
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 삼성 SDS
- 노코드AI
- Brightics를 이용한 분석
- 데이터 분석
- 포스코 아카데미
- Brigthics Studio
- 삼성 SDS Brigthics
- Brigthics를 이용한 분석
- 모델링
- 혼공학습단
- 캐글
- Brightics Studio
- 포스코 청년
- 직원 이직률
- 팀 분석
- 개인 의료비 예측
- Brigthics
- 데이터분석
- 영상제작기
- 삼성SDS
- 혼공머신
- 브라이틱스
- 혼공머신러닝딥러닝
- Brightics
- 혼공
- 삼성SDS Brigthics
- 추천시스템
- 직원 이직여부
- 삼성SDS Brightics
- 브라이틱스 서포터즈
- Today
- Total
데이터사이언스 기록기📚
[시계열 분석] CH.3 정리 본문
Ch.3 시계열 탐색적 자료 분석(EDA)
① 일반적인 데이터 응용 기법 (히스토그램, 도표, 그룹화 연산)
② 시간 기법 - 데이터가 서로 시간관계가 있는 상황에서만 사용 가능
3-1. 친숙한 방법
- 비시계열 방법과 동일
- (비시계열 방법) EDA 시 의문을 가지는 것
- 쓸 수 있는 열
- 각 열에 가지는 값의 범위
- 가장 알맞은 측정 단위
- 상관관계 가지는열
- 관심 대상 변수의 전체 평균, 분산
=> 도표, 요약 통계, 히스토그램, 산점도로나타내서 확인 가능
- (시계열 방법) EDA 시 의문을 가지는 것
- 분석값의 범위 (기간에 따라 값이 달라지는지)
- 데이터 일관성을 가지고 균등 or 동작 방식의 변화?
=> 시간 + 도표, 요약 통계, 히스토그램, 산점도
+그룹화 연산
- 시간축을 다른 관계와 상호작용할 수 있는 방법이 많음
- 외부요인 규칙 변화) 변화 시점 기준으로 따로 분석
- 하나의 계열(전체) - 개인으로 나누면 명확
| 예시 | |
| 시계열 | 월별 평균, 주별 중앙값 |
| 비시계열 | 연령, 성별, 이웃 그룹 평균 |
| 시계열 + 비시계열 | 성별로 월 평균 섭취 칼로리, 나이별 주별 수면 중앙값 |
3-1-1. 도표 그리기
- 시계열 데이터 시계열로 고려하지 않음 -> 개별 그래프로 그리기
- 함수 정리
| R | 설명 |
| frequency | 데이터 연간 빈도 |
| start, end | 처음과 마지막 데이터 출력 |
| window | 데이터 시간 부분 범위 얻음 |
3-1-2. 히스토그램

- diff 차분
- (위) 실체값 그 자체는 유용한 정보 없음
- (아래) 시간축 활용) 시간내 인접한 데이터간의 차이 : 추세 제거한 정규분포 형태
- 금융에서 현재와 다음 측정치 변화 정도가 중요!(차분, diff)
- 추세를 가진 데이터에 변형을 가해야 함
=> 데이터 샘플링 or 통계요약 시 시간의 규모에 관심 가져야 함 (장기 or 일일 데이터 중 어떤 것을 더 중요하게 여길 것인가?)
