게 데이터가 분리되는지 하단에서 미리 확인할 수 있습니다!
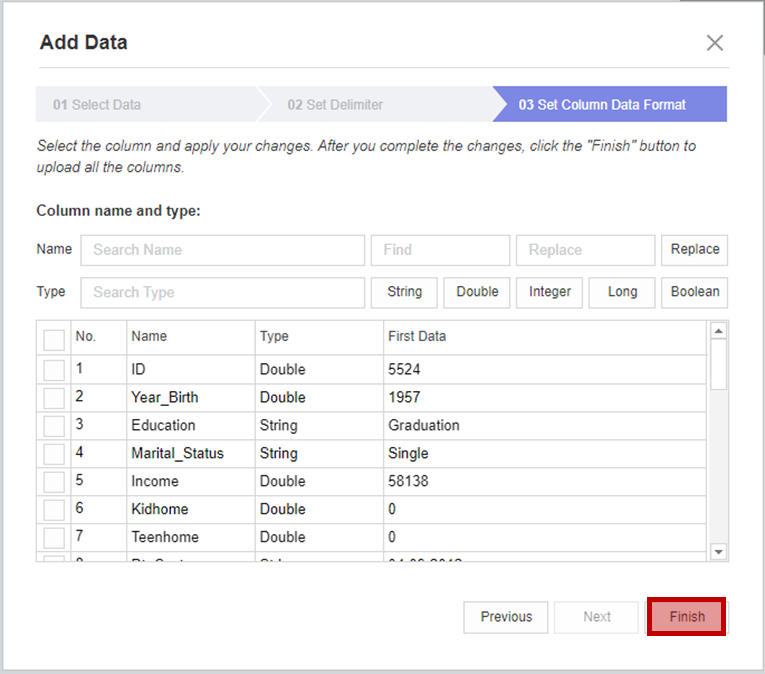
3번 Set Column Data Format에서 출력 예시와 데이터 타입을 확인하세요.
3번에서 데이터 타입을 수정할 수 있습니다.
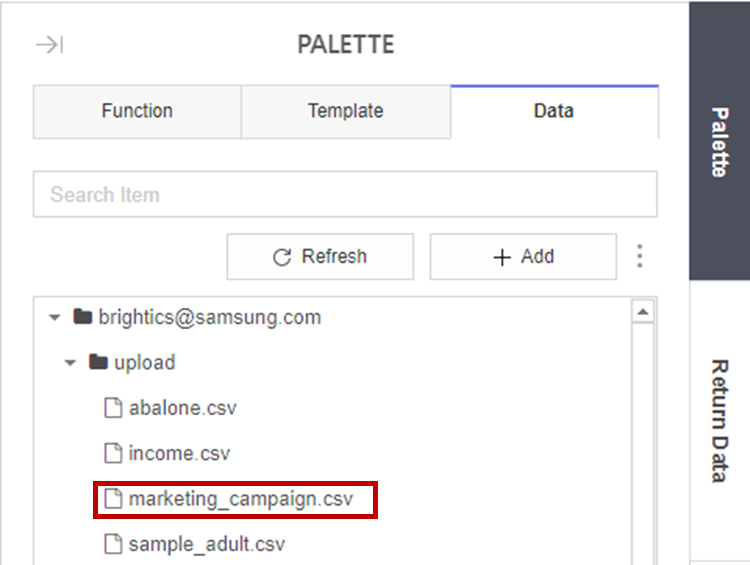
모든 순서를 완료하면 Data에 제가 분석할 데이터가 추가된 것을 확인할 수 있습니다!
② 데이터 로드
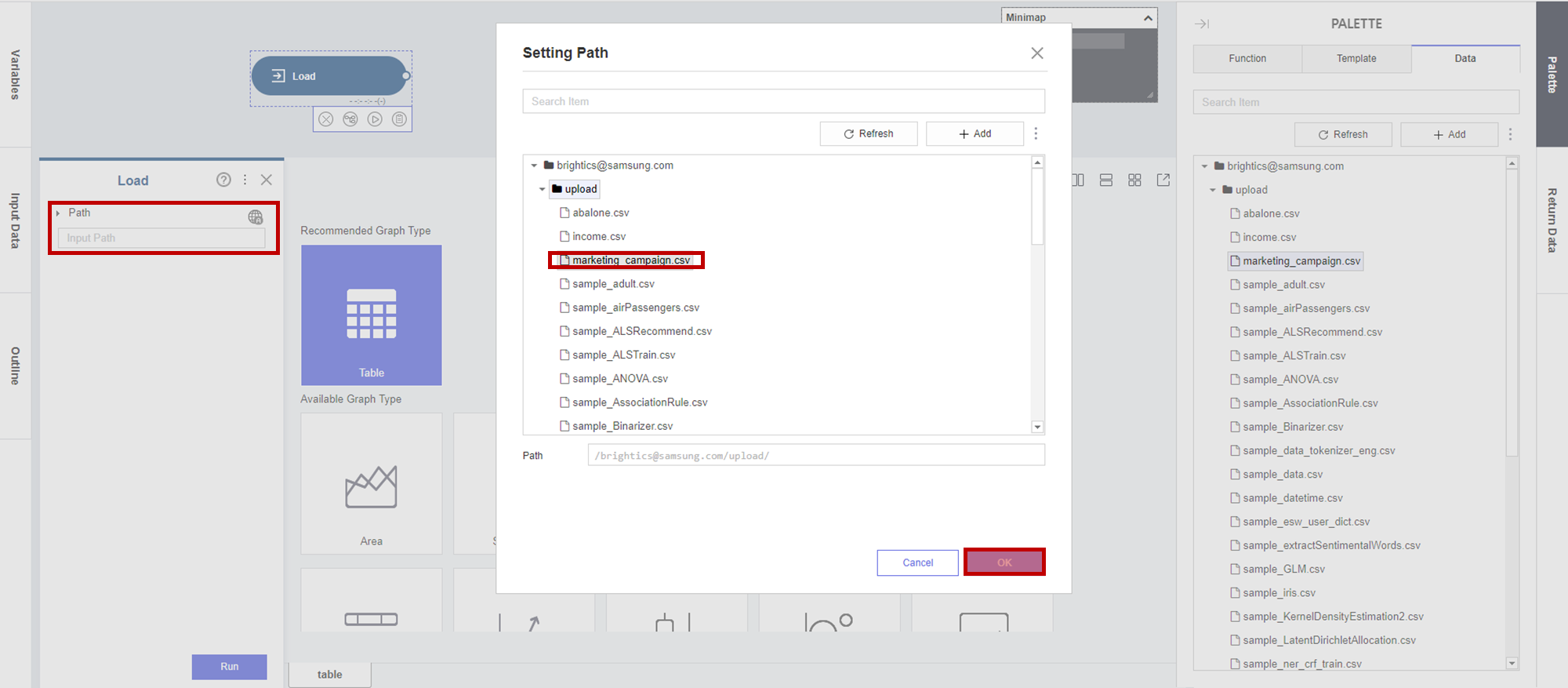
데이터를 불러오기 위해 Load 함수를 Templete에 추가하고
(Load) Path - 사용할 데이터셋을 선택하고 OK를 누릅니다.
