
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 팀 분석
- 데이터 분석
- 삼성SDS Brightics
- 브라이틱스
- 브라이틱스 서포터즈
- Brightics
- 삼성 SDS Brigthics
- Brigthics
- 혼공학습단
- 데이터분석
- 캐글
- 노코드AI
- 추천시스템
- 삼성SDS
- 직원 이직률
- 혼공머신
- 삼성SDS Brigthics
- 포스코 청년
- 모델링
- 혼공
- 개인 의료비 예측
- Brigthics를 이용한 분석
- 영상제작기
- Brightics를 이용한 분석
- 혼공머신러닝딥러닝
- Brigthics Studio
- 삼성 SDS
- 직원 이직여부
- Brightics Studio
- 포스코 아카데미
- Today
- Total
데이터사이언스 기록기📚
[이것이 취업을 위한 코딩테스트다 with 파이썬] Ch.6 정렬 본문
[이것이 취업을 위한 코딩테스트다 with 파이썬] Ch.6 정렬
syunze 2022. 4. 19. 17:591. 기준에 따라 데이터를 정렬
정렬 알고리즘 개요
- 정렬(Sorting) : 데이터를 특정한 기준에 따라서 순서대로 나열하는 것.
- 정렬 알고리즘 특징 : 이진 탐색의 전처리 과정
- 정렬 알고리즘 종류 : 선택 정렬, 삽입 정렬, 퀵 정렬, 계수 정렬
- 알고리즘의 효율성 이해할 수 있음(상황에 적절하지 못한 알고리즘 사용 → 비효율적 동작)
리스트를 뒤집는 연산 : O(N)의 시간복잡도
선택 정렬
- 선택 정렬(Selection Sort) : 매번 가장 작은 것을 선택
- 데이터가 무작위로 여러 개 있을 때, 이 중에서 가장 작은 데이터를 선택하여 맨 앞 데이터와 바꿈.
- 그 다음 작은 데이터를 선택해 앞에서 두 번째 데이터와 바꾸는 과정 반복.
- 예제
- 가장 작은 데이터를 앞으로 보내는 과정 N - 1번 반복
(회색카드 : 정렬되지 않은 데이터 중 가장 작은 데이터)

# 선택 정렬 예제
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
for i in range(len(array)):
min_index = i # 가장 작은 원소의 인덱스
for j in range(i + 1, len(array)):
if array[min_index] > array[j]:
min_index = j
array[i], array[min_index] = array[min_index], array[i] # 스와프
print(array)+) 스와프(Swap) : 특정한 리스트가 주어졌을 때, 두 변수의 위치를 변경하는 작업.
- 선택 정렬의 시간 복잡도
- N - 1번 만큼 가장 작은 수를 찾아서 맨 앞으로 보내기
- 매번 가장 작은 수를 찾기 위해서 비교연산 필요
→ 시간 복잡도 근사치 O(N(N+1) / 2) = O((N**2+N) / 2) = 시간 복잡도 O(N**2)
→ 다른 알고리즘에 비해 매우 비효율적(10,000개 이상이면 정렬속도 급격히 느려짐)
→ 특정한 리스트에서 가장 작은 데이터를 찾는 일이 코딩 테스트에서 많음
삽입 정렬
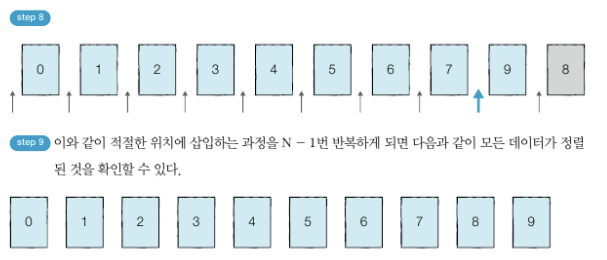
- 삽입 정렬(Insertion Sort) : 특정한 데이터를 적절한 위치에 삽입
- 데이터를 하나씩 확인하며, 각 데이터를 적절한 위치에 삽입하는 정렬
- 특징
- 구현 난이도 : 선택 정렬 << 삽입 정렬
- 실행 시간 : 삽입정렬 < 선택 정렬
- 데이터가 거의 정렬 되어 있을 때 효율적
- [데이터가 적절한 위치 들어가기 이전] 데이터는 이미 정렬되어 있다고 가정 → 적절한 위치에 삽입
(첫 번째 데이터는 자체로 정렬되어있다고 판단하여, 두 번째 데이터부터 삽입 정렬 시작) - 정렬이 이루어진 원소는 항상 오름차순 유지
- [코드 작성] 한 칸씩 왼쪽으로 이동하다 자신보다 작은 데이터 만나면 그 위치에서 멈춘다.