3-1-3. 산점도
- 산점도 이용 후 결정
- 특정 시간 두 주식 관계 - 두 주식 시간에 따른 가격 변동 연관성

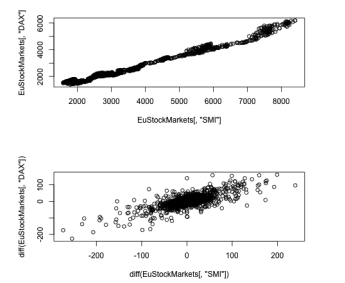
- 주가의 상승, 하락 알 때 동일한 시점의 상관관계 -> 주가와 관련된 다른 주가도 오르고 내림 -> 시간상 먼저 알게 된 한 주가의 변동으로 나중에 다른 주가의 변동 예측
- (산점도 확인 전) 두 주가 중 하나를 1만큼 시간을 앞당겨야 함 - R의 lag()(직전 값)
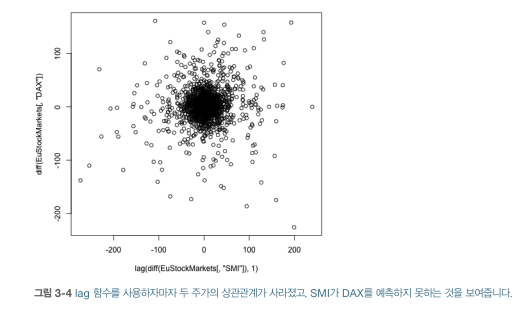
- 시계열 데이터 중요한 점
- 시계열을 의식하지않으면 정확한 내용을 파악할 수 없음
- 데이터 동작방식 이해 방법 - 시간에 따른 변화, 서로 다른 시점의 데이터 사이의 관계
3-2. 시계열에 특화된 탐색법
- 시계열 분석 방법 : 같은 계열에 속한 서로 다른 시간의 값 관계에 집중
- 시계열 분류 시 사용 개념
- 정상성(stationarity) : 시계열이 정상성이 된다는 의미. 정상성에 대한 통계적 검사
- 자체상관(self correlation) : 시계열 그 자체의 연관성. 연관성이 시계열 내재된 역동성을 보여줌. 시계열의 현재 데이터와 자신의 과거 데이터와의 상관관계를 의미
- 허위상관(spurious correlation) : 상관관계 허위. 둘 이상의 변수가 통계적으로 상관되어 있지만 인과관계가 없는 관계
- 개념 적용 기법
- 롤링윈도, 확장 윈도
- 자체상관함수
- 자기상관함수
- 편자기상관함수
- (p.119 start)
- 시계열 다룰 때 처음으로 던져보는 질문
- 시계열이 stable or not stable (안정성 반영 or 지속적인 변화 반영)
- 과거의 장기적인 행동 -> 미래의 장기적인 행동 얼마나 반영하는지
- 내부적인 역학의 존재 결정(계절 변화)
=> 자체상관을 찾기 위한 노력 -> 미래의 데이터 예측에 얼마나 밀접한 연관성을 가지는지 알 수 있음 - 역학이 알고싶은 인과관계에 어떠한 의미를 가지지 않음 -> 허위 상관 찾아야 함
3-2-1. 정상성 이해하기
- 정상 시계열은 시간이 경과하더라도 안정적인 통계적 속성 가짐
- 정의
- 정상보다 정상이 아닌 것의 배제가 수월
- (정상이 아닌 경우) 평균값이 일정하게 유지되지 않음, 분산이 일정하지 않음, 강한 계절성 보임
- 모든 시차 k에 대해 y (t+1 ~t+k)분포가 t에 의존적이지 않으면 정상
- 통계적 검정 : 특성방정식의 해가 1인지에 대한 질문. (unit root_단위근 의 존재가 없어야 함)
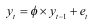
- 정상이 아닌 시계열 != 반드시 추세를 가져야 한다
- 가설검정 : 특정 과정의 정상성을 결정하는 시험(ADF)
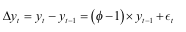
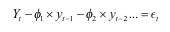
- 평가지표) ADF(Augmented Dickey-Fuller; 확대된 디키-풀러 검정) - 정상성 문제를 가장 보편적으로 평가
- H0(귀무가설) : 시계열에 단위근이 존재한다_비정상
- H1(대립가설) : 시계열에 단위근이 존재하지 않는다_정상
- +)정상성 검정이 계열의 평균 변화 여부에 중점을 둠
- 검정의 문제점
- 단위근, 준단위근을 구분하는 능력이 낮음
- 단위근에 대한 False-Positive는 적은 수의 샘플에서 꽤 일반적으로 일어남
- 비정상 시계열의 모든 종류의 문제를 검정하지 않음 (전체보다 일반 검정 or 평균분산 정상 검정 등 다양한 검정이 있음)
- +)KPSS검정 : 정상과정의 귀무가설
+) 분산은 변환에 의해 다뤄짐. 검정) 계열이 결합되었는가?(p.121_무슨말일까..)