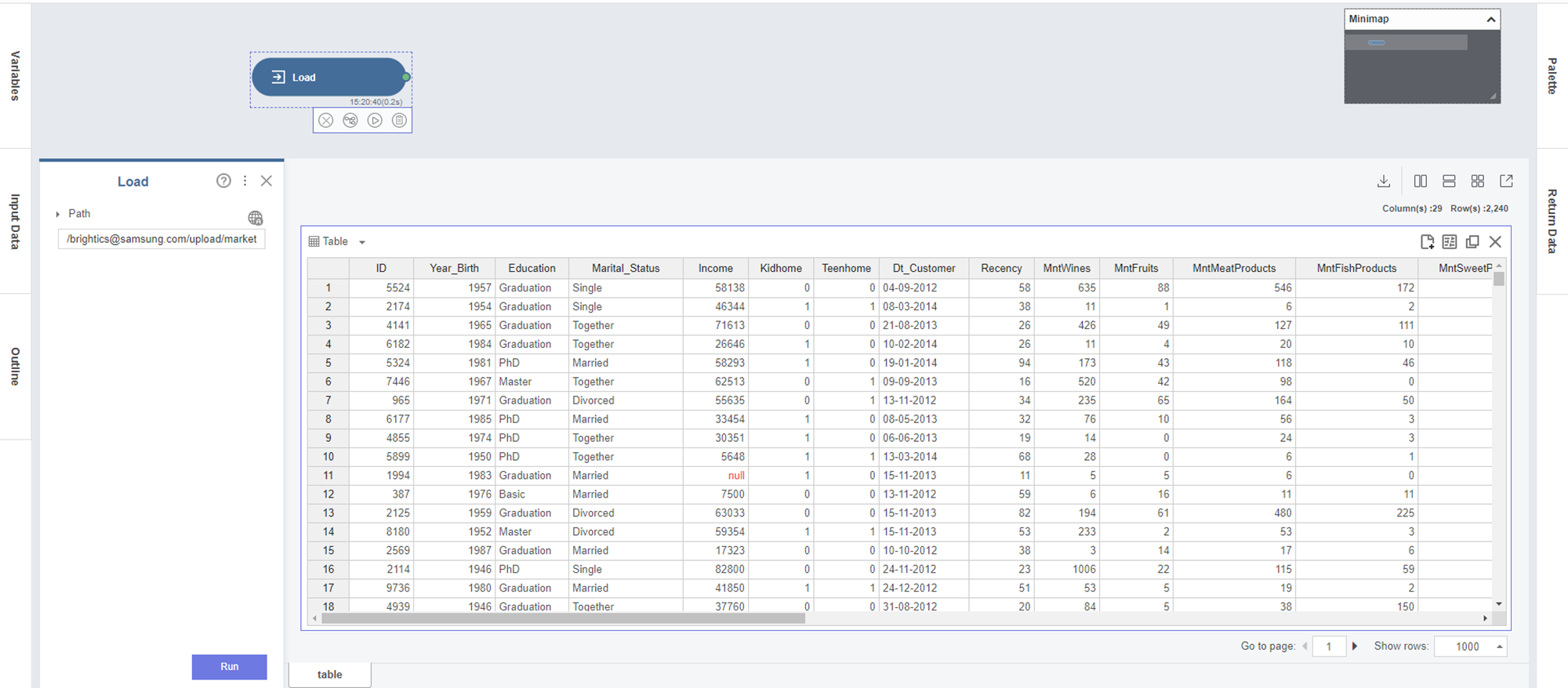
그럼 다음과 같이 오른쪽에 로드한 데이터 테이블을 확인할 수 있습니다.
3. 통계량 확인
통계량 확인 전, 통계량 확인 및 전처리 함수를 알아볼까요?