(앞에 데이터와 서로 바꾸기)
- 예제

# 삽입 정렬 예제
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
for i in range(1, len(array)):
for j in range(i, 0, -1):
if array[j] < array[j - 1]:
array[j], array[j - 1] = array[j - 1], array[j]
else:
# 자기보다 작은 데이터를 만나면 그 위치에서 멈춤
break
print(array)
- 삽입 정렬의 시간복잡도
→ 이중 for문으로 시간복잡도 O(N**2)
→ 삽입 정렬은 현재 리스트의 데이터가 거의 정렬되어 있는 상태에서 매우 빠르게 동작
(최선의 경우 : O(N))
퀵 정렬 (⭐가장 많이 사용)
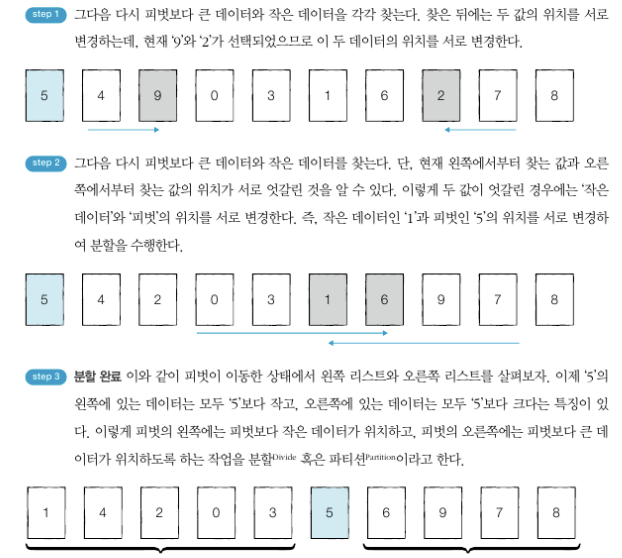
- 퀵 정렬(Quick Sort): 기준 데이터를 설정하고 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾸어 리스트를 반으로 나누는 방식으로 동작.
- 피벗(Pivot) : 큰 숫자와 작은 숫자를 교환할 때, 교환하기 위한 '기준'
→ 퀵 정렬 수행 전 어떻게 수행할 것인지 미리 명시 - 피벗을 설정하여 정렬 수행
→ (피벗 기준) 왼쪽, 오른쪽 리스트 각각 다시 정렬 수행 - 재귀함수 동작 원리와 같음
→ 퀵 정렬이 끝나는 조건 : 리스트의 원소 1개
- 특징
- 지금까지 배운 정렬 알고리즘 중 가장 많이 사용되는 알고리즘
- 퀵 정렬만큼 빠른 알고리즘 - 병합 정렬
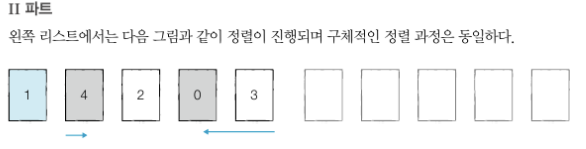
- 예제(호어 분할 방식 : 리스트에서 첫 번째 데이터를 피벗으로 정한다.)