- 정상성이 중요한 이유 : 전통적인 모델, 통계모델이 정상과정을 가정하기 때문
- 정상이 아닌 모델 : 시계열 평가 지표가 달라짐 -> 정확도 달라짐(모델의 가치 의문 생김)
- 시계열 정상화시키는 방법
- 로그와 제곱근 - 분산이 변화하는 경우에 사용
- 차분을 구하여 제거 - 추세
- 차분을 3회 이상 진행, 차분을 통해 문제 해결하기 어려움
변환은 가정을 동반!
- 제곱근 및 로그변환 : (가정) 데이터가 항상 양수, 이상치 간의 차이를 강조하지 않음(큰 값을 압축하여)
3-2-2. 윈도 함수 적용
롤링 윈도
- 정의 : 데이터를 압축 or 평활화라기 위해 데이터를 취합하는 함수
- 언어별 적용 방법
- Python : rolling 메서드는 현재 열에 대하여 일정 크기의 창(window)를 이용하여 그 window 안의 값을 추가 메서드를 통해 계산하는 메서드
02-10. 기간이동 계산 (rolling)
####DataFrame.rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, close…
wikidocs.net
- R : window width (예: 10분, 1시간, 1일 등) 를 유지한채 측정 단위시간별로 이동하면서 분석 (rollapply)
[R] 시계열 데이터의 이동 평균, 누적 평균 구하기 (Average of time series using Rolling windows vs. Expanding wi
주식을 하는 분들은 아마도 대표적인 시계열 데이터인 주가의 이동평균, 누적평균 그래프에 이미 익숙할 것입니다. 이번 포스팅에서는 R의 zoo 패키지의 rollapply() 라는 window function 의 (1) Rolling Win
rfriend.tistory.com
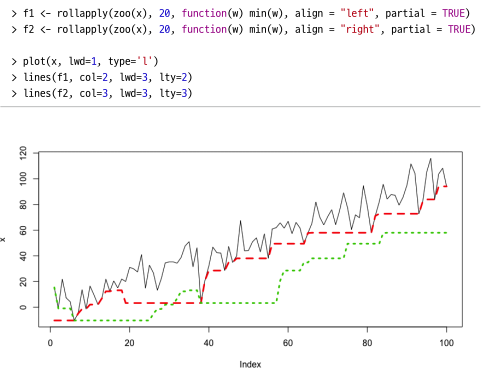
- 좌측정렬(빨강) : 미래 사건 보여줌.
- 어떤 사건을 미리 알았다면 유용할 것인가?의 탐색적 질문 -> 사전관찰 쓸모 판단할 때 유용
- 사전관찰도 유용하지 않음 = 특정 변수 유의미한 정보 가지지 않음, 어느 시점에서도 유용하지 않음
- 우측정렬(초록) : 과거 사건 보여줌.