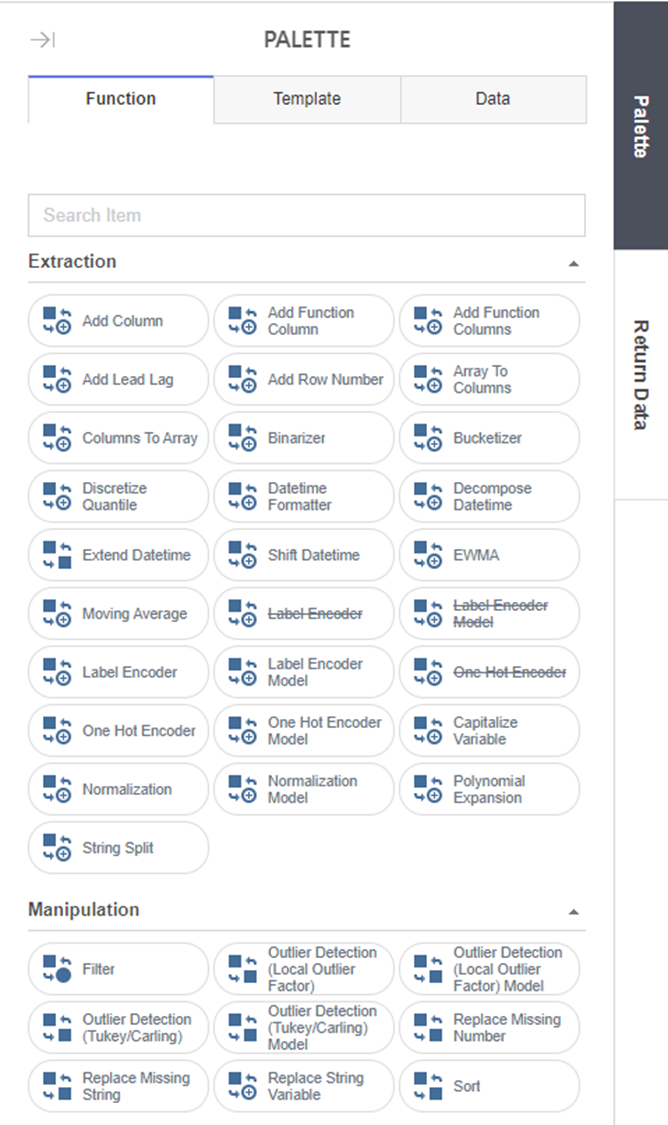
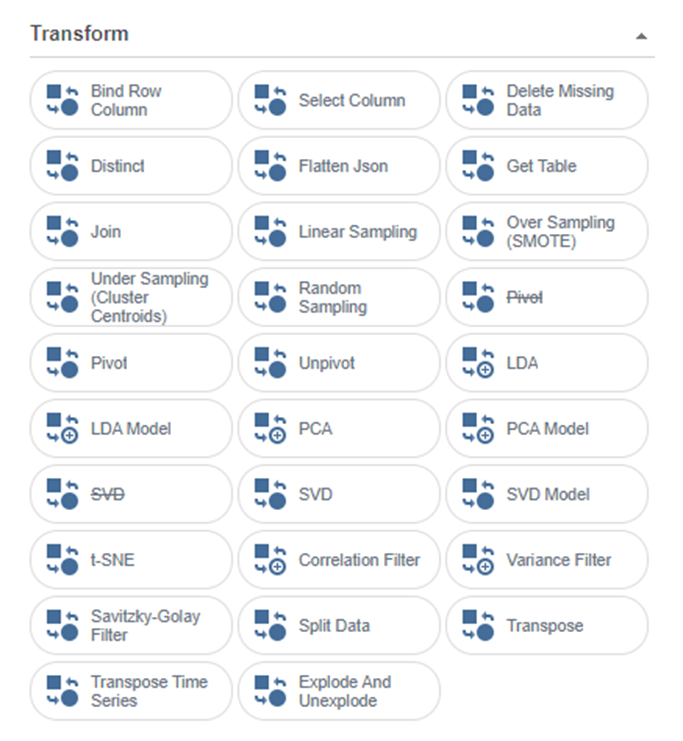
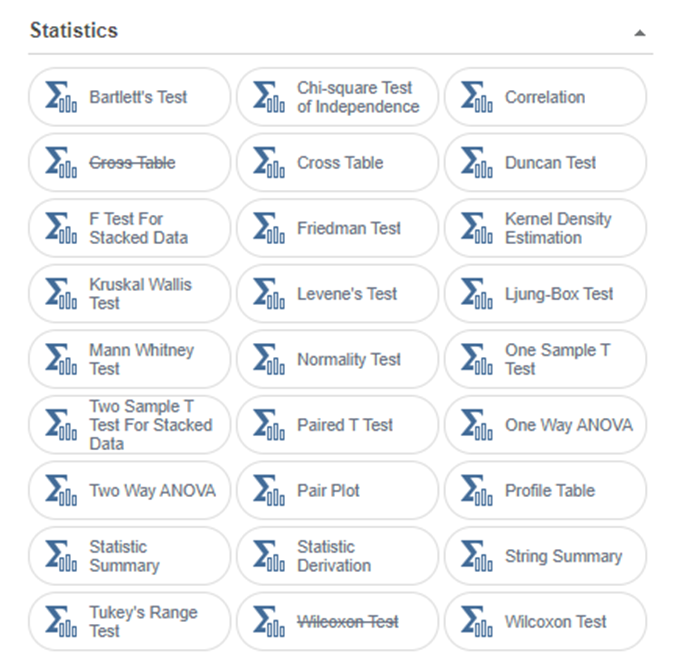
Brigthics Studio에서 제공하는 통계량, 전처리 함수는 PALETTE - Function에 있습니다!
통계량 및 전처리 함수는 그룹별로 Extraction, Manipulation, Transform, Statistics가 있습니다.
본격적으로 Personality 데이터의 통계량을 확인해볼까요?
1) 통계량 요약
Statisics - Statistic Summary을 이용하여 통계량 요약을 살펴보겠습니다.