- 왼쪽 리스트와 오른쪽 리스트를 개별적으로 정렬
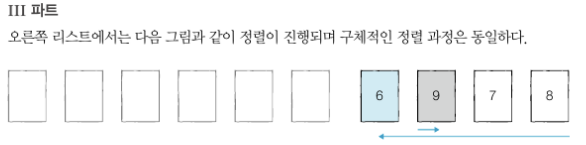
- 전통 퀵 정렬 분할 방식
# 퀵 정렬 예제
array = [5, 7, 9, 0, 3, 1, 6, 2, 4, 8]
def quick_sort(array, start, end):
if start >= end: # 원소가 1개인 경우 종료
return
pivot = start # 피벗 = 첫번째 원소
left = start + 1
right = end
while left <= right:
# 피벗 보다 큰 데이터를 찾을 때 까지 반복
while left <= end and array[left] <= array[pivot]:
left += 1
# 피벗보다 작은 데이터를 찾을 때까지 반복
while right > start and array[right] >= array[pivot]:
right -= 1
if left > right: # 엇갈렸다면 작은 데이터와 피벗을 교체
array[right], array[pivot] = array[pivot], array[right]
else: # 엇갈리지 않았다면 작은 데이터와 큰 데이터를 교체
array[left], array[right] = array[right] , array[left]
# 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행
quick_sort(array, start, right - 1)
quick_sort(array, right + 1, end)
quick_sort(array, 0, len(array) - 1)
print(array)- 파이썬 장점 이용한 퀵 정렬 소스코드
- 단점 :피벗 - 데이터 비교 연산 횟수 증가, 시간 면에서 조금 비효율적
- 장점 :직관적이고 기억하기 쉬움
# 퀵 정렬 예제_2
array = [ 5, 7, 9, 0, 3, 1, 6, 2, 4, 8]
def quick_sort(array):
# 리스트가 하나 이하의 원소만을 담고 있다면 종료
if len(array) <= 1:
return array
pivot = array[0] # 피벗을 첫 번째 원소
tail = array[1:] # 피벗을 제외한 리스트
left_side = [x for x in tail if x <= pivot] # 분할된 왼쪽 부분
right_side = [x for x in tail if x > pivot] # 분할된 오른쪽 부분
# 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬을 수행하고, 전체 리스트를 반환
return quick_sort(left_side) + [pivot] + quick_sort(right_side)
print(quick_sort(array))
- 퀵 정렬의 시간 복잡도
→ 평균 시간 복잡도 O(NlogN)
→ 이미 데이터가 정렬되어 있는 경우 : 최악의 시간 복잡도 O(N**2)
→ 기본 정렬 라이브러리 이용하면 O(NlogN) 보장
계수 정렬
- 계수정렬(Count Sort) : 특정한 조건(데이터의 크기 범위가 제한 되어 정수 형태로 표현할 수 있을 때)이 부합할 때만 사용할 수 있지만 매우 빠른 알고리즘.
- 특징
- (모든 데이터가 양의 정수일때) 데이터의 개수 N, 데이터 중 최대값이 K
→최악의 경우 시간복잡도 O(N+K) 보장 - 가장 큰 데이터 - 가장 작은 데이터 = 1,000,000를 넘지 않을때 효과적으로 사용 가능
- 계수 정렬 사용 시, 모든 범위를 담을 수 있는 크기의 리스트를 선언해야 함
- 데이터 값을 비교한 후 위치 변경하는 방식 X
→ (일반적으로) 별도의 리스트를 선언하고 그 안에 정렬에 대한 정보를 담음
- 예시
- 원래 리스트 : 초기 단계 상태의 리스트
새 리스트 : 리스트의 인덱스가 모든 범위를 포함할 수 있도록 생성 - 새 리스트에 각 데이터가 몇 번 등장했는지 횟수가 기록됨
→ 새 리스트에 저장된 데이터 자체가 정렬된 형태 - 정렬된 결과 확인 - 새 리스트 첫 번째 데이터부터 등장 횟수 만큼 인덱스를 출력하면 됨