확장윈도
- 특징
- 롤링윈도보다 덜 보편적. 적합한 애플리케이션이 제한적
- 과정이 안정적인 요약 통계 추정 시 의미 있음
- 주어진 최소 크기로 시작 -> (시계열 진행 따라) 주어진 시간 동안 모든 데이터를 포함할 때까지 확장할 수 있음
- 시간에 따른 검정통계량 추정치가 더욱 확실해짐
- 더 많은 정보 수집, 실시간으로 요약 통계 추정 시 '온라인' 상태가 유용
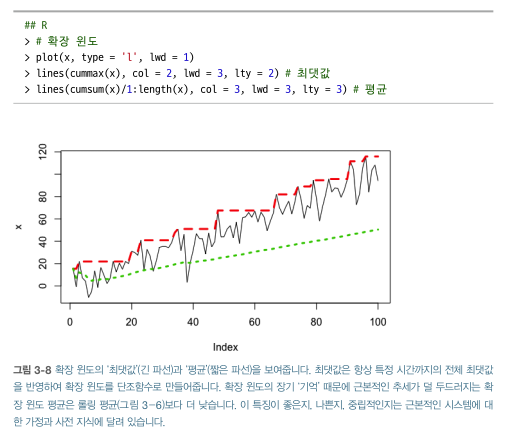
사용자 정의 롤링 함수
- 적용
- 적절한 분석에 필요한 휴리스틱 - 특정 도메인 지식에 유익한 특징을 포함하는 윈도
- 동작에 대해 알려진 기본 법칙인 있는 시계열 분석
3.2.3. 자체상관의 파악과 이해
자체상관(self correlation)
- 개념 : 특정 시점의 값이 다른 시점의 값과 상관 관계가 있음
- 예) 2개의 정보로 추세 및 상관관계 알아낼 수 있음 but 1개로는 알 수 없음
특정시점에 고정되지 않는 자기상관 -> 자체상관을 일반화 한 것
자기상관 기능
- 정의 : 어떤 신호, 자신을 지연함수로 시간상 지연 이동한 신호간의 상관관계 (서로 다른 시점의 데이터 간 선형적 연관성)
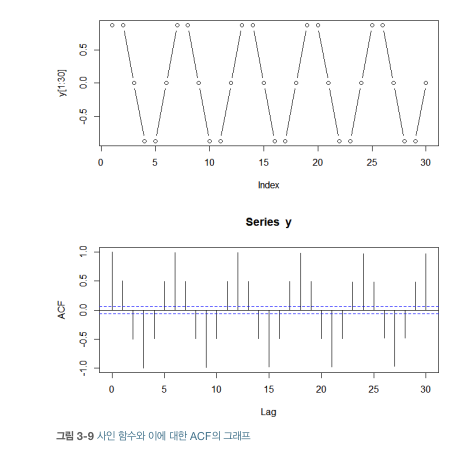
- ACF(Autocorrelation function; 자기상관함수)
- 시차 0 -상관관계 1, 시차1 - 상관관계 0.5, 시차2 -상관관계 -0.5
- ACF의 주기함수 = 원래 과정과 동일한 주기성
- sum(주기함수) 자기상관 = 각 개별함수 자기상관 합
- 양과 음의 시차에 관해 대칭을 이룸
자기 상관
1. 자기 상관 함수 (Auto-correlation Function) ㅇ 어떤 신호의 시간이동된 자기자신과의 `상관성(Correlation)` 척도 ㅇ 주요 특징 - 결정 신호이든(주기 신호,비주기 신호이든) 랜덤 신호이든, 모든 신호에
www.ktword.co.kr
