
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 삼성 SDS Brigthics
- 팀 분석
- 브라이틱스 서포터즈
- Brightics
- 혼공머신
- 포스코 아카데미
- 직원 이직률
- 삼성SDS
- 브라이틱스
- Brightics Studio
- 삼성SDS Brightics
- 포스코 청년
- 노코드AI
- 영상제작기
- 혼공머신러닝딥러닝
- 삼성 SDS
- 데이터 분석
- 추천시스템
- 캐글
- 직원 이직여부
- 데이터분석
- 개인 의료비 예측
- Brigthics를 이용한 분석
- 혼공
- Brigthics Studio
- 삼성SDS Brigthics
- Brightics를 이용한 분석
- Brigthics
- 모델링
- 혼공학습단
- Today
- Total
데이터사이언스 기록기📚
[추천시스템] 고전적인 추천 알고리즘 본문
📌목차
1. 인구통계 기반 필터링(Demograpic Filtering)
2. 인기도 기반 추천(Popularity Based)
3. 지식 기반 추천(Knowledge Based)
4. 규칙 기반 추천(Rule-Based)
✔️인구통계 기반 필터링(Demograpic Filtering)
- 정의 : 연령, 나이, 직업과 같은 정보로 추천 제공
- 가정 : 인구통계학 특성 유사한 사용자 → 선호도와 관심사가 비슷할 것이라고 가정
- 특징 : 단순한 피처 기반 필터링(유저 피처, 아이템 피처 페어링 → 유저기반만 활용)
- 장단점
| 장점 | 단점 |
| - 단순, 직관적 - 콜드스타트에 대응가능(아무런 정보가 없어도 적당한 추천 가능) - 해석 가능 |
- 개인화 안됨 - 고정관념에 기반(공정성의 문제 발생) - 개인정보의 민감정보의 한계 |
✔️ 인기도 기반 추천(Popularity Based)
- 정의 : 상품을 인기도 기준으로 추천
- 인기도 = 항목 받은 조회 수, 좋아요 수, 클릭 수, 평점 등의 칼럼 활용하 인기도 계산
- 예시) 멜론 Top 100
- 장단점
| 장점 | 단점 |
| 사용자별 정보나 선호도 의존 X → 구현하기 쉽고 확장성 뛰어남 | - 개인화가 안됨 - 필터 버블(기존에 관심있는 것만 나타남 → 유사한 콘텐츠의 ‘거품’ 형성 → 제한된 정보 추천 노출) - 아이템 콜드 스타트 문제(interaction 없는 아이템은 추천 못함) |
💻코드 예제
- Book-Crossing 예제를 통한 인기도 기반 코드
Book-Crossing: User review ratings
A collection of book ratings
www.kaggle.com
def popularity_recommendation(ratings, n=10):
popular_books = ratings.groupby('Book-Title')['Book-Rating'].count().sort_values(ascending=False).head(n).index
return popular_books
popular_books = popularity_recommendation(ratings, n=10)
print("\nPopularity-Based Recommendations:")
for i, book in enumerate(popular_books, 1):
print(f"{i}. {book}")
- 사전작업

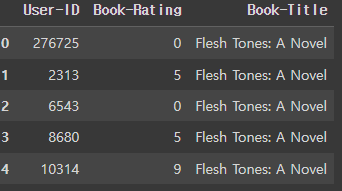
# Load the data
books = pd.read_csv(data_path+'BX-Books.csv', sep=';', error_bad_lines=False, warn_bad_lines=False, encoding="latin-1")
users = pd.read_csv(data_path+'BX-Users.csv', sep=';', error_bad_lines=False, warn_bad_lines=False,encoding="latin-1")
ratings = pd.read_csv(data_path+'BX-Book-Ratings.csv', sep=';', error_bad_lines=False, warn_bad_lines=False, encoding="latin_1")
# Preprocess the data
ratings = ratings.merge(books[['ISBN', 'Book-Title']], on='ISBN')
ratings = ratings.drop(['ISBN'], axis=1)✔️ 지식 기반 추천(Knowledge Based)
- 정의 : 전문가의 지식이나, 유저 입력에 기반한 추천
- 해당 추천 시스템 적합한 경우
- 고객의 요구사항을 자세히 명시할 때
- 항목, 유형 측면에서 도메인의 복잡헝 큼 → 특정 유형의 평점 얻기 어려운 경우
- 평점에 민감한 경우
추천 시스템 5장 : 지식 기반 추천 시스템
📌 개요 지식 기반 추천 시스템은 아이템에 대한 사용자 요구 사항의 명시적 요청에 의존한다. 대화형 피드백을 사용해 사용자가 본질적으로 복잡한 제품 옵션을 탐색하고 다양한 옵션 간에 사
velog.io
✔️ 규칙 기반 추천(Rule-Based)
- 정의 : 사전에 정의된 규칙에 의해 추천 제공 (웹으로 들어온 사람 어떤 아이템 추천)
🔗대표 알고리즘 : 연관 규칙 분석 (Market Basket Analysis, Affinity Analysis)
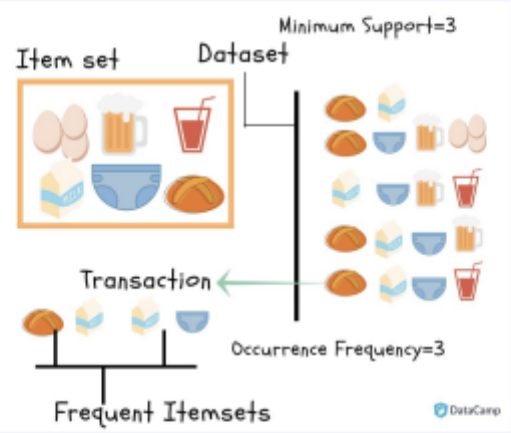
- 정의 : 전체 거래 내 특정 아이템이 연결되는 방법, 이유를 결정하는 규칙을 발견하기 위한 학습 방법론
- 자주등장하는거 기반, 연관성이 떨어지지만 많이 구매 함
- 빈번하게 등장하는 아이템셋만 고려하는 Apriori 알고리즘 적용 → 빠른 규칙 생성 가능
- 규칙 : A를 사면 (조건절; IF) B를 산다(결과절; Then)라는 규칙 가지는 알고리즘
- item set = 조건절 상품 + 결과절 상품
- 표현 : (조건절 상품, 결과절 상품)
- 조건 : 조건절 상품, 결과절 상품에는 겹치는게 없어야 함
- 특징
- 장바구니 상품이 많으면 급속도로 경우의 수 증가
- 성능이 낮은 규칙 배제 → 다양한 성능 지표 적용해서 연산 효율화
- 데이터 입력 형태