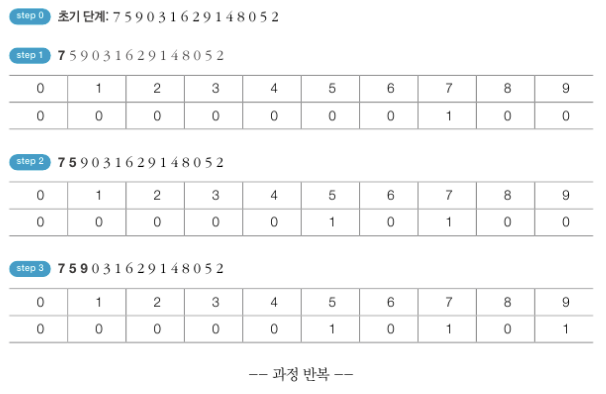
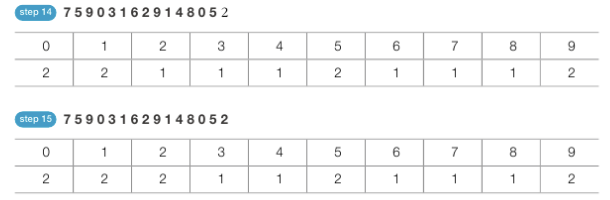
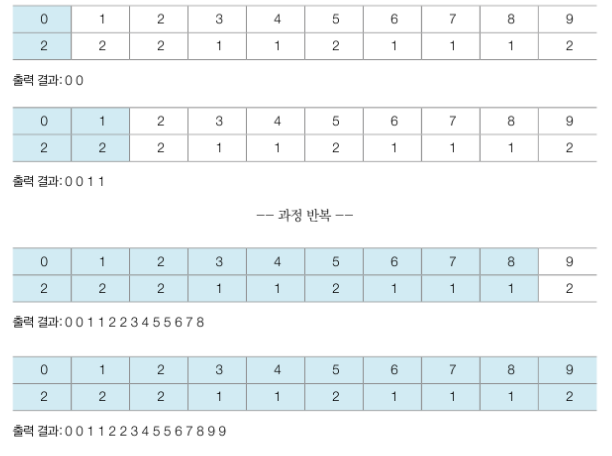
# 계수 정렬 예제
# 모든 원소의 값이 0보다 크거나 같다고 가정
array = [7, 5, 9, 0, 3, 1, 6, 2, 9, 1, 4, 8, 0, 5, 2]
# 모든 범위를 포함하는 리스트 선언(모든 값은 0으로 초기화)
count = [0] * (max(array) + 1)
for i in range(len(array)):
count[array[i]] += 1 # 각 데이터에 해당하는 인덱스의 값 증가, count = 원소의 개수 담는 list
for i in range(len(count)): # 원소 0~9까지 반복
for j in range(count[i]): # count 안 원소 개수 담긴 만큼 반복
print(i, end = ' ') # 띄어쓰기를 구분으로 등장한 횟수만큼 인덱스 출력
- 시간 복잡도
→ (데이터 양의 정수일때) 데이터 개수 N, 데이터 중 최대값의 크기 K => 시간복잡도 O(N+K)
→ 최대값의 크기만큼 반복을 수행. 데이터의 범위만 한정되어 있으면 효과적으로 사용 가능, 항상 빠르게 동작.
+) 기수 정렬 : 계수 정렬에 비해서 동작은 느리지만, 처리할 수 있는 정수의 크기는 큼. 알고리즘 원리나 소스코드는 복잡
- 공간 복잡도
→ 공간 복잡도 O(N+K)
- 동일한 값을 가지는 데이터가 여러 개 등장할 때 적합. 데이터의 크기가 한정.
- 데이터 특성 파악하기 어려울 때 퀵 정렬 이용하는 것 유리
파이썬의 정렬 라이브러리
- sorted()
- (퀵 정렬과 동작 방식이 비슷한) 병합 정렬을 기반으로 만들어짐
- 병합 정렬 : 퀵 정렬보다 느리지만, 최악의 경우 시간 복잡도 O(NlogN) 보장
- 입력 : 리스트, 딕셔너리 자료형 → 출력 : 정렬된 결과
# sorted 소스코드
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
result = sorted(array)
print(result)
# 출력
[0,1,2,3,4,5,6,7,8,9]
- sort()
- 리스트 내장함수
- 별도의 정렬된 리스트 반환X, 내부 원소가 바로 정렬
# sort 소스코드
array = [7, 5, 9, 0, 3, 1, 6, 2, 4, 8]
array.sort()
print(array)
# 출력
[0,1,2,3,4,5,6,7,8,9]
- sorted(), sort(): key 매개변수를 입력으로 받기
- key값으로 하나의 함수 들어감, 정렬 기준
# 정렬 라이브러리에서 key를 활용한 소스코드
array = [('바나나', 2), ('사과', 5), ('당근', 3)]
# 두 번째 원소를 기준으로 정렬
def setting(data):
return data[1]
result = sorted(array, key = setting)
print(result)
# 출력
[('바나나',2), ('당근',3), ('사과',5)]
- 정렬 라이브러리의 시간 복잡도
→ 최악의 경우에도 시간 복잡도 O(NlogN)을 보장
- 정렬 라이브러리 특징
- 퀵 정렬 구현할 때 보다 효과적
- 하이브리드 방식 =병합 정렬 + 삽입 정렬
- 정렬 라이브러리 사용해야하는 상황
- (문제의 별도 요구 없을 시) 단순 정렬 → 기본 정렬 라이브러리 사용
- (데이터 범위 한정, 더 빠르게 동작) 계수 정렬
- 정렬 알고리즘 문제 유형
1) 정렬 라이브러리로 풀 수 있는 문제 : 단순한 정렬 기법 알고 있는지
2) 정렬 알고리즘 원리에 대해서 물어보는 문제 : 선택 정렬, 삽입 정렬, 퀵 정렬 등의 원리를 알고 있어야 문제 풀 수 있음
3) 더 빠른 정렬이 필요한 문제 : 퀵 정렬 기반의 정렬 기법으로는 풀 수 없음, 다른 정렬 알고리즘을 이용 or 문제에서 기존에 알려진 알고리즘 구조적 개선
2. 위에서 아래로
📌문제
수열에 있는 크기에 상관 없이 나열된 다양한 수.