편자기상관함수(PACF)
- 시계열 특정 시차에 대한 편자기상관 = 자신에 대한 그 시차의 편상관
- 특징
- 어떤 데이터가 유용한 정보를 가지는지 - 적절한 정도의 시간규모를 위한 윈도 길이 얻을 수 있음
- 어떤 데이터가 단기간의 고조파인지
- 임계영역 경계 +-1.96 *squrt(n)
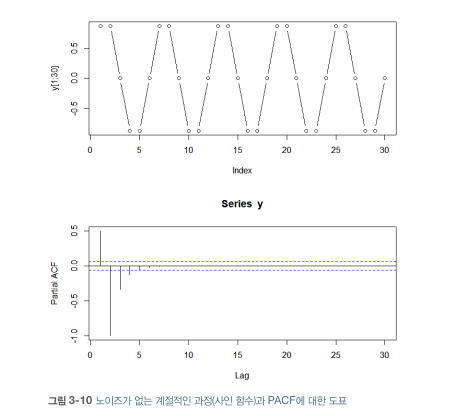
ACF와 PACF의 비교
- 노이즈가 없는 도표
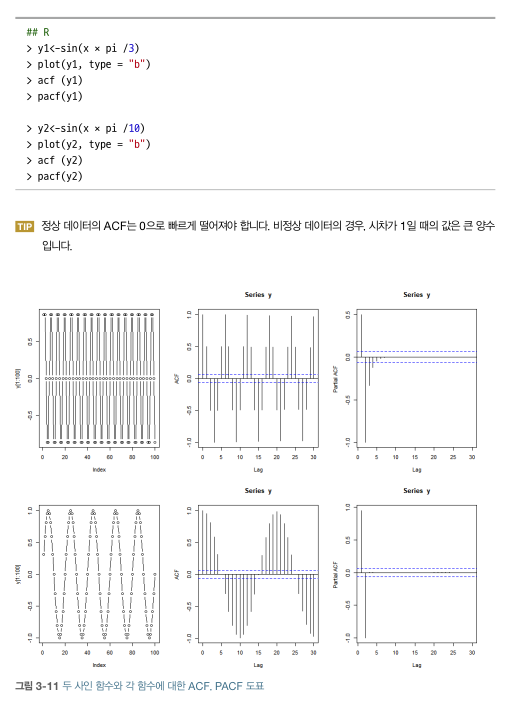
- 두 계열 더해서 비교

| 특징 | |
| ACF | 두 주기 계열의 합 ACF = 개별 ACF 양극-> 음극 바뀌는 진동이 좀 느림 |
| PACF | 원본 계열보다 계열들의 합이 중요 서로 다른 빈도의 진동이 계속 발생 -> 주기 사이클 고정 X ->그 정보를 나타냄 |
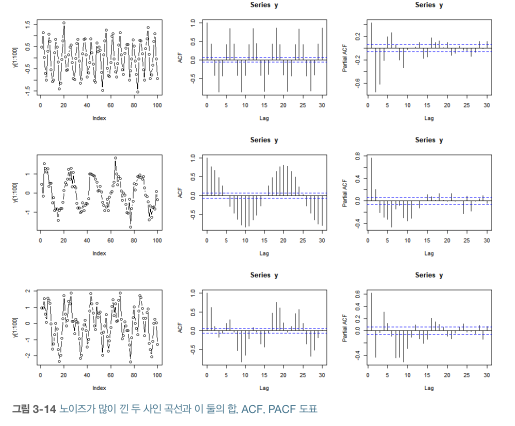
- 노이즈 추가


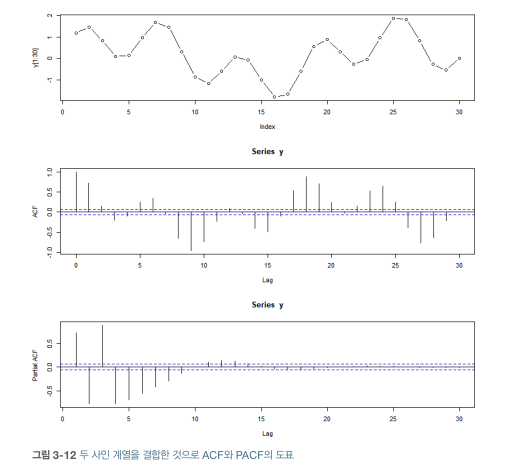
- 추세 가진 계열
- ACF는 유용한 정보 없음
- PACF는 특정 시점 직전 데이터 알고 있음 -> (계열 통틀어) 시점에 대해 얻을 수 있는 모든 정보 알고 있음
- 다음시점은 이전 시점에 1 더한 것(p.140)
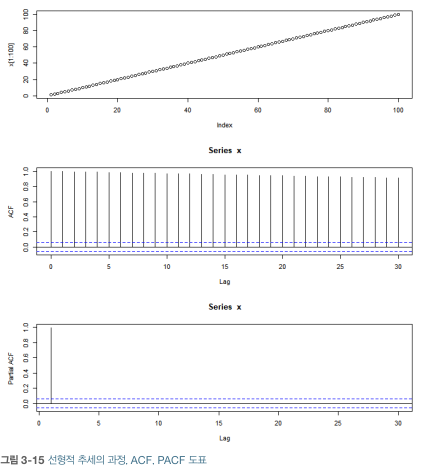
- 정리
- ACF 많은 임계값 가지는 이유 - 추세가 있음
- PACF 큰 시차에 대해 임계값 가지는 이유 - 데이터 추세가 있어도 식변 가능한 연간 계절적 주기
3.2.4 허위상관
- 근본적인 추세를 가진 데이터가 허위상관을 만들어낼 가능성이 높음
- 허위상관을 나타내는 시계열의 일반적인 특징
- 계절성 : 핫도그 소비와 여름 사이의 허위상관
- 시간이 지나면서 변한 데이터의 수준, 경사의 이동
- 누적 합계(일부 산업, 모델이나 상관관계를 실제보다 더 좋아보이게 만들기 위해 속임수로 사용)