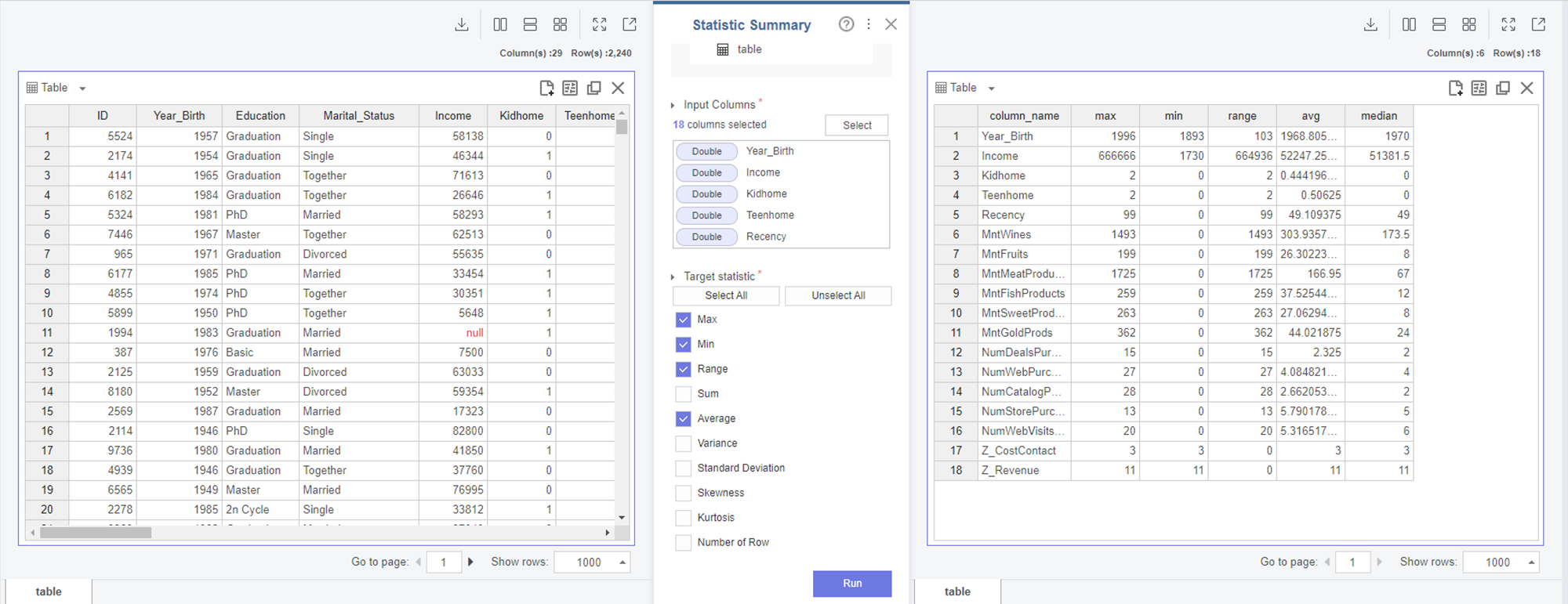
범주화된 칼럼들은 제외 후
최댓값, 최솟값, 범위, 평균, 중앙값을 확인해보았습니다.
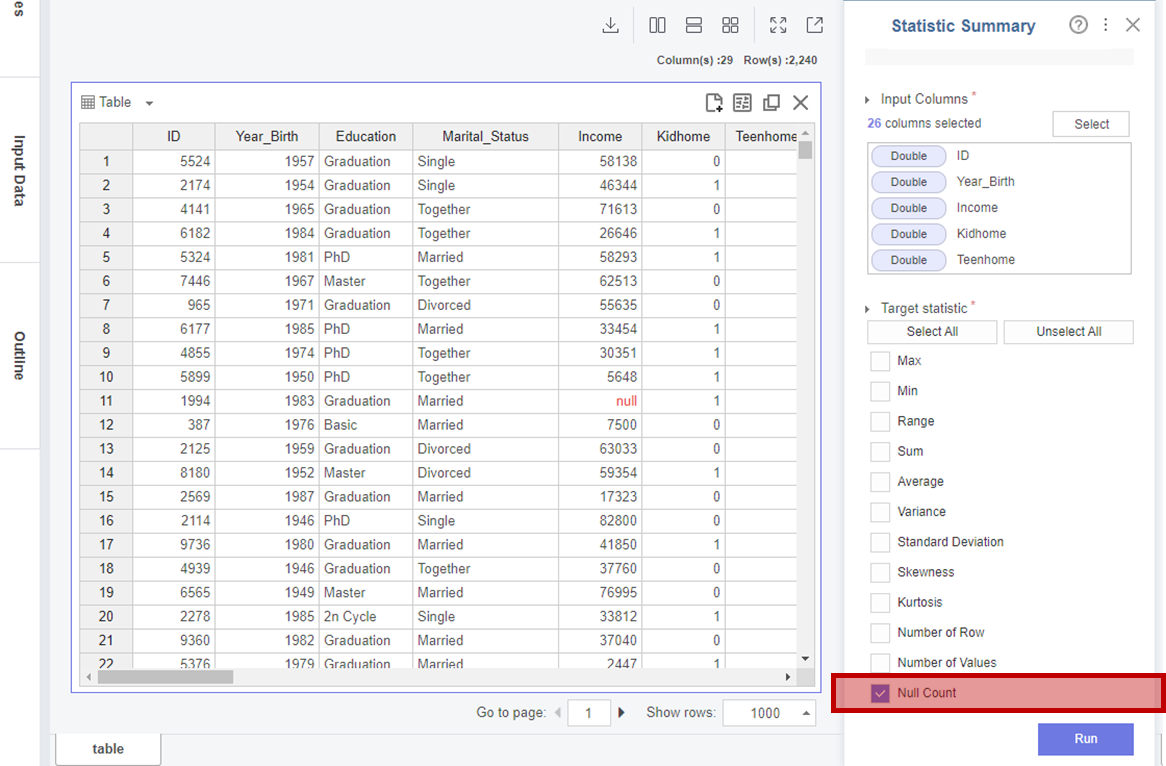
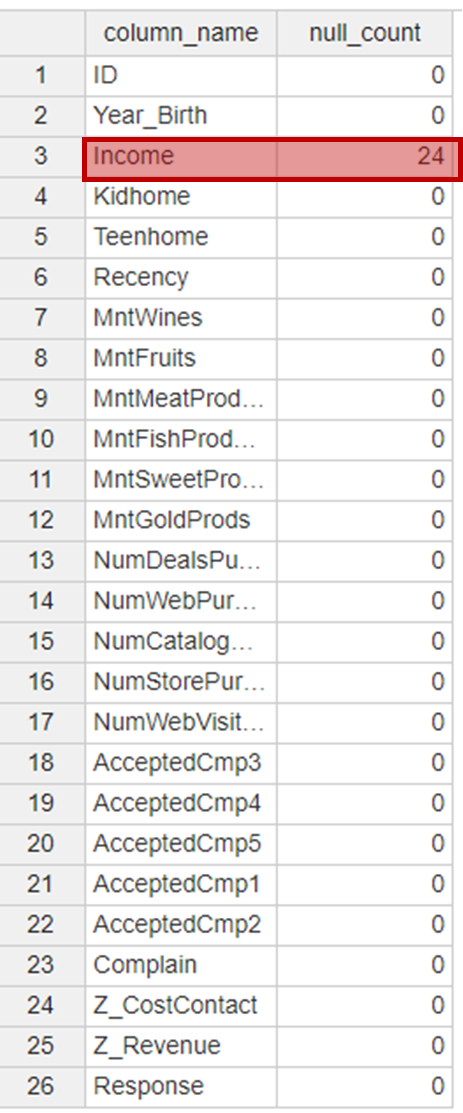
다음은 Type이 숫자인 전체 칼럼에 대해 Null Count를 확인하였습니다.
Income에 24개의 Null Count가 있는 것을 확인하였고,
추후 칼럼을 제거하도록 하겠습니다.
2) Profile Table