수열을 내림차순으로 정렬하는 프로그램 만들기.
📌입력 조건
- 첫째 줄에 수열에 속해 있는 수의 개수 N이 주어진다.(1 <= N <= 500)
- 둘째 줄부터 N + 1번째 줄까지 N개의 수가 입력된다. 수의 범위는 1이상 100,000 이하의 자연수이다.
📌출력 조건
입력으로 주어진 수역이 내림차순으로 정렬된 결과를 공백으로 구분하여 출력. 동일한 수의 순서는 자유롭게 출력해도 괜찮다.
📌입력 예시
3
15
27
12
📌출력 예시
27 15 12
📌나의 문제풀이
- 리스트 내장함수 이용
n = int(input())
num = []
for i in range(n):
num.append(int(input()))
num.sort(reverse = True)
for j in num:
print(j, end = ' ')
📌책의 문제풀이
- 파이썬 내장함수 이용
- 리스트 내장함수가 아니기 때문에 결과 출력 시 for문 사용
# N을 입력받기
n = int(input())
# N개의 정수를 입력받아 리스트에 저장
array = []
for i in range(n):
array.append(int(input()))
# 파이썬 기본 정렬 라이브러리를 이용하여 정렬 수행
array = sorted(array, reverse = True)
# 정렬이 수행된 결과를 출력
for i in array:
print(i, end =' ')3. 성적이 낮은 순서로 학생 출력하기
📌문제
N명의 학생 정보 → 학생 이름, 성적
성적이 낮은 순서대로 학생의 이름을 출력하는 프로그램 작성.
📌입력 조건
- 첫 번째 줄에 학생의 수 N이 입력된다. (1 <= N <= 100,000)
- 두 번째 줄부터 N+1번째 줄에는 학생의 이름을 나타내는 문자열 A와 학생의 성적을 나타내는 정수 B가 공백으로 구분되어 입력된다. 문자열 A의 길이와 학생의 성적은 100 이하의 자연수이다.
📌출력 조건
모든 학생의 이름을 성적이 낮은 순서대로 출력한다. 성적이 동일한 학생들의 순서는 자유롭게 출력해도 괜찮다.
📌입력 예시
2
홍길동 95
이순신 77
📌출력 예시
이순신 홍길동
📌나의 문제풀이
n = int(input())
name_score = []
for i in range(n):
name_score.append(tuple(input().split()))
def score(name_score):
for j in range(len(name_score)):
return name_score[j][1]
result = sorted(name_score, key = score, reverse = True)
for k in range(len(result)):
print(result[k][0], end = ' ')
📌책의 문제풀이
- 계수정렬 이용해도 됨
- 학생 정보 (점수, 이름) 묶은 뒤 → lambda 함수로 점수 기준으로 정렬 수행
# N을 입력받기
n = int(input())
# N명의 학생 정보를 입력받아 리스트에 저장
array = []
for i in range(n):
input_data = input().split()
# 이름은 문자열 그대로, 점수는 정수형으로 변환하여 저장
array.append((input_data[0], int(input_data[1])))
# 키를 이용하여, 점수를 기준으로 정렬
array = sorted(array, key = lambda student: student[1]) # 오름차순으로 정렬
# 정렬이 수행된 결과를 출력
for student in array:
print(student[0], end = ' ')
📌나의 문제풀이와 책의 문제풀이 비교
- 점수를 int처리 안한 것 → 내 문제풀이에서는 문자로 인식해서 잘못 정렬될 가능성 높음
- 문자로 인식한 숫자 vs 숫자로 인식한 숫자 정렬은 천지차이. 점수는 꼭 int 처리하기.