공적분
- 정의 : 두 시계열 사이의 진짜 관계
- 허위상관) 어떤 관계도 없어도 됨. 공적분) 서로 밀접한 관련성 가짐
- 특별하고 강한 관계를 발견했다는 생각 = 분명한 원인이 무엇인지 데이터 점검하기
3.3 유용한 시각화
- 시계열 데이터의 EDA 핵심 : 그래프 (시간축에 대한 데이터 반드시 시각화해야 함)
- 일반적인 질문의 해답을 구할 수 있는 방향의 시각화
- 데이터의 종합적 시간 분포
- 특정 변수의 행동 방식
- 시계열 행동 방식에 대한 새로운 통찰 얻기 위한 시각화 기법
- 개별 기부자의 시간 분포도를 이해하기 위한 1차원 시각화
- 시간에 따른 여러 측정치의 전형적인 궤적 이해 위한 2차원 히스토그램(오랜 세월에 걸친 측정, 동일한 현상 측정 시계열)
- 두 개의 차원을 차지하는 시간, 차원을 전혀 차지하지 않지만 내재된 시간에 대한 3차원 시각화
3.3.1 1차원 시각화
- 여러 사용자 등 여러 측정의 구성 단위의 경우 여러 시계열 동시에 고려해야 함
- 시각적으로 누적하여 시간에 따른 개별 분석 단위 강조
- 특정 범위의 데이터 존재 유무가 관심있는 정보 (기간이 분석 단위)
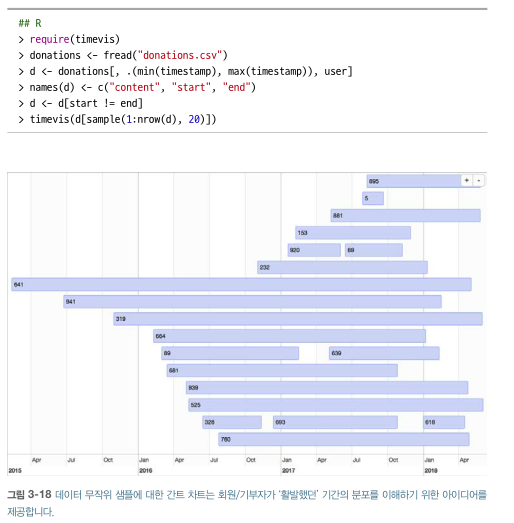
=> 간트 차트( 시간 경과에 따른 프로젝트 계획을 시각화) 그리기
- 특징
- 한 눈에 직관적으로 이해 가능한 시각화
- 하나 이상 측정된 과정을 위한시계열 분석에 사용
- 예) 전체 회원을 대상으로 붐비는 시기를 보여줌
- R과 Python 활용
- R은 timevis를 활용
- Python은 ploty내 timeline 함수
06-05 Gantt Charts
Gantt Chart 시간 경과에 따른 프로젝트 계획을 시각화하는방법으로 어떤 작업이 언제, 누구에 의해 완료될 예정인지 보여줍니다 Plotly를 활용하여 Gantt Ch…
wikidocs.net
3.3.2 2차원 시각화
- 시간이 1개 이상의 축에서 나타남