Statistic에 있는 Profile Table은 데이터 분포와 위험 요소를 알려주는 함수입니다.
함수 하나로 데이터 분포나 위험요인을 알 수 있다니
너무 유용한 기능 아닌가요?!?!
그!래!서!
저는 유용한 기능을 한 번 써보도록 하겠습니다!
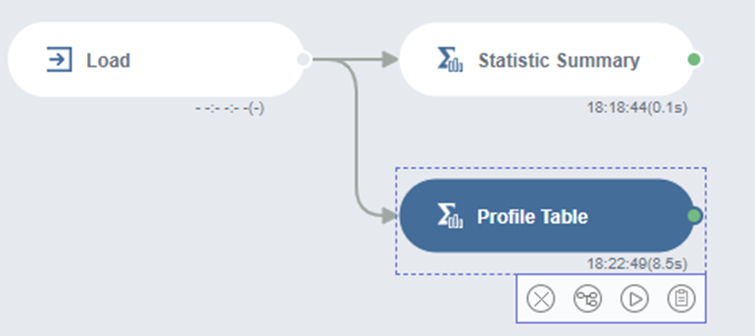
로드된 데이터와 Profile Table을 연결해주고
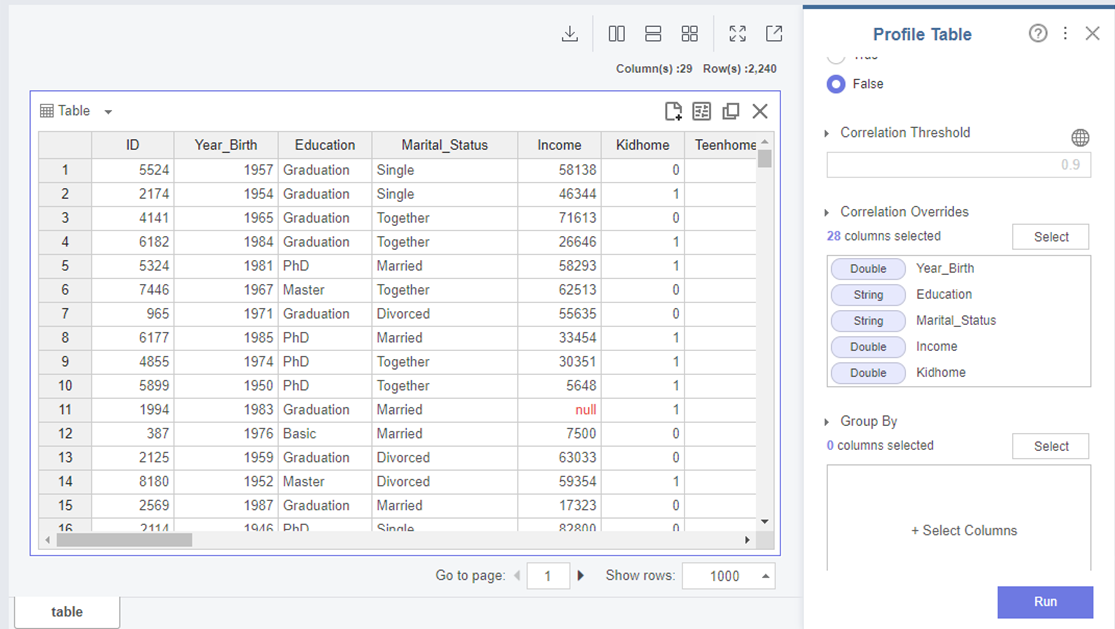
ID 칼럼을 제외한 모든 칼럼들의 Profile을 확인해보았습니다!