- 정렬은 기본 오름차순!!!
# 문자인 숫자 정렬_1
a = ['12','44','33','1','4']
result = sorted(a)
print(result)
# 출력 : ['1', '12', '33', '4', '44']
# 문자인 숫자 정렬_2
a = ['12','44','33','1','4']
result = sorted(a, reverse = True)
print(result)
# 출력 : ['44', '4', '33', '12', '1']
# 전혀 숫자 고려하지 않음.
4. 두 배열의 원소 교체
📌문제
두 개의 배열 A,B - 각각 N개의 원소로 구성, 배열의 원소는 모두 자연수.
최대 K번의 바꿔치기 연산 수행(배열 A에 있는 원소 하나 <-> 배열 B에 있는 원소 하나)
→ 최종 목표 : 배열 A의 모든 원소의 합이 최대가 되도록 하는 것.
📌입력조건
- 첫 번째 줄에 N,K가 공백으로 구분되어 입력된다.(1 <= N <= 100,000, 0 <= K <= N)
- 두 번째 줄에 배열 A의 원소들이 공백으로 구분되어 입력된다. 모든 원소는 10,000,000보다 작은 자연수이다.
- 세 번째 줄에 배열 B의 원소들이 공백으로 구분되어 입력된다. 모든 원소는 10,000,000보다 작은 자연수이다.
📌출력 조건
최대 K번의 바꿔치기 연산을 수행하여 만들 수 있는 배열A의 모든 원소의 합의 최댓값을 출력한다.
📌입력 예시
5 3
1 2 5 4 3
5 5 6 6 5
📌출력 예시
26
📌나의 문제풀이
n, k = map(int,input().split())
a = list(map(int,input().split()))
b = list(map(int, input().split()))
# a 배열 오름차순정렬 -> [0][1][2]
# b 배열 내림차순정렬 -> [0][1][2]
# a,b 배열 정렬된 부분 스와프로 바꿔서 연산
a.sort()
b.sort(reverse = True)
for i in range(3):
a[i], b[i] = b[i], a[i]
result = 0
for sum in a:
result += sum
print(result)
📌책의 문제풀이
- (조건) 배열 A에서 가장 작은 원소가 배열 B에서 가장 큰 원소보다 작을 때에만 교체 수행
- 첫 번째 인덱스부터 차례대로 비교 -> A < B일때만 교체
- 시간 복잡도 O(NlogN)을 보장하는 정렬 알고리즘 사용
n, k = map(int, input().split()) # n과 k를 입력받기
a = list(map(int, input().split()))
b = list(map(int, input().split()))
a.sort()
b.sort(reverse = True)
# 첫 번째 인덱스부터 확인하며, 두 배열의 원소를 최대 K번 비교
for i in range(k):
# A의 원소가 B의 원소보다 작은 경우
if a[i] < b[i]:
# 두 원소를 교체
a[i], b[i] = b[i], a[i]
else: # A의 원소가 B의 원소보다 크거나 같을 때, 반복문을 탈출
break
print(sum(a))
📌나의 문제풀이와 책의 문제풀이 비교
- 배열의 원소 큰지, 작은지 비교하기
'Coding Test > 이것이 취업을 위한 코딩테스트이다 with 파이썬' 카테고리의 다른 글
| [이것이 취업을 위한 코딩테스트다 with 파이썬] Ch.8 다이나믹 프로그래밍 (0) | 2022.04.29 |
|---|---|
| [이것이 취업을 위한 코딩테스트다 with 파이썬] Ch.7 이진 탐색 (0) | 2022.04.22 |
| [이것이 취업을 위한 코딩테스트다 with 파이썬] Ch.4 구현 (0) | 2022.04.14 |
| [이것이 취업을 위한 코딩테스트다 with 파이썬] Ch.3 그리디 (0) | 2022.03.25 |
| [이것이 취업을 위한 코딩테스트다 with 파이썬] 코딩테스트를 위한 파이썬 문법_입출력,주요 라이브러리의 문법과 유의점 (0) | 2022.03.18 |


