추천시스템
[추천시스템] 컨텐츠 기반 필터링(Content-Based Filtering)
syunze
2024. 3. 28. 16:16
📌목차
1. 컨텐츠 기반 필터링 vs 협업 필터링
2. 장단점
3. 구현 절차
4. 관련 코드
✔️ 컨텐츠 기반 필터링 vs 협업 필터링

- 컨텐츠 기반 필터링(아이템 기반) : 고객이 시청했던 컨텐츠와 유사한 컨텐츠 추천
- 협업 필터링(고객 기반) : 같은 컨텐츠를 소비한 고객이 유사하다고 가정, 서로 시청했던 컨텐츠를 추천
✔️ 컨텐츠 기반 필터링 장단점
| 장점 | 단점 |
|
|
* Cold Start : 새로운 컨텐츠 및 유저의 데이터가 충분하지 않아 적합한 추천을 해주지 못하는 것
✔️ 컨텐츠 기반 필터링 구현절차
1. Feature 추출
- 아이템 특성 추출
- 수치형 : 상품의 특징 담은 tabular Feature
- 텍스트 : TF-IDF (BoW 개선 지표)
2. 사용자 프로필 정보 생성
- 유저가 상호작용한 아이템 특징 집계(평균, 합 등)
- 유저의 선호도 역할
3. 유사도 계산
- 아이템 - 사용자 프로필 벡터 유사도 계산
- 유사도 계산
4. 랭킹
- 유사도 스코어에 따른 순위 → 상위 아이템 추천
❓BoW와 TF- IDF란?
1. BoW(Bag of Words)
- 정의 : 단어의 순서는 고려하지 않고, 단어의 출현 빈도 나타내는 방법
- 문제점 : 단어 많으면 피쳐수 많아짐 → 연산효율 떨어짐, 단어 간 의미 관계 포착 불가, 불용어 문제

2. TF - IDF
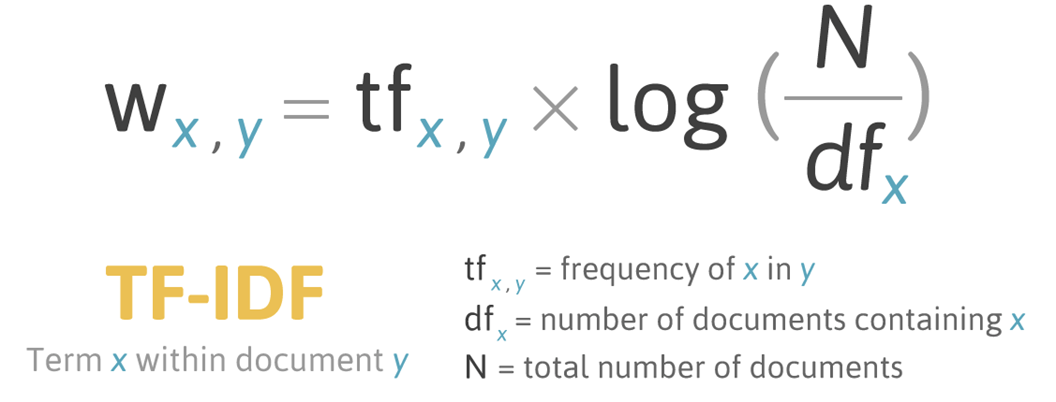
- 정의 : 문장내 중요도 반영하여 나타내는 방법
- TF(Term Trequency) : 문장 내 자주 등장하는 단어 중요
- IDF(Inverse Document Frequency) : 여러 문장에 걸쳐 자주 등장하는 단어는 안 중요하다. 자주 등장하는 단어는 제외!(불용어 간주 가능). 알종의 패널티 역할
❓유사도란?
- 정의 : 두 데이터가 얼마나 같은지 나타내는 척도
- 종류
1) 코사인 유사도
- 두 벡터간의 코사인 각도 활용하여 구할 수 있는 유사도
- 문서의 경우, 각각의 문서 단어 행렬 or TF-IDF 행렬이 특징벡터 A, B
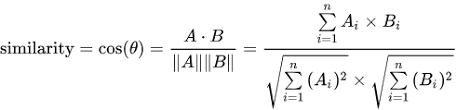
2) 유클리드 거리
- 좌표에 있는 두 점 사이의 거리 계산
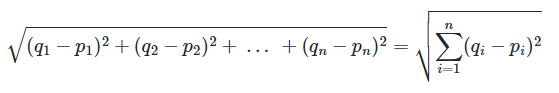
3) 피어슨 상관계수
- 상관관계가 높을 수록, 두 값은 연관있음

✔️ 관련 코드
(수정 중)
728x90