OverView
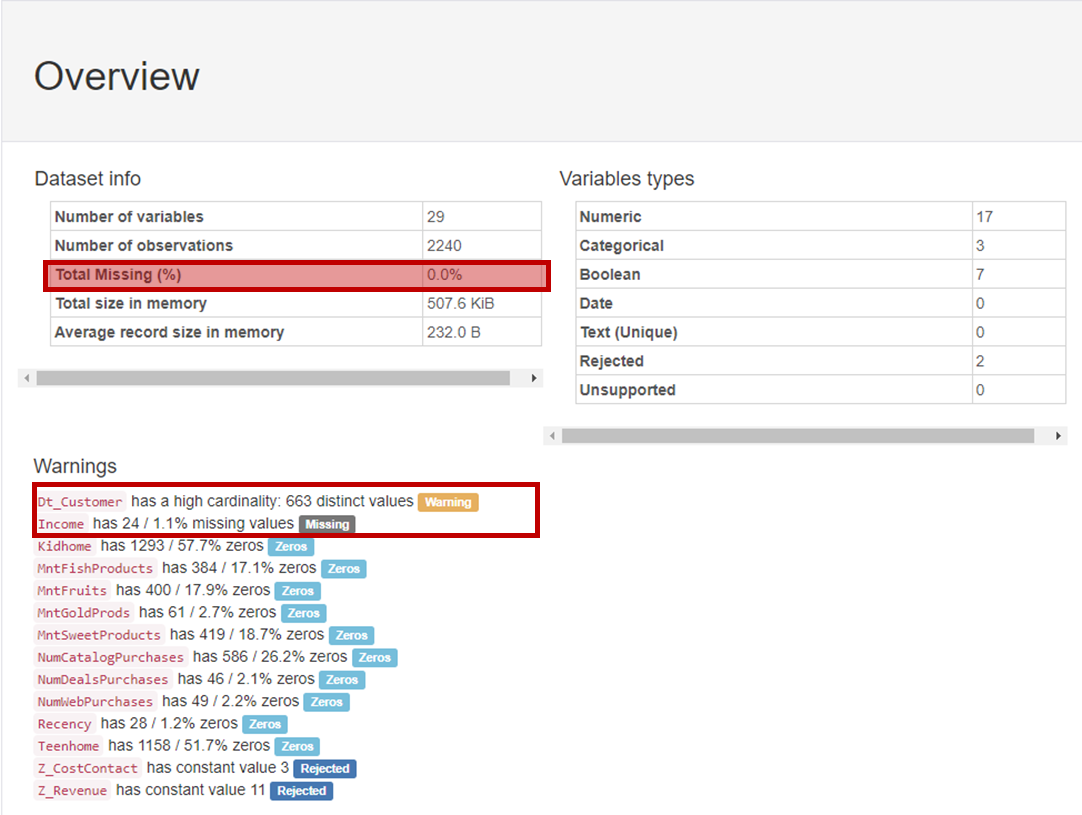
OverView에는 기본적인 데이터 정보와 칼럼 타입이 카운트되어있고
주의가 필요한 칼럼에 대해 어떤 점이 문제인지 명시되어 있습니다.
데이터 정보의 Total Missing이 0%인 점을 확인하고
Missing데이터를 삭제해도 데이터 손실이 일어나지 않는다고 판단하여
모든 Missing 데이터들을 지워도 된다고 판단하였습니다!
또한 Dt_Customer에 663개의 중복값이 문제점으로 명시되어있어
추후에 확인해 보기로 판단하였습니다.
Variables
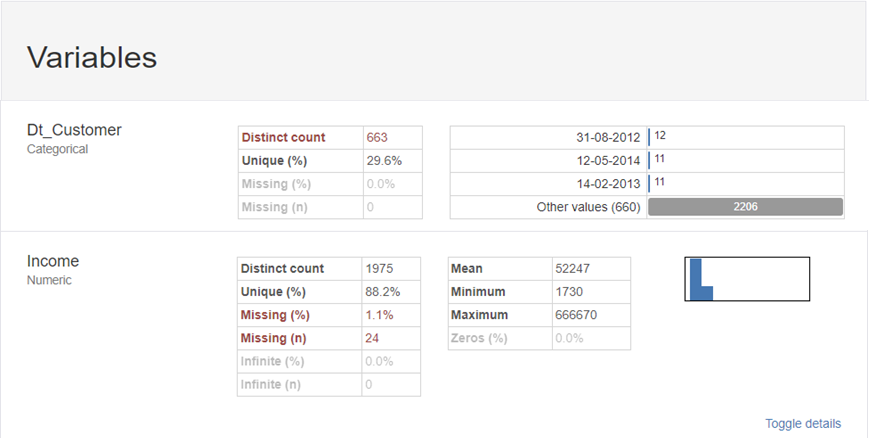
Variables에서는 칼럼 내 value의 count와 이를 시각화 한 그래프를 확인할 수 있었습니다!
Variables에서 의미 있는 두 개의 칼럼을 확인해보았습니다.
OverView에서 Dt_Customer가 중복값으로 문제가 있다고 명시되었는데
Dt_Customer는 날짜 형식으로 중복값이 존재할 수밖에 없는 형식이었습니다.
Variables를 통해 Dt_Customer는 문제가 없다는 점을 확인하였습니다!
또한 Income에 대한 Variables도 확인해보았는데요,
최소, 최댓값 사이 차이가 많이 나며
최댓값과 평균의 차이도 커서 이상치가 있는지 확인해봐야겠다고 판단했습니다!
