
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 포스코 아카데미
- 모델링
- 추천시스템
- Brightics Studio
- 영상제작기
- Brigthics Studio
- 데이터 분석
- 팀 분석
- 브라이틱스
- Brigthics를 이용한 분석
- 삼성 SDS Brigthics
- 캐글
- 브라이틱스 서포터즈
- Brightics를 이용한 분석
- 삼성SDS Brigthics
- 혼공
- 삼성SDS Brightics
- Brigthics
- 혼공머신러닝딥러닝
- Brightics
- 혼공학습단
- 포스코 청년
- 삼성 SDS
- 직원 이직여부
- 삼성SDS
- 노코드AI
- 개인 의료비 예측
- 혼공머신
- 데이터분석
- 직원 이직률
Archives
- Today
- Total
데이터사이언스 기록기📚
[추천시스템] 기본 추천시스템 - Best Seller 추천/사용자 집단별 추천 본문
📌 추천시스템 진행 과정
[데이터 불러오기]데이터 읽기
[추천시스템] Best Seller 추천 or 사용자 집단별 추천
[추천시스템 평가] 추천 시스템 정확도 측정
✔️데이터 읽기
- MovieLens 100K 데이터 활용
# 사용자 정보
import pandas as pd
u_cols = ['user_id', 'age', 'sex', 'occupation', 'zip_code']
users = pd.read_csv('u.user',sep='|', names=u_cols, encoding = 'latin-1')
users = users.set_index('user_id')
users.head()# 영화 정보
# 장르 unknow ~ Western 0-1 바이너리로 표현(원핫인코딩)
i_cols = ['movie_id', 'title', 'release date', 'video release date', 'IMDB URL',
'unknown', 'Action', 'Adventure', 'Animation', 'Children\'s', 'Comedy', 'Crime',
'Documentary', 'Drama', 'Fantasy', 'Film-Noir', 'Horror', 'Musical', 'Mystery',
'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']
movies = pd.read_csv('u.item', sep='|', names=i_cols, encoding='latin-1')
movies = movies.set_index('movie_id')
movies.head()# 영화 평점 정보
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv('u.data', sep='\t', names=r_cols, encoding='latin-1')
ratings = ratings.set_index('user_id')
ratings.head()✔️Best Seller 추천
- 추천 방법
- 하나의 영화(제품)에 대한 평가를 평균 → 평균값이 가장 높은 것 순서대로 추천
- 사용 예시
- 개별 사용자 정보가 없는 경우
- 정확도에 관계없이 가장 간단한 추천을 하는 경우
- 실습
# best-seller 추천
def recom_movie1(n_items):
movie_sort = movie_mean.sort_values(ascending=False)[:n_items]
recom_movies = movies.loc[movie_sort.index]
recommendations = recom_movies['title']
return recommendations
movie_mean = ratings.groupby(['movie_id'])['rating'].mean()
recom_movie1(5)# 상단과 같은 코드를 1줄로 작성
def recom_movie2(n_items):
return movies.loc[movie_mean.sort_values(ascending=False)
[:n_items].index]['title']
movie_mean = ratings.groupby(['movie_id'])['rating'].mean()
recom_movie1(5)
✔️사용자 집단별 추천
- 작동 방식
- 비슷한 특성의 사람들을 소집단으로 형성 → 각 집단의 평점평균으로 추천
- 소집단 형성 기준 : 성별, 나이, 직업 (가정 : 성별, 직업, 나이가 비슷하면 영화에 대한 취향이 비슷할 것이다)
- 실습
- 예측 : 한 사용자 - 한 영화 조합
- 소그룹을 만들기 위해 users 데이터가 필요 → 예측하기 위해 평점 데이터 + 사용자 데이터 → 평점 데이터 Full Matrix
- 평점 데이터 Full Matrix에는 모든 조합이 표시되어야하기 때문에, 사용자가 보지 않은 영화는 NaN으로 표기
# 데이터 다시 불러오기
u_cols = ['user_id', 'age', 'sex', 'occupation', 'zip_code']
users = pd.read_csv('u.user',sep='|', names=u_cols, encoding = 'latin-1')
i_cols = ['movie_id', 'title', 'release date', 'video release date', 'IMDB URL',
'unknown', 'Action', 'Adventure', 'Animation', 'Children\'s', 'Comedy', 'Crime',
'Documentary', 'Drama', 'Fantasy', 'Film-Noir', 'Horror', 'Musical', 'Mystery',