- 선형적 행동 << 계절적인 행동방식을 알고 싶음
1) 곡선
- 예시
- 년도별 월별 수
- X축 : 모든 연도가 공유하는 달, Y축 : 항공 여객수, 선 : 년도별
- 특정 월에 대한 최고치 알 수 있음
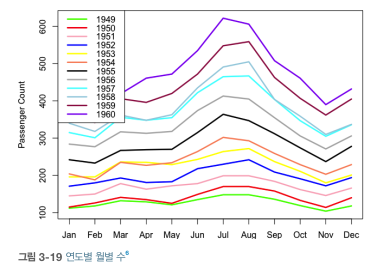
- 연도별 월별
- 년도에 따라 성장 추세가 가속화
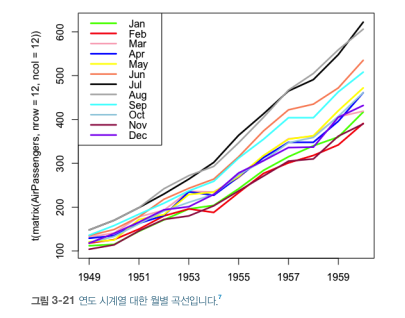
- 알 수 있는 점
- (그리고자 하는 도표) 하나 이상의 유용한 시간축이 있음
- 월(1~12월) + 년도(1949~1960년)
- (선형적 도표보다) 시계열 데이터 누적이 많은 유용한 정보, 예측 세부사항 얻음
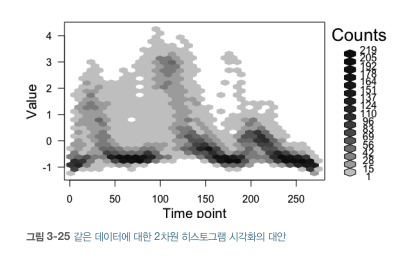
2) 히스토그램
- 구성 : 시간 + 관심단위
- 유용하게 변경
- 데이터 구간 나누기(시간축, 탑승객 수)
- 더 많은 데이터 필요

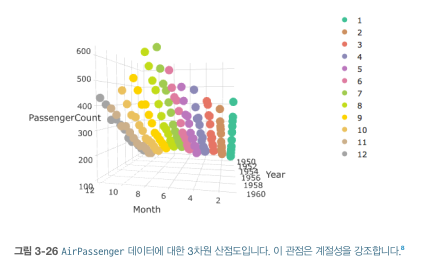
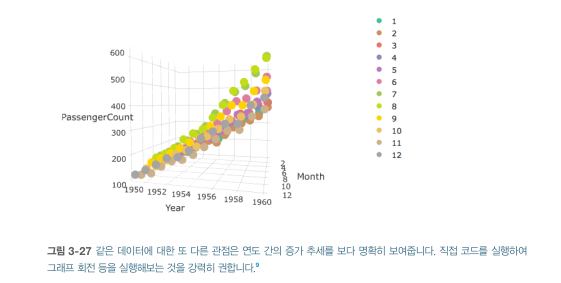
3.3.3 3차원 시각화
- 3차원 시각화 장점
- 데이터의 전체적인 윤곽 이해에 도움
- 소량의 데이터는 2차원보다 3차원이 이해하기 쉬움
- interaction 가능(회전)
- 3차원 구성 예) 월(시간) + 년도(시간) + 데이터값
✔️참고문헌
실전 시계열 분석 | 에일린 닐슨 - 교보문고
실전 시계열 분석 | 시계열 분석의 모든 것 실제 환경에 특화된 시계열 데이터 분석 및 모범 사례를 다루는 실무 지침서다. ARIMA 및 베이즈 상태 공간 같은 표준적인 통계 모델과 계층형 모델을
product.kyobobook.co.kr
'Data > 시계열 분석' 카테고리의 다른 글
| [시계열 분석] Ch.4 정리 (0) | 2024.03.28 |
|---|---|
| [시계열 분석] 1장-2장 정리 (0) | 2024.02.15 |