3) 결측치 제거
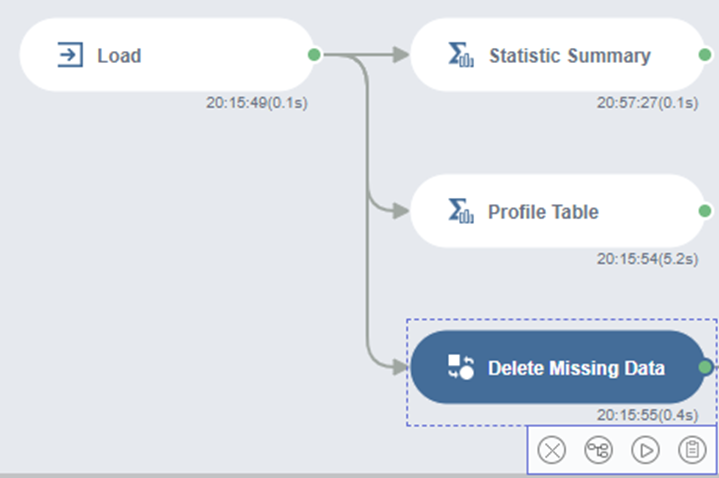
다음은 Profile Table에서 확인한 Missing Data를 삭제하는 작업을 해보겠습니다.
Delete Missing Data함수를 Load에 연결해주세요!
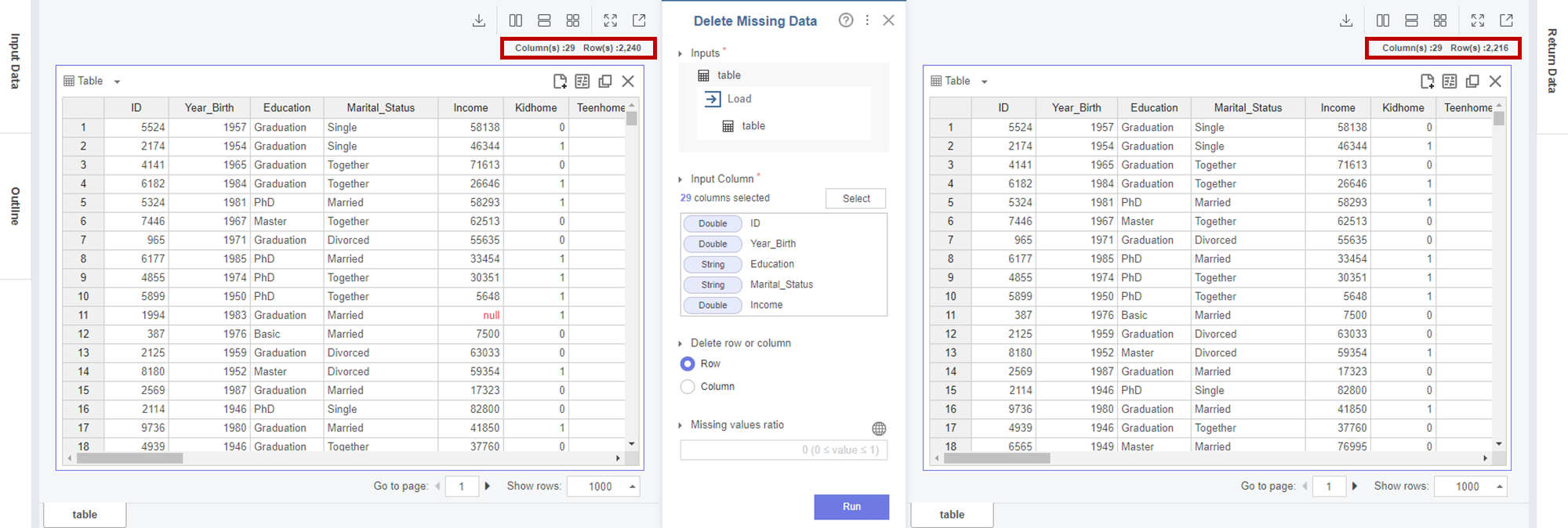
모든 칼럼을 선택하고 함수를 실행해보았더니
Profile Table에 명시되었던 Income의 24개의 데이터만 삭제된 것을 알 수 있었습니다!
4) Column Type 바꾸기
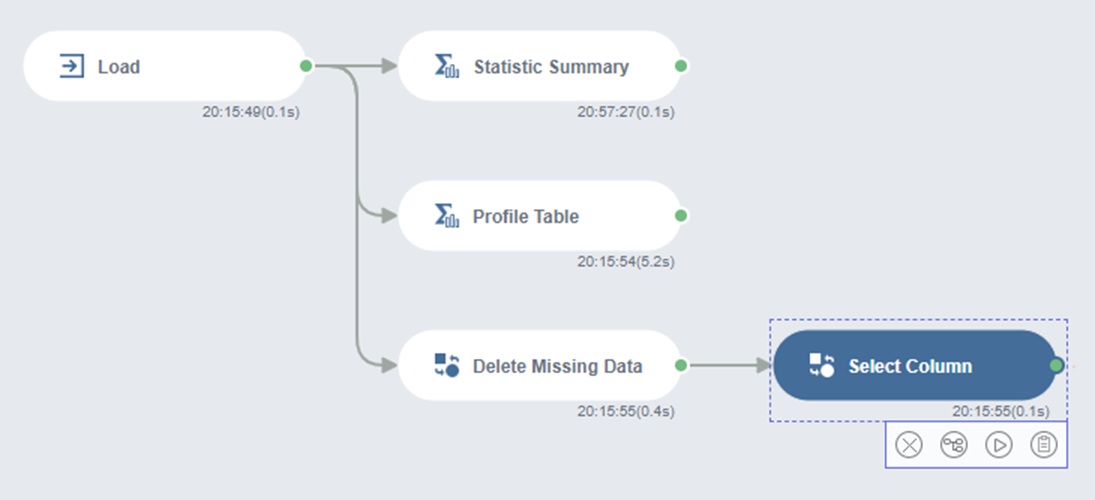
Select Column 함수는 원하는 Column만 선택 가능하고 Column 이름이나 Type을 바꾸는 것도 가능합니다!