'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']
movies = pd.read_csv('u.item', sep='|', names=i_cols, encoding='latin-1')
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv('u.data', sep='\t', names=r_cols, encoding='latin-1')
# 필요없는 데이터 제거
ratings = ratings.drop('timestamp', axis = 1)
movies = movies[['movie_id', 'title']]# train-test set 분리
from sklearn.model_selection import train_test_split
x = ratings.copy() # 원본 보존하기 위해 copy 사용
y = ratings['user_id'] # user_id 기준으로 데이터 비율을 동일하게 나누기 위함
x_train, x_test, y_train, y_test = train_test_split(x,y, test_size=0.25,
stratify=y)# 정확도 계산
def RMSE(y_true, y_pred):
return np.sqrt(np.mean((np.array(y_true) - np.array(y_pred))**2))
# 모델별 RMWSE를 계산하는 함수
def score(model):
id_pairs = zip(x_test['user_id'], x_test['movie_id'])
y_pred = np.array([model(user, movie) for (user,movie) in id_pairs]) # 영화 별점 평균
y_true = np.array(x_test['rating']) # 한 사람이 평가한 영화 별점
return RMSE(y_true, y_pred)
# train data Full Matrix
rating_matrix = x_train.pivot(index='user_id', columns='movie_id', values='rating')# 전체 평균으로 예측치를 계산하는 기본 모델
def best_seller(user_id, movie_id):
try:
rating = train_mean[movie_id]
except:
rating = 3.0
return rating
train_mean = x_train.groupby(['movie_id'])['rating'].mean()
score(best_seller) # 1.0282075116829525- 성별로 집단 나누기
- 성별만 사용하면 추천 정확도를 크게 개선하지 못함
# Full matrix + 사용자 데이터
merged_ratings = pd.merge(x_train, users) # 공통 키를 가진 기준으로 합침
users = users.set_index('user_id')
# gender별 평점평균 계산
# 영화와 성별 구분시킨 평점평균 계산
g_mean = merged_ratings[['movie_id', 'sex','rating']].groupby(['movie_id', 'sex'])['rating'].mean()### Gender 기준 추천 ###
# gender별 평균 예측치를 돌려주는 함수
def cf_gender(user_id, movie_id):
if movie_id in rating_matrix:
gender = users.loc[user_id]['sex']
if gender in g_mean[movie_id]:
gender_rating = g_mean[movie_id][gender]
else:
gender_rating = 3.0
else:
gender_rating = 3.0
return gender_rating
score(cf_gender) #1.0403672067440801
✔️추천시스템 정확도 측정
- 추천시스템 성능 확인(정확도) 지표
- 예측 모델 : MAE, RMSE
- 랭킹 모델 : (좋아요/싫어요) MAP, MAR
(점수) NDCG
- 현재는 RMSE로 성능 확인
- RMSE가 작을 수록 정확 (예측이 정확할 수록 차이가 감소하기 때문)
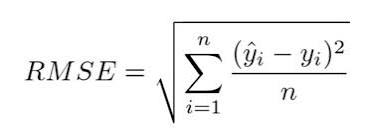
- 실습
# RMSE 함수
# 정확도 계산
def RMSE(y_true, t_pred):
return np.sqrt(np.mean((np.array(y_true) - np.array(y_pred))**2))rmse = []
for user in set(ratings.index):
y_true = ratings.loc[user]['rating']
y_pred = movie_mean[ratings.loc[user]['movie_id']] # 사용자가 본 영화 전체 평균 평점
accuracy = RMSE(y_true, y_pred)
rmse.append(accuracy)
print(np.mean(rmse))참고문헌
- Python을 이용한 개인화 추천시스템
728x90
'추천시스템' 카테고리의 다른 글
| [추천시스템] 기초 선형 수학 (0) | 2024.03.28 |
|---|---|
| [추천시스템] 컨텐츠 기반 필터링(Content-Based Filtering) (0) | 2024.03.28 |
| [추천시스템] 고전적인 추천 알고리즘 (0) | 2024.03.06 |
| [추천시스템] 주요 추천시스템 알고리즘 (0) | 2023.08.01 |
'추천시스템' Related Articles
more