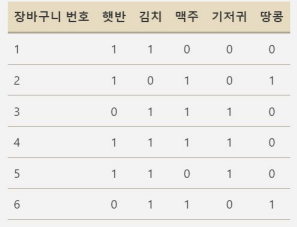
- 규칙 성능 지표
1) 지지도(support) : A와 B가 동시에 등장할 확률은?
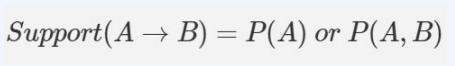
- 빈번이 등장하는 쌍을 찾으려고 적용
- 지지도가 높을 수록, 해당 규칙을 적용하려고 함
- 예) (맥주, 김치) 쌍 찾기 - (맥주, 김치). (맥주, 김치, 기저귀) → 2개의 쌍
2) 신뢰도(Confidence) : A가 장바구니에 있을 때, B가 동시에 등장할 확률은?
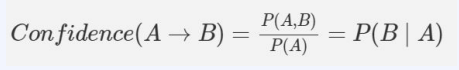
- 지지도가 커버하지 못하는 부분을 보완
- A가 장바구니에 있을 때 → 로 한정 = 규칙이 엄밀
3) 향상도(Lift) : 둘이 등장할 확률이 독립이라고 할 때보다 얼마나 더 잘 같이 등장하는가
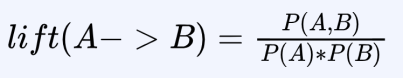
- 생성된 규칙이 얼마나 유용한지 나타내기 위함
- 높으면 긍정, 낮으면 부정
- 예) 향상도 1.25 → 맥주, 기저귀가 독립이라고 가정할 때 보다 0.25개 더 팔림
- 왜 향상도 필요? - 자주등장하는 상품에 대해 패널티를 제공하기 위함
4) 레버리지(Leverage) : 규칙에서 등장하는 상품들이 얼마나 유의미하게 같이 등장하나?

- A와B가 독립이라고 가정할 때, 결합확률
- 규칙 생성 알고리즘
1) 브루트포스(모든 경우의 수 다 살펴보기)
- 장점 : 모든 좋은 조합 찾아낼 수 있음
- 단점 : 너무 큰 연산량 → 적용 못함
2) A priori
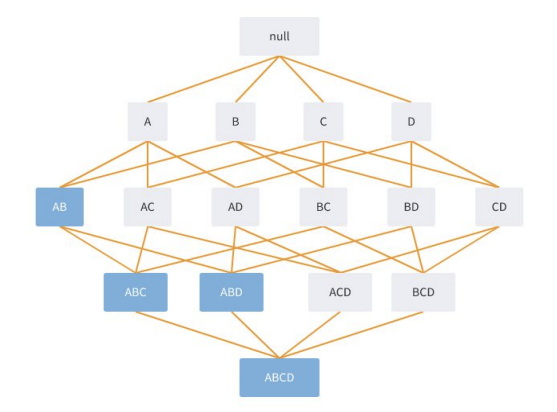
- 정의 : 빈번하게 등장하는 아이템셋에 대해서만 고려
- 지지도의 Anti-monotone property 활용
- 한 상품 집합 지지도, 그 부분집합의 지지도를 넘지 못함
- P(A) 지지도 0.2 → P(A,B) 지지도는 0.2를 넘을 수 없음
- 불필요한 조합을 배제 → 연산량 줄임
💻코드 예제
- 데이터 형식 : 열 index) 장바구니 번호 or 송장 번호 / 행 index) 상품 정보
- groupby 연산을 통한 배열 변경

- A priori 적용 코드
from mlxtend.frequent_patterns import apriori, association_rules
basket_sets = basket.applymap(encode_units) # applymap() : 전체에 적용
# Use the Apriori algorithm to find frequent itemsets
frequent_itemsets = apriori(basket_sets, min_support=0.03, use_colnames=True) # 최소 지지도 설정
# Generate association rules
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1)
'추천시스템' 카테고리의 다른 글
| [추천시스템] 기초 선형 수학 (0) | 2024.03.28 |
|---|---|
| [추천시스템] 컨텐츠 기반 필터링(Content-Based Filtering) (0) | 2024.03.28 |
| [추천시스템] 기본 추천시스템 - Best Seller 추천/사용자 집단별 추천 (0) | 2023.08.04 |
| [추천시스템] 주요 추천시스템 알고리즘 (0) | 2023.08.01 |