저는 Column Type을 바꾸기 위해서 Select Column 함수를 선택했습니다.
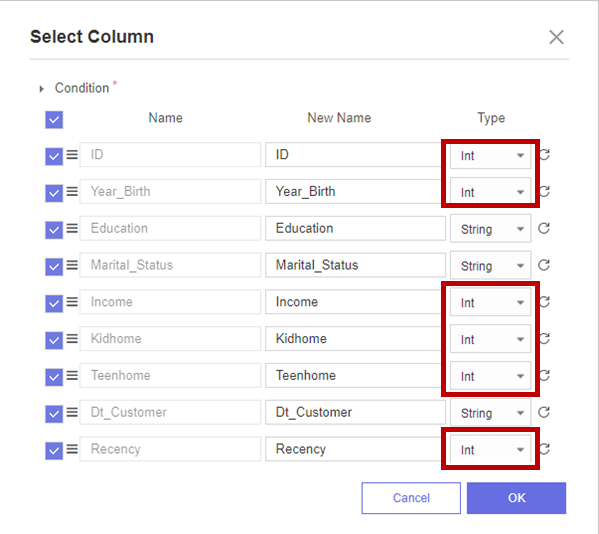
Double형이었던 숫자들을 Int형으로 모두 변환합니다.
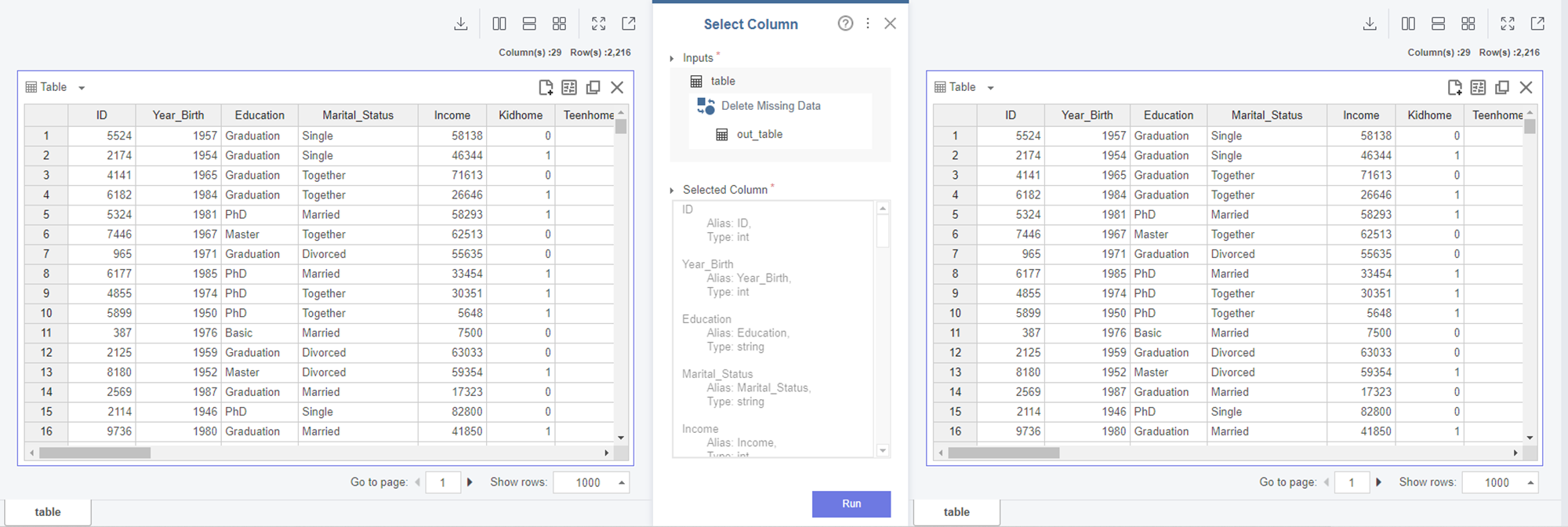
Double을 Int형으로 변환 완료하였습니다!
이번 포스팅에서는 데이터 선정, 데이터 구성 설명, 데이터 로드, 통계량 확인으로
데이터 분석에 필요한 간단한 요소들을 진행해보았습니다.
다음 포스팅에서는 데이터 분석의 꽃인
데이터 전처리에 대해서 포스팅하겠습니다!
긴 글 읽어주셔서 감사합니다 :)
* 본 포스팅은 삼성 SDS Brightics 서포터즈 3기 활동의 일환으로 작성하였습니다 *
'대외활동 > 삼성SDS Brightics 서포터즈' 카테고리의 다른 글
| [삼성 SDS Brightics 서포터즈] #06_팀 프로젝트_개인 의료비 예측(1) (0) | 2022.08.16 |
|---|---|
| [삼성 SDS Brightics 서포터즈] #05_개인 프로젝트(1) 고객 성격 분석_데이터 전처리(2), 모델링, 분석 (0) | 2022.07.12 |
| [삼성 SDS Brightics 서포터즈] #04_개인 프로젝트(1) 고객 성격분석_데이터 전처리 (0) | 2022.07.05 |
| [삼성SDS Brigthics 서포터즈] #02_Brightics 서포터즈 발대식에 참석하다! (0) | 2022.06.27 |
| [삼성 SDS Brightics 서포터즈] #01_데이터 분석? 어렵게 생각하지 마세요! Brightics가 있잖아요! (0) | 2022.06.20 |



